
在了解一些概念之前一直看不懂上交22年开源的TRTModule.cpp和.hpp,好在交爷写的足够模块化,可以配好环境开箱即用,移植很简单。最近稍微了解了神经网络的一些概念,又看了TensorRT的一些api,遂试着部署一下自己在MNIST手写数字数据集上训练的一个LeNet模型,识别率大概有98.9%,实现用pytorch从.pt转成了.onnx
1. 模型加载
使用TensorRt加载onnx模型的步骤其实是很固定的,根据官方例呈给出的示范,加载一个onnx的模型分为以下几步
- 创建builder(构建器)
- 创建网络定义:builder —> network
- 配置参数:builder —> config
- 生成engine:builder —> engine (network, config)
- 序列化保存:engine —> serialize
- 释放资源:delete
- 第一步是使用TensorRT的api来声明一个构建器类型。
#include <cuda.h> #include <cuda_runtime_api.h> #include <logger.h> #include <NvOnnxParser.h> nvinfer1::IBuilder *builder = nvinfer1::createInferBuilder(sample::gLogger); 构建器初始化参数需要传入一个gLogger对象,用于构建时的日志存储与打印。
- 接着使用构建器创建计算图网络,也就是先创建一个空网络。创建时我们要指定显式batchsize的大小,一般在部署环节的batchsize都设置为1。
const auto explicitBatch = 1U << static_cast<uint32_t>(nvinfer1::NetworkDefinitionCreationFlag::kEXPLICIT_BATCH); nvinfer1::INetworkDefinition *network = builder->createNetworkV2(explicitBatch); 虽然第一行代码很长,但是实际上这只是TensorRT官方给出的一个静态对象变量,值为0,因此explicitBatch相当于1 << 0 = 1,因此这里相当于
const auto explicitBatch = 1U; nvinfer1::INetworkDefinition *network = builder->createNetworkV2(explicitBatch); - 接着我们来创建一个onnx的解析器来对onnx模型进行解析。
auto parser = nvonnxparser::createParser(*network, sample::gLogger); parser->parseFromFile(onnx_file.c_str(), static_cast<int>(nvinfer1::ILogger::Severity::kINFO)); 其中parserFromFile的第一个参数是读取到的onnx文件的地址,可以这样获取
string onnx_file = "./MNIST.onnx"; onnx_file.c_str(); - 接着我们来创建一个config对象,对网络的一些参数进行设置
auto config = builder->createBuilderConfig(); if (builder->platformHasFastFp16()) config->setFlag(nvinfer1::BuilderFlag::kFP16); // 若设备支持FP16推理,则使用FP16模式 size_t free, total; cudaMemGetInfo(&free, &total); // 获取设备显存信息 config->setMaxWorkspaceSize(free); // 将所有空余显存用于推理 其中必须设置的只有setMaxWorkspaceSize这一项。
为了在后面获取输入输出时能知晓输入输出的shape,这里为输入输出绑定名称
network->getInput(0)->setName("input"); network->getOutput(0)->setName("output"); getInput的参数0代表输入的张量索引,因为我们的输入输出都只有一个张量,因此填索引0即可。
- 最后创建TensorRT最关键的用于推理的Engine(引擎)
auto engine = builder->buildEngineWithConfig(*network, *config); 至此,构建阶段就算完成了。至于engine的序列化为模型文件以及通过读取模型文件来加载engine这里线掠过。
- 最后,释放除了engine之外的对象或者说指针。不难发现TensorRT中数据的传递都是使用指针而非引用来实现的,不知道为啥。
delete config; delete parser; delete network; delete builder; //or config->destory(); parser->destory(); network->destory(); builder->destory(); 2. 推理阶段
在推理阶段要做的工作依然很多,好在这次部署的模型较为简单。推理阶段的工作主要分为以下几点。
- 对输入的数据(图像)进行预处理操作,使之符合网络的输入要求。
- 在GPU上申请需要的内存,并使用engine的context(上下文)成员进行推理
- 获取输出后对输出进行后处理(argmax,nms等),以获取有用的信息。
- 首先对于输入的图像,并不是直接就可以送进网络进行推理的,因为其格式可能不符合网络的要求,因此需要对其做一些变换以适配网络的输入格式。
可以使用Netron来查看onnx模型的网络结构,了解输入输出的格式。


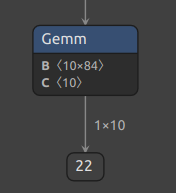
可以看出我要部署的网络的输入格式为1×1×32×32(b, c, h, w)的一个张量,输出为1×10的一个张量。因此对于输入图像的格式,必须为单通道,大小为32×32像素才可以输入到网络中。
这里选用opencv对图像进行读取,并将图像通过resize,转换为灰度图(单通道),然后进行归一化,从而使之符合网络的输入格式。
cv::Mat img = cv::imread("../five.png"); cv::cvtColor(img, img, cv::COLOR_BGR2GRAY); cv::resize(img, img, {32, 32}); img = ~img; img.convertTo(img, CV_32F); // 转换为浮点型 img /= 255; // 归一化 由于训练时的MNIST数据集中的图片为黑底白字的图像,而网图多为白底黑字,因此使用img = ~img来进行反色。可以根据实际场景进行调整。
实际上opencv的图片格式存储是(h , w, c),也就是(高, 宽, 通道数),而pytorch等主流框架都默认张量的输入格式为(c,h,w),上面对模型的查看也验证了,这一点。因此我们还需要将opencv的(h,w,c)格式转换为(c,h,w)格式。转换代码如下。
// 原始图像,尺寸为(h, w, c) void hwc2chw(cv::Mat &image) { int h = image.rows; int w = image.cols; int c = image.channels(); // 尺寸转换为(h*w, c, 1),此步骤不对内存进行修改 image = image.reshape(1, h * w); // 图像转置,尺寸变为(c, h*w, 1) image = image.t(); // 尺寸转换为(c, h, w),此步骤不对内存进行修改 image = image.reshape(w, c); } 引用于博客
- 接下来就是在cuda上申请内存,并在其中进行推理。
在申请内存之前,显然得先知道申请多少。再推理过程中,我们需要为输入以及输入各申请一块内存,因此需要统计输入输出的元素数量即可。
/*获取输入输出的idx进而获取其维度(dims)*/ auto input_idx = engine->getBindingIndex("input"); auto output_idx = engine->getBindingIndex("output"); auto input_dims = engine->getBindingDimensions(input_idx); auto output_dims = engine->getBindingDimensions(output_idx); int input_sz = 1, output_sz = 1; /*获取需要申请存放输入输出的显存大小,.nbDims返回维度数,d接口访问每一维度的成员个数*/ for (int i = 0; i < input_dims.nbDims; i++) input_sz *= input_dims.d[i]; for (int i = 0; i < output_dims.nbDims; i++) output_sz *= output_dims.d[i]; /*这样统计过后,input_sz和output_sz分别即为输入输出元素的大小,即需要申请内存的个数(float型)*/ 写完上面才知道shift+tab可以让代码块整体后退一个tab -_-
- 接着便是申请内存然后推理了。
申请内存
void *device_buffer[2]; // 设备内存 float *output_buffer; // 输出结果内存 cudaMalloc(&device_buffer[input_idx], input_sz * sizeof(float)); cudaMalloc(&device_buffer[output_idx], output_sz * sizeof(float)); output_buffer = new float[output_sz]; 顺便创建一个cuda流用于cuda自动管理异步的内存管理
cudaStream_t stream; cudaStreamCreate(&stream); 推理
auto context = engine->createExecutionContext(); // 创建context进行推理 cudaMemcpyAsync(device_buffer[input_idx], img.data, input_sz * sizeof(float), cudaMemcpyHostToDevice, stream); // 将预处理好的数据拷贝到cuda内存上 context->enqueueV2(device_buffer, stream, nullptr);// 加入推理队列进行推理,推理结果也会存入device_buffer cudaMemcpyAsync(output_buffer, device_buffer[output_idx], output_sz * sizeof(float), cudaMemcpyDeviceToHost, stream);// 推理结束后将结果拷贝到本地的output_buffer中 cudaStreamSynchronize(stream); // 等待流同步,即阻塞,直到以上所有的操作完成 对于cudaMemcpyAsync(),这是一个异步的拷贝,会将数据拷贝到指定位置,决定是上传还是下载的是第四个参数,cudaMemcpyHostToDevice代表本地数据上传到cuda,而cudaMemcpyDeviceToHost代表cuda数据下载到本地。
- 最后便是对推理的数据进行后处理来获取有效信息。
上面通过使用Netron查看了该模型的输出张量维度为1×10,但是1×10张量的具体含义是训练时我们知道的由数据集的标签来指定的。因此在部署模型前一定要知道输出的每个部分代表什么意思,要不然就无法解析输出。
对于这里的MNIST数据集,其1×10的张量即0-9的数组中存储的是该张图片为该数字的概率程度,越大说明越接近该数字。因此对于每个输出,我们只需要找到1×10张量中最大的那个元素的下标,就是对应模型推理出的该图片上的数字。这个按某个维度寻找最大值下标的操作就称为argmax()。由于c++中我找不到现成的接口,就简单写了一个。
int argmax(float *output, int len) { float Max = -1; int Max_idx = -1; for (int i = 0; i < len; i++) (output[i] > Max ? Max = output[i], Max_idx = i : false); return Max_idx; } 通过argmax操作获取数字最大的成员的下标,即可认为该下标即为数字的类型。至此,整个模型的从构建到推理出结果就结束了。
最后别忘了将上面用到的内存以及engine释放
delete[] output_buffer; cudaFree(device_buffer[output_idx]); cudaFree(device_buffer[input_idx]); cudaStreamDestroy(stream); delete engine; or engine->destory(); 最后将整个代码贴上来
这里是代码
#include <opencv4/opencv2/opencv.hpp> #include <cuda.h> #include <cuda_runtime_api.h> #include <logger.h> #include "/home/ruby/Tensorrt/trt/include/NvInfer.h" #include <NvOnnxParser.h> #include <filesystem> #include <fstream> #include <iostream> const std::string onnx_file = "/home/ruby/Desktop/work/CV/C++Test/MNIST_TEST.onnx"; int argmax(float *output, int len) { float Max = -1; int Max_idx = -1; for (int i = 0; i < len; i++) (output[i] > Max ? Max = output[i], Max_idx = i : false); return Max_idx; } int main() { /*1. 构建 */ std::filesystem::path onnx_file_path(onnx_file); nvinfer1::IBuilder *builder = nvinfer1::createInferBuilder(sample::gLogger); const auto explicitBatch = 1U << static_cast<uint32_t>(nvinfer1::NetworkDefinitionCreationFlag::kEXPLICIT_BATCH); nvinfer1::INetworkDefinition *network = builder->createNetworkV2(explicitBatch); auto parser = nvonnxparser::createParser(*network, sample::gLogger); parser->parseFromFile(onnx_file.c_str(), static_cast<int>(nvinfer1::ILogger::Severity::kINFO)); network->getInput(0)->setName("input"); network->getOutput(0)->setName("output"); auto config = builder->createBuilderConfig(); if (builder->platformHasFastFp16()) config->setFlag(nvinfer1::BuilderFlag::kFP16); size_t free, total; cudaMemGetInfo(&free, &total); config->setMaxWorkspaceSize(free); auto engine = builder->buildEngineWithConfig(*network, *config); delete config; delete parser; delete network; delete builder; /*2. 数据预处理*/ cv::Mat img = cv::imread("../five.png"); cv::cvtColor(img, img, cv::COLOR_BGR2GRAY); cv::resize(img, img, {32, 32}); img = ~img; img.convertTo(img, CV_32F); img /= 255; /*3. 申请显存用于推理*/ auto input_idx = engine->getBindingIndex("input"); auto output_idx = engine->getBindingIndex("output"); auto input_dims = engine->getBindingDimensions(input_idx); auto output_dims = engine->getBindingDimensions(output_idx); int input_sz = 1, output_sz = 1; /*获取需要申请存放输入输出的显存大小,nbDims返回维度数,d接口访问每一维度的成员个数*/ for (int i = 0; i < input_dims.nbDims; i++) input_sz *= input_dims.d[i]; for (int i = 0; i < output_dims.nbDims; i++) output_sz *= output_dims.d[i]; void *device_buffer[2]; float *output_buffer; cudaMalloc(&device_buffer[input_idx], input_sz * sizeof(float)); cudaMalloc(&device_buffer[output_idx], output_sz * sizeof(float)); cudaStream_t stream; cudaStreamCreate(&stream); output_buffer = new float[output_sz]; /*4. 开始推理*/ auto context = engine->createExecutionContext(); cudaMemcpyAsync(device_buffer[input_idx], img.data, input_sz * sizeof(float), cudaMemcpyHostToDevice, stream); context->enqueueV2(device_buffer, stream, nullptr); cudaMemcpyAsync(output_buffer, device_buffer[output_idx], output_sz * sizeof(float), cudaMemcpyDeviceToHost, stream); cudaStreamSynchronize(stream); /* 后处理 */ int label = argmax(output_buffer, output_sz); std::cout << "预测为数字" << label << std::endl; delete[] output_buffer; cudaFree(device_buffer[output_idx]); cudaFree(device_buffer[input_idx]); cudaStreamDestroy(stream); delete engine; delete context; return 0; }
这里插一嘴,如果想在markdown中插入代码块的话,可以这样写
<details> <summary> 我是折叠标题 </summary> <code> //这里有空格 ```c++//在这里开始 ```//在这里结束 </code> </details> 补充,关于上交TRTModule
在上交开源的TRTModule.cpp中,也大致遵循了上述的流程来进行搭建和推理,但是由于装甲板检测使用的YOLO模型(好像是YOLOFACE),因此对图片的预处理以及后处理会有所不同,而且后处理操作由于要实现非极大值抑制,比较麻烦。
还有一点就是上交在网络的输出后又加了几个层来对输出进行在网络层面的后处理。
auto yolov5_output = network->getOutput(0); /*具体目标为将输出的置信度部分提取,并提取最大的topk个数作为输出*/ auto slice_layer = network->addSlice(*yolov5_output, Dims3{0, 0, 8}, Dims3{1, 15120, 1}, Dims3{1, 1, 1}); auto yolov5_conf = slice_layer->getOutput(0); /*reshape,(1,15120,1)->(1,15120)*/ auto shuffle_layer = network->addShuffle(*yolov5_conf); shuffle_layer->setReshapeDimensions(Dims2{1, 15120}); yolov5_conf = shuffle_layer->getOutput(0); /*topk,提取最大的前topk个元素*/ auto topk_layer = network->addTopK(*yolov5_conf, TopKOperation::kMAX, TOPK_NUM, 1 << 1); auto topk_idx = topk_layer->getOutput(1); /*通过topk层的索引来重塑张量*/ auto gather_layer = network->addGather(*yolov5_output, *topk_idx, 1); gather_layer->setNbElementWiseDims(1); auto yolov5_output_topk = gather_layer->getOutput(0); /*绑定输入输出,防止被优化掉*/ yolov5_output_topk->setName("output-topk"); network->getInput(0)->setName("input"); /*绑定新输出*/ network->markOutput(*yolov5_output_topk); /*解绑旧输出,解绑的张量会被当作暂时量被优化掉*/ network->unmarkOutput(*yolov5_output); 这里讲几个点。这几步找了好几天的资料才看懂。
第一步衔接的是刚构造完计算图(network),我们取获取网络的输出张量。然后接着在网络的后面添加了各种层
addslice,在网络后添加一个切片层,输入为上一步的输出也就是yolov5_output。参数传入的是三个维度,分别为起始位置,切片完后的shape,以及步长。这里意味着对于每个张量从第8位也就是第九个数据进行切片,步长为1。值得一提的是在上交的onnx模型中,第八位的输出是该张图片作为一个装甲板的置信度。因此此步操作就是将(1,15120,20)的张量中关于置信度的那一维度切片出来成为(1,15120,1)的张量
addshuffle,在网络后再添加一个shuffle层,相当于网络中做了一步reshape操作,从(1,15120,1)输出(1,15120)的二维张量。
addTopk,寻找沿着张量的某个维度的满足最条件的一些量。这里的传参使用
TopKOperation::kMAX也就是选择最大的前topk个元素,然后TOPK_NUM就是目标要找的前TOPK个数的多少,而最后一位,在注释中叫做reduceAxes,使用很奇怪的方式来指定在那个维度上进行topk操作。注释显示使用位掩码来指定,即当最后一个参数传入5(101)时,仅有第0维和第2维进行操作,而第1维不操作。因此这里传入1<<1(10)代表这仅对第1维进行操作,而不对第0维进行操作。这十分合理,因为对于(1×15120)的二维张量,第0维每个元素仅有一个元素,topk是没有意义的,而对于第1维的topk可以排出置信度前TOP_NUM大的样本。
接着对于topk层的输出,一个是第0维的输出
getOutput(0),输出的是前topk的值,而第1维的输出getOuput(1),输出的是前topk的输出的索引位置的张量。
这里只关心位置。因为我们提取置信度为前topk的张量的目的就是获取其索引然后通过索引去从(1,15120,20)->(1,NUM_TOPK,20)。从而减少要处理的样本量。而这通过索引重建数据的操作就交给了最后一个gather层。gather层通过提供的索引来聚集对应的张量。这样就实现了从索引到(1,NUM_TOPK,20)的实现。
最后将原先的输出解绑,绑定从最后的gather层的输出为整个网络的输出。
最后贴上上交的后处理过程,仅有注释,今天有点猪脑过载就不写解析了。不过还是值得提一嘴上交的输出20个元素中,0-7为四点,左上角开始/逆时针(x,y),8为置信度,9-12为四种颜色的可能(r,b,g,p),13-19为七种装甲板类型id。
// post-process [nms] std::vector<bbox_t> rst; rst.reserve(TOPK_NUM); std::vector<uint8_t> removed(TOPK_NUM); auto input_dims = engine->getBindingDimensions(input_idx); auto output_dims = engine->getBindingDimensions(output_idx); for (int i = 0; i < TOPK_NUM; i++) { auto *box_buffer = output_buffer + i * 20; // 20->23 /*第8位推断为是<装甲板>的置信度(未经过sigmoid归一化),而keep_thres为置信阈值,通过sigmoid的反函数来求出未经过sigmoid的置信度*/ /*两者相比较,筛掉置信度低于置信阈值的样本*/ if (box_buffer[8] < inv_sigmoid(KEEP_THRES)) break; /*判断*/ if (removed[i]) // 只处理没被romove的样本 continue; /*向rst中填入一个空成员*/ rst.emplace_back(); /*取出最后一个成员,也就是最后一个空成员*/ auto &box = rst.back(); /*将本轮循环样本的前8位数据传给box的pts,即像素四点,每点(x,y),四点为 4 * 2 = 8 个数据*/ memcpy(&box.pts, box_buffer, 8 * sizeof(float)); /*将四点按开头算的比例映射到原图像上*/ for (auto &pt : box.pts) pt.x *= fx, pt.y *= fy; /*读取buffer不同的数据段通过argmax来获取该装甲板的信息*/ box.confidence = sigmoid(box_buffer[8]); box.color_id = argmax(box_buffer + 9, 4); box.tag_id = argmax(box_buffer + 13, 7); /*通过计算IOU来进行非极大值抑制*/ /* * 可以注意到,由于我们检测装甲板的任务很简单,目标少,因此直接采用有交集就筛掉的原则,不再用传统NMS那一套 * 比如先对置信度排序,然后遍历该种类的所有box,计算IOU,筛掉IOU大于阈值或者置信度小于阈值的box */ for (int j = i + 1; j < TOPK_NUM; j++) // 遍历每一个样本 { auto *box2_buffer = output_buffer + j * 20; if (box2_buffer[8] < inv_sigmoid(KEEP_THRES)) // 过掉置信度小的样本 break; if (removed[j]) continue; if (is_overlap(box_buffer, box2_buffer)) // 如果有交集,直接将其remove removed[j] = true; } } return rst; 



