

2022年4月12日,在CSDN云原生系列在线峰会第1期“SRE与智能运维峰会”上,阿里云高级技术专家、神龙计算平台异常调度平台负责人周宇分享了神龙计算平台的智能运维体系建设实践。
要点简述
云计算基础设施规模决定了其运维复杂度,当前没有现成的体系和产品可以借鉴或复用,需要探索出自己的道路。
系统级异常自动修复,如Python解释器异常、系统磁盘满、采集脚本残留等;本地无法修复异常上报诊断运维闭环,如磁盘只读、硬件损坏等。
在杂乱的异常事件中,通过优先级和知识图谱构建,找到异常根因。之前主要靠专家规则找到根因,目前根因分析作为客户及售后团队定位客户问题的入口。
业界大概 70%的生产事故由变更而触发,集团全部故障中60%+与变更相关。神龙计算平台针对不同发布,灵活定制Stage、Canary不同阶段,能够极大提升发布稳定性,另外不同业务有不同的发布前置需求(如特定机型、集群、依赖版本等)。
背景与目标
阿里云神龙计算平台作为一个致力于保障百万级客户稳定性的平台,赋能了云原生时代下大体量业务运维的场景。当前,其所构建的智能运维体系具备了采集、智能诊断和自动化运维三大核心能力。
阿里云计算的基础设施规模已经达到了26个数据中心区域、83个可用区,以及数千个网络和 CDN 节点。地域上已经覆盖了六大洲,拥有上千个集群。由于云计算基础设施规模之大,其运维的复杂度极高,目前尚未有成熟的体系或产品以供借鉴。
从稳定性角度来讲,云上产品的需求层次可由下图的金字塔模型表示。稳定可靠是客户最基本的关注点,作为上云客户,其要求用云场景具有稳定且较高性能的 SLA ;同样,客户通常希望所遇到的问题可以找到根源,进而诊断;而对于一些头部客户,由于他们的业务规模庞大,对于批量自动化操作的诉求不可避免,所以云上产品的可控性和可操作性也备受关注。
基于对客户需求的分析,极致的云运维场景即是在集成基础能力的同时,构建批量操作能力,进而通过编排而形成的一套无人值守的自动化运维体系。
在此背景下,神龙计算平台是如何支撑百万级客户的呢?又是如何在大规模体量增长中建设与迭代的呢?下面将把这套方案分享给大家。
可观测性产品
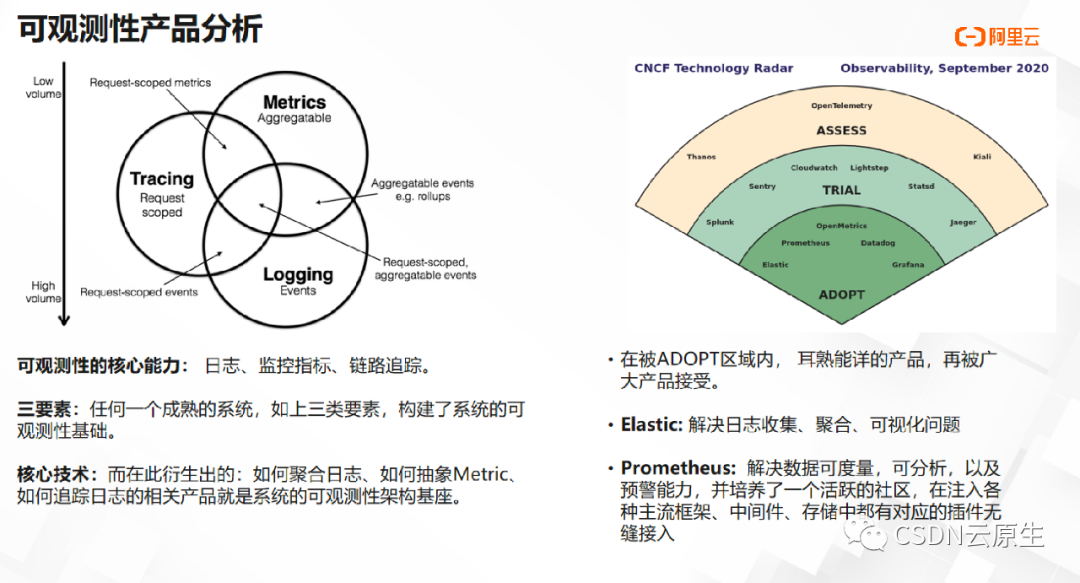
首先,我们需要了解可观测性产品的概念。如下图所示,可观测性产品分析的本质就是在数据可追溯的基础上形成对应的 Metrics,而其核心就是在每两个圆之间都有相应的诉求,比如日志和 Tracing 之间的关系,以及 Tracing 如何聚合成一个 Metrics。
上图右侧是 2020 年度的可观测雷达,其下层是被业界广泛接受的可观测产品,包括 Elastic 系列产品、ERK 系列产品和 Prometheus 系列产品等。
数据采集
在业务平台上,基于上述可观测性产品,神龙计算平台面临了一些挑战,例如当采集节点到达千万级规模的时候,无论是商用产品还是社区类产品,大家都会发现,很难拿过来直接借鉴或者使用。
下面分享四个例子:
第一类是资源,在很多场景下,我们控制的资源是非常有限的。在这样非常有限的场景下,如何最大限度地把采集做到极致,这个时候无论是用社区还是自己的,都是要去把它的性能调到极致。当上到一定规模的时候,我们发现线上代码一定必须是非常可控的,如果上了一个采集或者服务的时候,这个服务对整机造成了伤害,那么就需要在分钟级去做回滚以及分钟级的感知并且切断的。所以神龙运维平台本质上是提供了一套严格的流程。
第二类是一个准生产环境的测试,包括自发的测试、最终上线的灰度能力、熔断能力,这些东西都是需要严格把控的。在发布过程中,需要有一个可观测的系统,及时发现线上的所有问题或者潜在的问题,需要做及时的熔断或者切断处理。这个实际上是一个很大的痛点。
第三类是可降级,一定要有止损的功能。例如配置和采集要做解耦,因为只有解耦以后,当发现问题的时候,才能做到快速的降级。现有的系统,比如说一个采集节点,可能对线上几百或者几千的物理机造成了损害时,需要快速止损,所以服务可降级是一个非常重要的点。
第四类是自动修复,在大规模的场景去部署的时候,几乎很难做到 4 个 9 的覆盖度,这就意味着在 1 万台物理机的时候,只允许有一台机器是部署失败的,或者说是有问题的。
监控诊断
监控诊断的整个体系也是利用前文提到的可观测作业产品中的日志服务等模块。
监控诊断平台首先需要有一套可靠的底座,即数据收集、日志服务。其次就是需要一套在线的和离线的数据分析平台。
变更&熔断
业界大概 70% 的生产事故是因为变更引起的,所以神龙的运维平台做了一套智能的编排熔断以及止损系统。
神龙平台支撑了百万级资源的发布,累计变更次数过亿,2021 年该系统的业务方达到了数百个,支持了过亿次的变更。
案例:日志聚类分析
由上图可知,日志的数据源可能有几百个,每天可以达到百T级别。由于业务方太多,可能有几百个业务线,我们没有办法了解各个业务线,所以需要有一套方法论,即把日志生成一个 log even 或者是 log template。
针对云原生场景的稳定性方案
阿里云容器产品的核心是 Container Service for Kubernetes(ACK)和 Serverless Kubernetes(ASK),它们构建在具备计算、存储、网络和安全等能力的阿里云基础设施之上,提供标准化的接口、优化的能力和简化的用户体验。
利用底层事件体系和 GuestOS 的能力,能够快速发现 Node 运行过程中的问题,结合诊断和运维,快速定位根因,解决问题,提高 K8s的 Node 节点的稳定性。
基于Node Conditions 这套通用的框架主动去规避,比如热迁移、冷迁移或者强制重启去主动修复现有的 Node ,进而将其赋能到整个云原生场景。
评论已关闭。




![洛谷 P11345 [KTSC 2023 R2] 基地简化 题解](http://www.itfaba.com/wp-content/themes/kemi/timthumb.php?src=http://www.itfaba.com/wp-content/themes/kemi/img/random/3.jpg&w=218&h=124&zc=1)
