1. 性能指标曲线频繁出现大幅度抖动
如图7-5-1所示,TPS和平均响应时间出现频繁的上下抖动。频繁抖动说明系统并不是一直在稳定地运行,中间会有短暂的停顿,就是持续运行了一段时间后,马上会停顿一下,然后又继续运行,持续地这样交替进行,造成了系统的频繁剧烈抖动。




1. 性能指标曲线频繁出现大幅度抖动
如图7-5-1所示,TPS和平均响应时间出现频繁的上下抖动。频繁抖动说明系统并不是一直在稳定地运行,中间会有短暂的停顿,就是持续运行了一段时间后,马上会停顿一下,然后又继续运行,持续地这样交替进行,造成了系统的频繁剧烈抖动。
造成频繁抖动现象的原因可能有以下几种:(节选自《软件性能测试、分析与调优实践之路》(第2版),作者张永清,转载请注明出处)
(1)系统可能在频繁的出现Full GC。Full GC是Java 应用程序垃圾回收的一种机制,一般如果出现了Full GC,应用程序就会出现短暂的停顿。关于Full GC的介绍,可以参考本书5.1.7小节中的介绍。此时可以先去看一下应用程序的GC日志,如果是Full GC 非常频繁,并且又没有出现内存泄漏,那么可以参考本书5.4.1 小节中介绍的如何减少GC 来解决这个问题。
(2)系统某一次查询、修改或者删除数据耗时很长,导致了整体性能的不稳定。比如,在性能压测查询时,大部分参数化传入的参数,查询出来的结果数据都很少,但是可能某几个参数查询出来的数据量非常大,导致系统在处理这些数据量大的数据时耗时较长。
(3)系统在查询时,可能有时候能命中缓存,有时候命不中缓存。命中缓存时,查询会很快;不能命中缓存时,需要去查询数据库,但是查询数据库的时间肯定比缓存长,所以就会造成系统性能的不稳定。通常情况下数据库也会有缓存,如果命中了数据库的缓存,查询也会更快;如果没有命中,那查询的耗时肯定也会变久。
(4)如果系统是分布式部署,那么可以检查一下分布式处理系统中每个节点的处理能力是否一致,如果不一致,可能也会导致系统频繁抖动。
(5)服务器连接不够用导致的连接批量释放然后再突然批量连接,一旦批量释放连接后,系统TPS马上就会上涨,因为此时可以建立连接了。当连接满了后,请求就无法处理了,从而不得不等待,进而造成TPS突然下降。
2.在提高并发用户数时,系统的TPS和平均响应时间一直无法提升
如图7-5-2所示,当遇到这种情况时,说明系统已经出现了瓶颈,此时可以先去检查服务器的CPU、内存资源的消耗情况。
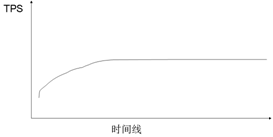

图7-5-2
通常,检查后会发现应用服务器的CPU、内存等资源都没有达到使用的上限,但是系统却出现了处理的瓶颈,那么说明系统一定是有地方“堵住了”。此时需要继续做如下检查:
(1)性能压测时,点击率是否真的上来了。如果点击率或者单位时间内的请求数没有上来,那说明是压测机器无法提供更大压测能力。尤其在大型的分布式系统中,单台压测机往往是不够用的,因为单台压测机不论是网络连接,还是带宽以及自身CPU、内存等都会存在很大限制,性能压测不止是服务器资源会有很大消耗,提供压测能力的压测机也会很大的资源消耗。
(2)检查网络带宽的使用情况,排查瓶颈是否因为网络带宽限制而导致。此时,需要检查网络带宽的环节包括压测机到Web服务器、Web服务器到应用服务器、应用服务器到数据库服务器等所有存在网络请求交互的地方。如图7-5-3所示。(节选自《软件性能测试、分析与调优实践之路》(第2版),作者张永清,转载请注明出处)

图7-5-3
(3)参考本书5.3.2小节中使用jstack命令行工具,查看Java系统的线程堆栈,从线程堆栈中直接分析当前系统的瓶颈是因为在等待什么资源,而且该资源可能是一个隐形的不容易发现的资源。
(4)如果对于第(3)点运用不熟的话,可以用最笨的方式就是根据请求处理的链路过程,从上而下或者从下而上按顺序去排查。此时需要坚信一点,系统肯定是“堵在什么地方了”,仔细通过checklist去检查,一定能够找到这个“堵住”的位置。这就如同自来水的供水系统一样,如果某个用户突然反馈说,我家自来水水压很小,水压一直都上不去,那么自来水公司的维修人员上门之后,肯定是从这个用户家作为起点,然后对供水链路中的每个环节进行排查,直到找到是哪个环节出现了拥堵。 (节选自《软件性能测试、分析与调优实践之路》(第2版),作者张永清,转载请注明出处)
(5)如果按照前面四点还是找不到问题原因的话,那么可以尝试减少中间环节从而减少不确定因子的影响,再进行压测对比,先确定问题可能的范围,然后再在某个明确的范围内查找具体的原因。比如如图所示,将Web服务器去掉,让压测机的请求直接对应用服务器进行压测。如图7-5-4所示。
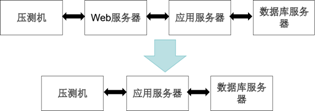
图7-5-4
3.在提高并发用户数时,系统的TPS缓慢下降而平均响应时间缓慢上升
如图7-5-5所示,当系统出现TPS下降而平均响应时间缓慢上升,可能是系统已经出现了性能的拐点,达到了最大的处理能力了。此时需要做一下如下检查

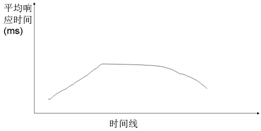
图7-5-5
(1)应用服务器资源,比如CPU、内存、IO等是否已经达到了使用上限。
(2)数据库服务器的资源以及数据库的链接数等是否已经达到了使用上限。
(3)如果第(1)点或者第(2)点中的资源使用已经达到了上限,可以对服务器资源进行扩容后,再重新继续压测。通常情况下,性能出现拐点时,服务器中某项资源也达到了使用的上限。
4. 性能压测过程中,服务器内存资源使用率一直在逐步缓慢上升,随着性能压测的持续进行,从来不会出现下降或者在一定范围内小幅度波动,并且此时TPS也在缓慢下降

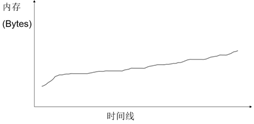
图7-5-6
如图7-5-6所示,当出现这种情况时,很有可能是出现了内存泄露,此时可以做如下检查:
(1)查看系统日志,看看有没有内存溢出的报错信息。
(2)在性能压测过程中参考使用本书5.2.1小节中的jconsole或者5.2.2小节中的jvisualvm来进一步定位Java JVM 是否存在内存泄露。(节选自《软件性能测试、分析与调优实践之路》(第2版),作者张永清,转载请注明出处)
(3)如果存在JVM 内存泄露,可以参考使用5.3.3小节中的MemoryAnalyzer工具来进一步分析是代码中哪个地方出现了内存泄露。
(4)性能压测过程中,当并发用户数和点击率不变的情况下,服务器的资源消耗应该是在一个稳定的范围内,或者在一定范围内不断地小幅度波动,这才是比较正常的。
(4)如果第(3)点无法排查到具体的问题,可以参考本书1.6.1小节中的分层分析的方式来定位问题。
5. 在分布式部署环境下的性能压测过程中出现每台应用服务器CPU或者内存资源消耗相差太大
如图7-5-7所示,当出现这种现象时,可以做如下排查:
(1)检查每台应用服务器的硬件配置是否一致。(节选自《软件性能测试、分析与调优实践之路》(第2版),作者张永清,转载请注明出处)
(2)检查每台应用服务器的操作系统,应用软件、数据库软件、JDK软件等版本以及配置信息是否一致。(节选自《软件性能测试、分析与调优实践之路》(第2版),作者张永清,转载请注明出处)
(3)如果第(1)点和第(2)点都没问题,检查Web服务器转发请求到应用服务器的负载均衡是否均匀。比如Nginx配置中是否有转发的权重不一致,或者有ip_hash等的配置限制,具体可以参考本书3.1.1小节中的介绍。
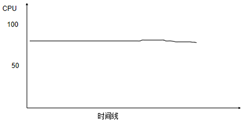
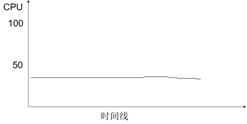
图7-5-7

评论已关闭。




