
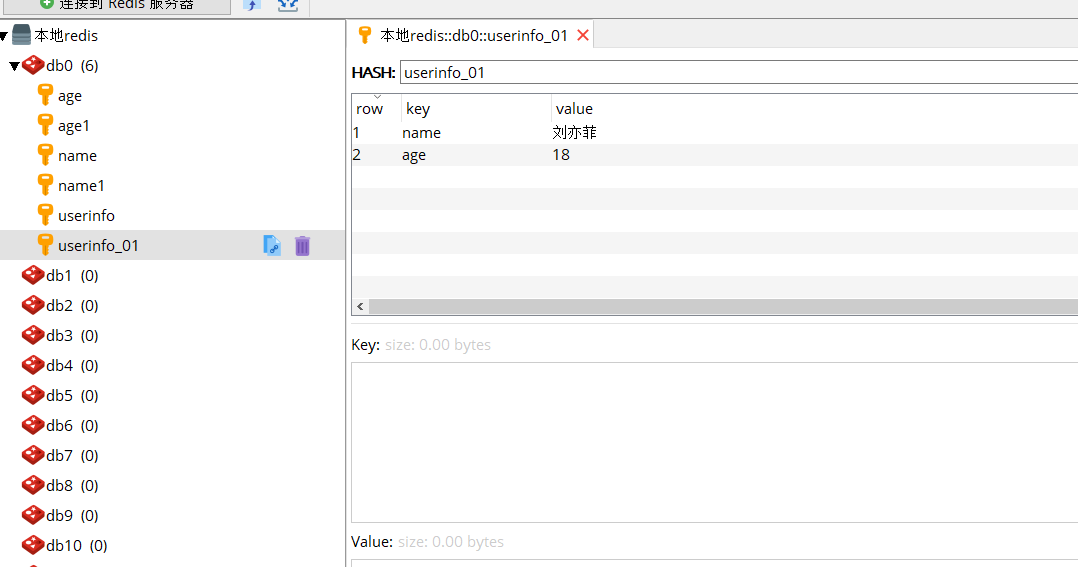
# 安装模块: pip install redis # django中有没有连接池? 没有,django中一个请求就会创建一个mysql连接,django并发量不高,mysql能撑住 想在django中使用连接池,有第三方: https://www.cnblogs.com/wangruixing/p/13030755.html # python实现单例的5种方式 http://liuqingzheng.top/python/%E9%9D%A2%E5%90%91%E5%AF%B9%E8%B1%A1%E9%AB%98%E9%98%B6/19-%E9%9D%A2%E5%90%91%E5%AF%B9%E8%B1%A1%E9%AB%98%E7%BA%A7%E5%AE%9E%E6%88%98%E4%B9%8B%E5%8D%95%E4%BE%8B%E6%A8%A1%E5%BC%8F/ from redis import Redis # 1 普通连接 conn = Redis(host="localhost", port=6379, db=0, password=None) conn.set('name', "lqz") # 创建值 res = conn.get('name') print(res) # b'lqz' # 2 连接池连接(以模块导入的方式实现单例) 创建文件redis_pool.py: import redis # 第一步:先要构造一个池 # POOL必须是单例的,全局只有一个实例,无论程序怎么执行,POOL是同一个对象 POOL = redis.ConnectionPool(max_connections=10, host="localhost", port=6379) -------------------------------------------------------------------------------------------------------------- import redis from redis_pool import POOL # 第二步:从池中拿一个连接 conn = redis.Redis(connection_pool=POOL) print(conn.get('name')) # 3 多线程演示 from threading import Thread import redis import time from redis_pool import POOL # 真报错吗?不会报错, def get_name(): conn = redis.Redis(connection_pool=POOL) print(conn.get('name')) for i in range(10): t = Thread(target=get_name) t.start() time.sleep(2) ''' 1 咱们这个py作为脚本运行,不能使用相对导入 2 只能使用绝对导入 3 从环境变量中开始到导起 4 在pycharm中右键运行的脚本所在的目录,就会被加入到环境变量 ''' # 各种锁知识:https://zhuanlan.zhihu.com/p/489305763 ''' 1 set(name, value, ex=None, px=None, nx=False, xx=False) ex,过期时间(秒) px,过期时间(毫秒) nx,如果设置为True,则只有name不存在时,当前set操作才执行,值存在,就修改不了,执行没效果 xx,如果设置为True,则只有name存在时,当前set操作才执行,值存在才能修改,值不存在,不会设置新值 2 setnx(name, value) 2 setex(name, value, time) 3 psetex(name, time_ms, value) 4 mset(*args, **kwargs) 5 get(name) 5 mget(keys, *args) 6 getset(name, value) 7 getrange(key, start, end) 8 setrange(name, offset, value) 9 setbit(name, offset, value) 10 getbit(name, offset) 11 bitcount(key, start=None, end=None) 12 bitop(operation, dest, *keys) 13 strlen(name) 14 incr(self, name, amount=1) 15 incrbyfloat(self, name, amount=1.0) 16 decr(self, name, amount=1) 17 append(key, value) ''' import redis conn = redis.Redis() # 1 set(name, value, ex=None, px=None, nx=False, xx=False) conn.set('age', 19) """ ex,过期时间(秒)---->过期时间 conn.set('age', 19, ex=3) px,过期时间(毫秒) ---->过期时间 nx,如果设置为True,则只有name不存在时,当前set操作才执行, 值存在,就修改不了,执行没效果 conn.set('wife','dlrb',nx=True) xx,如果设置为True,则只有name存在时,当前set操作才执行,值存在才能修改,值不存在,不会设置新值 conn.set('wife','dlrb',xx=True) """ # 2 setnx(name, value)--->等同于conn.set('wife','dlrb',nx=True) # 2 setex(name, value, time)--->conn.set('wife','lyf',ex=3) # 3 psetex(name, time_ms, value)--->conn.set('wife','lyf', px=3) # 4 mset(*args, **kwargs)--》批量设置 # conn.mset({'name1': 'pyy', 'age1': 20}) # 5 get(name) 拿单个值 print(conn.get('age1')) # 5 mget(keys, *args) 拿多个值 print(conn.mget(['age1', 'age'])) print(conn.mget('name', 'age', 'age1')) # 6 getset(name, value) print(conn.getset('name', 'dsb')) # 获取值之后更改值 # 7 getrange(key, start, end) print(conn.getrange('name', 0, 1)) # 取字节 ,前闭后闭 # 8 setrange(name, offset, value) 从指定位置开始更改 conn.setrange('name', 1, 'qqq') # dsb--->dqqq # 9 setbit(name, offset, value) ---》后面再聊---》独立用户统计---》用户量过亿---》日活 conn.setbit('name', 1, 0) # 改的是比特位,d 一个byte占8个比特位--》2进制---》10进制---》字符 # 10 getbit(name, offset) print(conn.getbit('name', 1)) # 11 bitcount(key, start=None, end=None) 统计多少比特位 print(conn.bitcount('name', 0, 1)) # 数字指的是字节,不是比特位 # 12 strlen(name) 统计字符长度 # 字节(一个byte)和字符(中 ? a 都是一个字符) # 面试题:mysql中utf8和utf8mb4有什么区别? # utf8---》不是咱们所知的utf-8,而是 mysql自己的,两个字节表示一个字符---》生僻字,表情存不了 # utf8mb4--》等同于常识的utf-8,最多4个字节表示一个字符---》存表情,存生僻字都可以 print(conn.strlen('name')) # 字节--》9--》gbk编码一个中文占2个字节 # utf-8编码 大部分一个中文占3个字节,生僻字可能占4 # 13 incr(self, name, amount=1)--->做计数器--》记录博客访问量--》博客表的文章上加个访问量字段,一旦有一个人访问,数字+1 conn.incr('age') # 不存在并发安全的问题---》redis6.0之前是单线程架构,并发访问操作,实际只排着队一个个来 # 14 incrbyfloat(self, name, amount=1.0) # 15 decr(self, name, amount=1) 减值 conn.decr('age') # 16 append(key, value) 增加值 conn.append('name', 'nb') # 记住:get set strlen ''' 1 hset(name, key, value) 2 hmset(name, mapping) 3 hget(name,key) 4 hmget(name, keys, *args) 5 hgetall(name) 6 hlen(name) 7 hkeys(name) 8 hvals(name) 9 hexists(name, key) 10 hdel(name,*keys) 11 hincrby(name, key, amount=1) 12 hincrbyfloat(name, key, amount=1.0) 13 hscan(name, cursor=0, match=None, count=None) 14 hscan_iter(name, match=None, count=None) ''' import redis conn = redis.Redis() # 1 hset(name, key, value) 设置值 conn.hset("userinfo", 'name', '彭于晏') conn.hset("userinfo_01", mapping={'name': "刘亦菲", 'age': 18}) # 2 hmset(name, mapping)---》弃用了-->直接使用hset即可 # conn.hmset("userinfo_02", mapping={'name': "刘亦菲", 'age': 18}) # 3 hget(name,key) 获取值 print(str(conn.hget('userinfo_01', 'name'), encoding='utf-8')) print(str(conn.hget('userinfo_01', 'age'), encoding='utf-8')) # 4 hmget(name, keys, *args) 批量获取值 print(conn.hmget('userinfo_01', ['name', 'age'])) print(conn.hmget('userinfo_01', 'name', 'age')) # 5 hgetall(name)--->慎用,有可能数据量很大,会撑爆内存-->一般我们redis服务器使用内存很大的服务器,应用服务器内存小一些 print(conn.hgetall('userinfo_01')) # 6 hlen(name) 统计长度 print(conn.hlen('userinfo_01')) # 2 # 7 hkeys(name) 取出所有key print(conn.hkeys('userinfo_01')) # [b'name', b'age'] # 8 hvals(name) 取出所有v值 print(conn.hvals('userinfo_01')) # [b'xe5x88x98xe4xbaxa6xe8x8fxb2', b'18'] # 9 hexists(name, key) 判断k值是否存在 print(conn.hexists('userinfo_01', 'name')) print(conn.hexists('userinfo_01', 'height')) # 10 hdel(name,*keys) 删除k值 conn.hdel('userinfo_01', 'name') # 11 hincrby(name, key, amount=1) 增加某字段值 不写数字默认增1 conn.hincrby('userinfo_01', 'age') # 12 hincrbyfloat(name, key, amount=1.0) # 13 hscan(name, cursor=0, match=None, count=None) hash类型无序----》但python 字典在3.6以后有序了,如何实现的? # for i in range(1000): # 创造数据 # conn.hset('hash_test', 'id_%s' % i, '鸡蛋%s号' % i) # 分批获取,但是由于没有顺序,返回一个cursor,下次基于这个cursor再继续获取 res = conn.hscan('hash_test', 0, count=20) print(res) res = conn.hscan('hash_test', 352, count=20) print(res) print(len(res[1])) # 因为hgetall不安全,有可能数据量过大,所以尽量使用以下---迭代取值 # 14 hscan_iter(name, match=None, count=None) # 想全取出所有值,通过分批取处理,不是一次性全取回来,减小内存占用 res = conn.hscan_iter('hash_test', count=10) # generator # print(res) for item in res: print(item) # print(conn.hgetall('hash_test')) # 一次全部取出 占用内存较大 # 重要:hset hget hlen hexists 
''' 1 lpush(name,values) 2 lpushx(name,value) 3 llen(name) 4 linsert(name, where, refvalue, value)) 4 r.lset(name, index, value) 5 r.lrem(name, value, num) 6 lpop(name) 7 lindex(name, index) 8 lrange(name, start, end) 9 ltrim(name, start, end) 10 rpoplpush(src, dst) 11 blpop(keys, timeout) 12 brpoplpush(src, dst, timeout=0) ''' import redis conn = redis.Redis() # 1 lpush(name,values) conn.lpush('girls', 'lyf', 'dlrb') # 图形界面看到的 上面是左, 下面是右 conn.rpush('girls', '杨颖') # 2 lpushx(name,value) 在name对应的list中添加元素,只有name已经存在时,值添加到列表的最左边(上面) conn.lpushx('girls', '杨颖1') conn.lpushx('girl', '杨颖1') # 3 llen(name) 统计字段长度 print(conn.llen('girls')) # 4 linsert(name, where, refvalue, value)) 从指定位置插入值 conn.linsert('girls', 'before', 'lyf', '张杰') # 之前 conn.linsert('girls', 'after', 'lyf', 'lqz') # 之后 # 4 r.lset(name, index, value) 对name对应的list中的某一个索引位置重新赋值 conn.lset('girls', 1, 'lqz') # 5 r.lrem(name, count,value) conn.lrem('girls', 1, 'lqz') # 从左侧删第一个 conn.lrem('girls', -1, 'lqz') # 从右侧删第一个 conn.lrem('girls', 0, 'lqz') # 全删 # 6 lpop(name) 从左边(上面)弹出值 res = conn.lpop('girls') print(res) r = b'xe6x9dxa8xe9xa2x961' print(str(r, encoding='utf-8')) # 7 lindex(name, index) 按元素的索引值取出值 print(conn.lindex('girls', 1)) # 8 lrange(name, start, end) 取出某个位置到某个位置的值 print(conn.lrange('girls', 0, 1)) # 前闭后闭 # 9 ltrim(name, start, end) ---》修剪,只保留起始到终止的值 库中多余值删除 conn.ltrim('girls', 1, 2) # 10 rpoplpush(src, dst) # 从第一个列表的右侧弹出,放入第二个列表的左侧 # 11 blpop(keys, timeout) # 阻塞式弹出--》可以做消息队列 -->block-->如果没有值,会一直阻塞 # 作用,可以实现分布式的系统---》分布式爬虫 # 爬网页,解析数据,存入数据库一条龙,一个程序做 # 写一个程序,专门爬网页---》中间通过redis的列表做中转 # 再写一个程序专门解析网页存入数据库 print(conn.blpop('girls', timeout=1)) # timeout=1 几秒后没有值就报错 # 12 brpoplpush(src, dst, timeout=0) print(conn.brpoplpush('girls', 1)) 从指定索引阻塞式弹出 # 重点:lpush lpop linsert llen blpop ''' delete(*names) exists(name) keys(pattern='*') expire(name ,time) rename(src, dst) move(name, db)) randomkey() type(name) ''' import redis conn = redis.Redis() # 1 delete(*names) 删除k对应数据或者整个表 conn.delete('name','name1','hash1') # 2 exists(name) 判断k值是否存在 print(conn.delete('name')) print(conn.delete('age')) # 3 keys(pattern='*') # 打印所有key * 和 ? print(conn.keys()) print(conn.keys('us*')) print(conn.keys('age?')) # 4 expire(name, time) 设置过期时间 conn.expire('age', 3) # 5 rename(src, dst) 给表重命名 conn.rename('wife', 'girl') # 6 move(name, db)) 将表移到某个库中 conn.move('girl', 3) # 7 randomkey() # 随机返回一个key print(conn.randomkey()) # 8 type(name) 查看表类型 print(conn.type('age1')) print(conn.type('userinfo')) # 管道---》 redis本身是不支持事务的 有的时候我们要实现类似这种功能:张三-100块钱,李四+100块钱 通过管道实现--->把多次操作的命令放到一个管道中,一次性执行,要么都执行了,要么都不执行 # 通过管道可以实现事务 import redis pool = redis.ConnectionPool() conn = redis.Redis(connection_pool=pool) pipe = conn.pipeline(transaction=True) pipe.multi() # 以后用pipe代替conn操作 pipe.set('name', 'lqz') # raise Exception('asdfasdf') pipe.set('role', 'nb') # 只是往管道中放了命令,还没执行 pipe.execute() # 一次性执行多条命令 # 方式一:自己写 使用连接池 创建 pool.py: import redis POOL = redis.ConnectionPool(max_connections=10, host="localhost", port=6379) 任意位置使用 class TestView(APIView): def get(self, requeste): conn=redis.Redis(connection_pool=POOL) print(conn.get('name')) return Response('ok') # 方式二:使用第三方 djagno-redis 安装:pip install django-redis 在项目配置文件中: # redis的配置 CACHES = { "default": { "BACKEND": "django_redis.cache.RedisCache", "LOCATION": "redis://127.0.0.1:6379", "OPTIONS": { "CLIENT_CLASS": "django_redis.client.DefaultClient", "CONNECTION_POOL_KWARGS": {"max_connections": 100} # "PASSWORD": "123", } } } 使用位置: from django_redis import get_redis_connection conn=get_redis_connection() print(conn.get('name')) # 一旦这么配置了,以后django的缓存也缓存到reids中了 cache.set('asdfasd','asdfas') # 以后在django中,不用使用redis拿连接操作了,直接用cache做就可以了 # 不需要关注设置的值类型是什么 cache.set('wife',['dlrb','lyf']) # value值可以放任意数据类型 # 底层原理,把value通过pickle转成二进制,以redis字符串的形式存到了redis中 # pickle是python独有的序列化和反序列化,只能python玩,把python中所有数据类型都能转成二进制 通过二进制可以在反序列化成功pyhton中的任意对象 评论已关闭。




![洛谷 P11345 [KTSC 2023 R2] 基地简化 题解](http://www.itfaba.com/wp-content/themes/kemi/timthumb.php?src=http://www.itfaba.com/wp-content/themes/kemi/img/random/1.jpg&w=218&h=124&zc=1)
