
扎克伯格说,Llama3-8B还是太大了,不适合放到手机中,有什么办法?
量化、剪枝、蒸馏,如果你经常关注大语言模型,一定会看到这几个词,单看这几个字,我们很难理解它们都干了些什么,但是这几个词对于现阶段的大语言模型发展特别重要,它们就是将模型缩小的利器。这篇文章就带大家来认识认识它们,理解其中的原理。
模型压缩
量化、剪枝、蒸馏,其实是通用的神经网络模型压缩技术,不是大语言模型专有的。
模型压缩的意义
通过压缩,模型文件会变小,其使用的硬盘空间也会变小,加载到内存或者显存时使用的缓存空间也会变小,并且模型的运行速度还可能会有一些提高。
通过压缩,使用模型将消耗更少的计算资源,这可以极大的扩展模型的应用场景,特别是对模型大小和计算效率比较关注的地方,比如手机、嵌入式设备等。
压缩的是什么?
压缩的是模型的参数,模型的参数又是什么呢?
你可能听说过现在的机器学习使用的都是神经网络模型,神经网络模型就是模拟人的大脑中的神经网络。
这里我画了一个简单的示意图,大家可以看看。

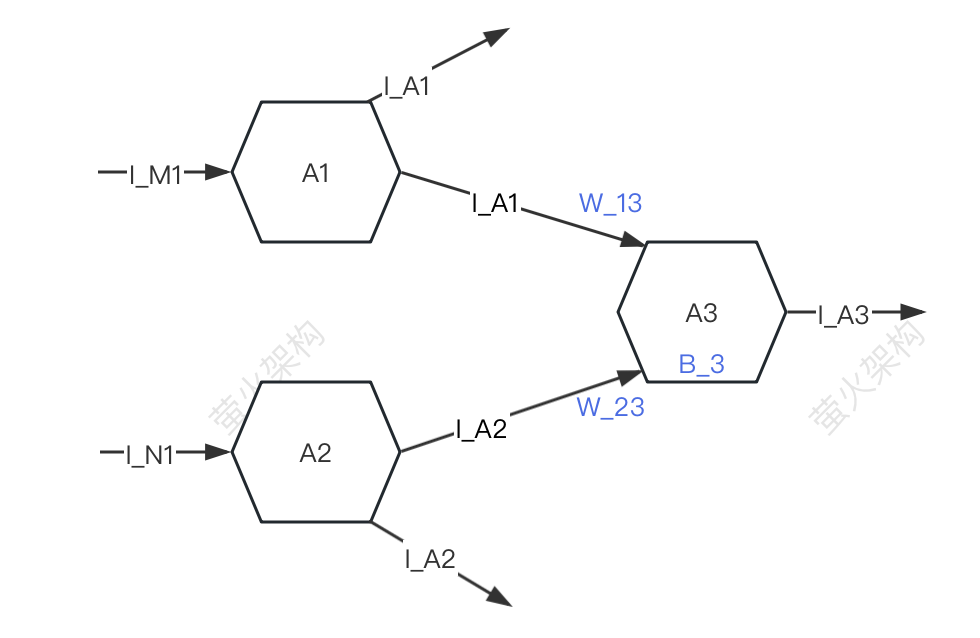
简单起见,只描述三个神经元:A1、A2、A3,每个神经元都会接收别的神经元的信号,也会将信号传递给别的神经元。
其中A3会接收A1、A2传递过来的信号I_A1、I_A2,但是A3接收A1、A2信号的强度是不一样的(这个强度称为“权重”),假设这里的强度分别是W_13和W_23,A3会对接收到信号数据进行加工:
- 首先对信号进行加权求和,也就是 I_A1*W_13+I_A2*W_23,
- 然后再加上A3自己的一个参数 B_3(称为“偏置”),
- 最后再把这个数据和转换为特定的形式,并把转换后的信号再发给下一个神经元。
在这个信号数据的加工过程中,用到的权重(W_13、W_23)和偏置( B_3 )就是模型的参数,当然模型还有其它一些参数,不过权重和偏置一般是所有参数中的大头,如果用二八原则来划分,应该都在80%以上。
使用大语言模型生成文本时,这些参数都已经是预训练好的,我们并不能对它们进行修改,这就像数学中多项式的系数,我们只能传递未知数xyz进去,然后得到一个输出结果。
模型压缩就是对模型的这些参数进行压缩处理,首要考虑的主要就是权重和偏置,使用的具体方法就是本文重点要介绍的量化、剪枝和蒸馏。
量化
量化就是降低模型参数的数值精度,比如最开始训练出的权重是32位的浮点数,但是实际使用发现用16位来表示也几乎没有什么损失,但是模型文件大小降低一般,显存使用降低一半,处理器和内存之间的通信带宽要求也降低了,这意味着更低的成本、更高的收益。
这就像按照菜谱做菜,你需要确定每种食材的重量。你可以使用一个非常精确的电子秤,它可以精确到0.01克,这固然很好,因为你可以非常精确地知道每样食材的重量。但是,如果你只是做一顿家常便饭,实际上并不需要这么高的精度,你可以使用一个简单又便宜的秤,最小刻度是1克,虽然不那么精确,但是足以用来做一顿美味的晚餐。
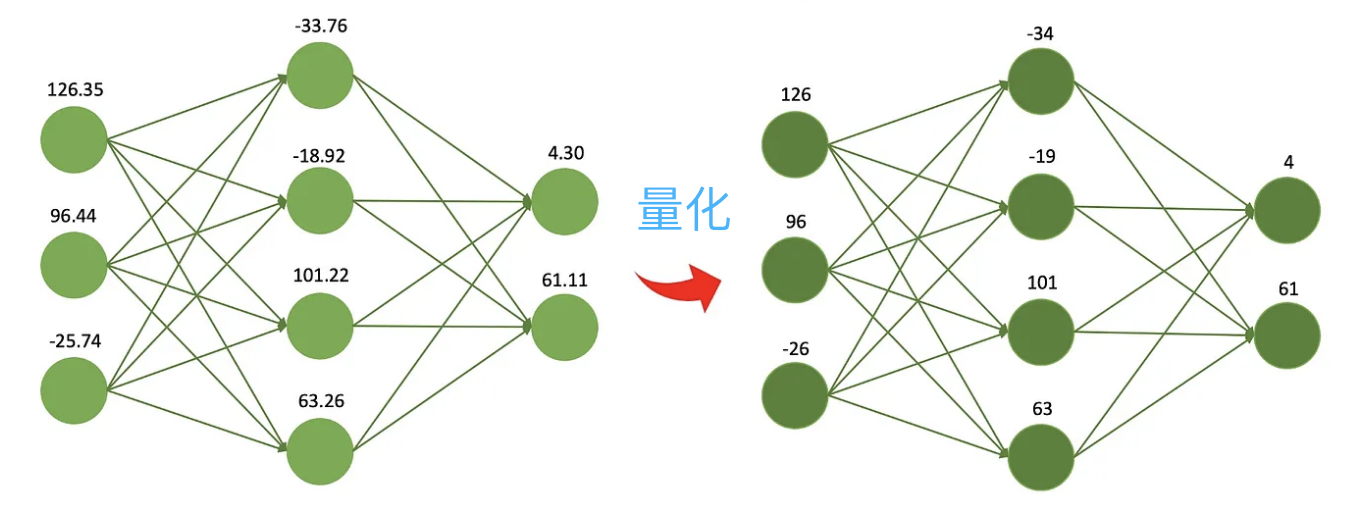
量化还有一个好处,那就是计算的更快。现代处理器中通常都包含了很多的低精度向量计算单元,模型可以充分利用这些硬件特性,执行更多的并行运算;同时低精度运算通常比高精度运算速度快,单次乘法、加法的耗时更短。这些好处还让模型得以运行在更低配置的机器上,比如没有高性能GPU的普通办公或家用电脑、手机等移动终端。
沿着这个思路,人们继续压缩出了8位、4位、2位的模型,体积更小,使用的计算资源更少。不过随着权重精度的降低,不同权重的值会越来越接近甚至相等,这会降低模型输出的准确度和精确度,模型的性能表现会出现不同程度的下降。
量化技术有很多不同的策略和技术细节,比如如动态量化、静态量化、对称量化、非对称量化等,对于大语言模型,通常采用静态量化的策略,在模型训练完成后,我们就对参数进行一次量化,模型运行时不再需要进行量化计算,这样可以方便地分发和部署。
剪枝
剪枝就是去掉模型中不重要的或者很少会用到的权重,这些权重的数值一般都接近于0。对于某些模型,剪枝可以产生比较高的压缩比,让模型更加紧凑和高效。这对于在资源受限的设备上或者内存和存储有限的情况下部署模型特别有用。
剪枝还会增强模型的可解释性。通过删除不必要的组件,剪枝使模型的底层结构更加透明且更易于分析。这对于理解神经网络等复杂模型的决策过程十分重要。
剪枝不仅涉及权重参数的剪枝,还可以剪除某些神经元节点,如下图所示:
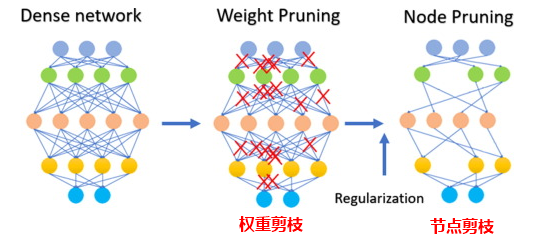
注意剪枝并非适合所有的模型,对于一些稀疏模型(大部份参数都为0或者接近于0),剪枝可能没什么效果;对于一些参数比较少的小型模型,剪枝可能导致模型性能的明显下降;对于一些高精度的任务或者应用,也不适合对模型进行剪枝,比如医疗诊断这种人命关天的事。
在实际运用剪枝技术时,通常需要综合考虑剪枝对模型运行速度的提升和对模型性能的负面影响,采取一些策略,比如给模型中的每个参数打分,也就是评估参数对模型性能的贡献有多大。分数高的,就是绝对不能剪掉的重要参数;分数低的,就是可能不那么重要,可以考虑剪掉的参数。这个分数可以通过各种方法计算,比如看参数的大小(绝对值大的通常更重要),或者通过一些更复杂的统计分析方法来确定。
蒸馏
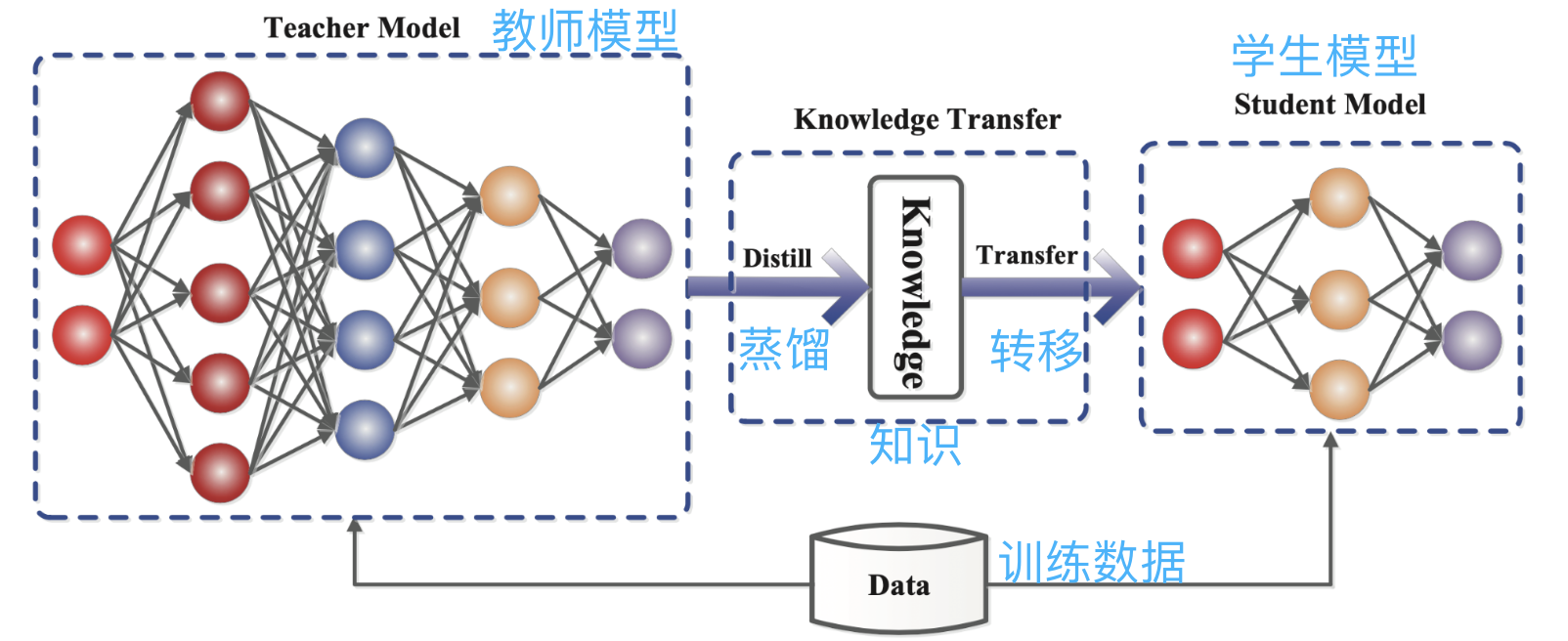
蒸馏就是把大模型学习到的概率分布直接复制到一个小模型中。被复制的模型称为教师模型,一般是参数量较大、性能很强的优秀模型,新模型称为学生模型,一般是参数比较少的小模型。
蒸馏时,教师模型会根据输入生成多个可能输出的概率分布,然后学生模型学习这个输入和输出的概率分布情况。经过大量训练,学生模型就可以模仿教师模型的行为,或者说学习到了教师模型的知识。
比如在图像分类任务中,给出一张图,教师模型可能会输出类似如下的概率分布:
- 猫:0.7
- 狗:0.4
- 车:0.1
然后把这张图和输出的概率分布信息一起提交给学生模型进行模仿学习。
因为蒸馏是把教师模型的知识压缩到一个更小更简单的学生模型中,新的模型可能会丢失一些信息;另外学生模型可能过度依赖教师模型,导致模型的泛化能力不佳。
为了让学生模型的学习效果更好,我们可以采用一些方法和策略。
引入温度参数:假设有一位老师讲课速度非常快,信息密度很高,学生可能有点难以跟上。这时如果老师放慢速度,简化信息,就会让学生更容易理解。在模型蒸馏中,温度参数起到的就是类似“调节讲课速度”的作用,帮助学生模型(小模型)更好地理解和学习教师模型(大模型)的知识。专业点说就是让模型输出更加平滑的概率分布,方便学生模型捕捉和学习教师模型的输出细节。
调整教师模型和学生模型的结构:一个学生想要从一个专家那里学点东西可能是很难的,因为他们之间的知识差距太大,直接学习可能会听不懂,这时候可以在中间加入一个老师,它既能理解专家的话,又能转化为学生可以听懂的语言。中间加入的这个老师可能是一些中间层或者辅助神经网络,或者这个老师可以对学生模型进行一些调整,让它能更匹配教师模型的输出。
上边我们介绍了三种主要的模型压缩技术,其实这里边还有很多的细节,不过对于理解原理差不多已经够了,也还有其它一些模型压缩技术,比如低秩分解、参数共享、稀疏连接等,有兴趣的同学可以多去查查相关内容。
另外模型压缩后,其性能可能会出现比较明显的下降,此时我们可以对模型进行一些微调,特别是一些对模型精度要求比较高的任务,比如医学诊断、金融风控、自动驾驶等,微调可以让模型的性能得到一定的恢复,稳固其在某些方面的准确性和精确性。
谈到模型微调,最近我在AutoDL上分享了一个 Text Generation WebUI 的镜像,Text Generation WebUI 是一个使用Gradio编写的Web程序,可以方便的对大语言模型进行推理、微调,支持多种类型的大语言模型,包括Transformers、llama.cpp(GGUF)、GPTQ、AWQ、EXL2等多种格式的模型,在最新的镜像中,我已经内置了Meta最近开源的 Llama3 大模型,感兴趣的同学可以去体验下,使用方法参见:十分钟学会微调大语言模型
参考文章:
https://zhuanlan.zhihu.com/p/75879624
https://medium.com/fintechexplained/neural-networks-bias-and-weights-10b53e6285da
https://botpenguin.com/glossary/pruning
https://www.sciencedirect.com/science/article/abs/pii/S0925231221011917
https://medium.com/@jan_marcel_kezmann/master-the-art-of-quantization-a-practical-guide-e74d7aad24f9




