
无监督多视角行人检测 Unsupervised Multi-view Pedestrian Detection
论文url:https://arxiv.org/abs/2305.12457
论文简述
该论文提出了一种名为Unsupervised Multi-view Pedestrian Detection (UMPD)的新方法,旨在通过多视角视频监控数据准确地定位行人,而无需依赖于人工标注的视频帧和相机视角。
总体框架图

当我第一时间看到这个框架图,顿时感觉头发都掉了好几根,他这个设计确实有点复杂,并且和之前看的多视角检测方法很不一样,可能有些理解偏差,欢迎指正。
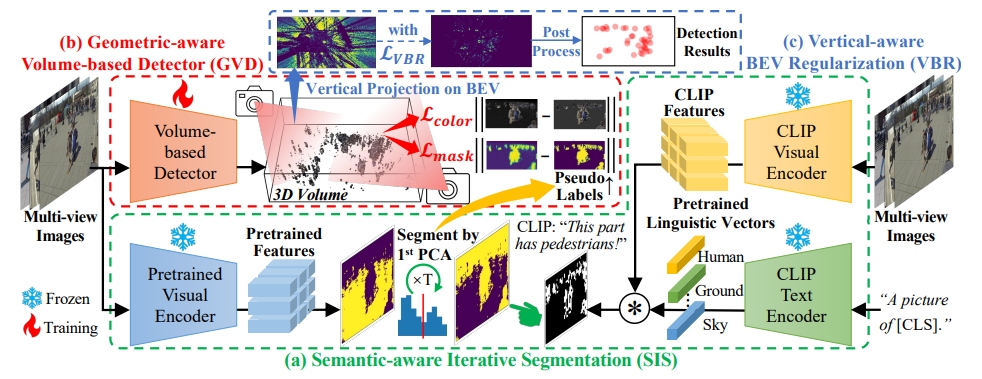
输入
- 不同视角下多个摄像头的同步图像数据
语义感知迭代分割 Semantic-aware Iterative Segmentation(SIS)
PS: 该模块所在部分就是上图绿色框部分,该模块主要分为两个部分,一个是PCA主成分迭代分析生成前景掩码部分,一个是零样本分类视觉-语言模型CLIP部分生成 $ {S}^{human} $ 语意掩码选择PCA的前景掩码部分。
-
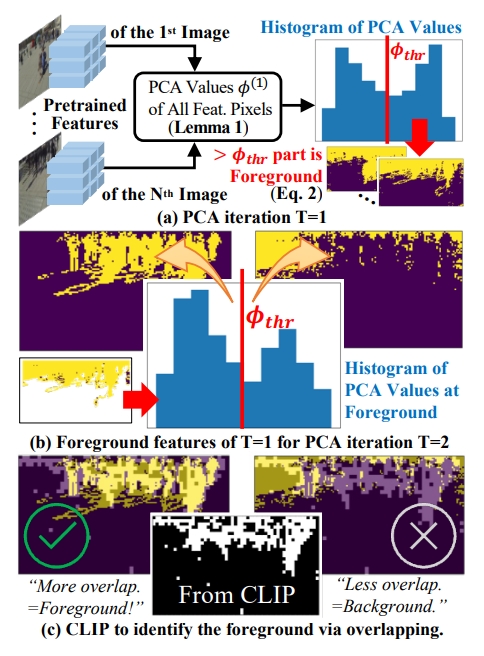
PCA主成分迭代分析:
- 首先, 多个摄像头的同步图像数据通过无监督模型提取预训练特征,将所有图像的预训练特征向量集合并成一个更大的特征矩阵,在这个矩阵中,每一行代表一个图像的特征向量,每一列代表特征向量中的一个维度。(猜测具体操作应该是模型中的最后一个卷积层的特征图进行展平操作,变成一个一维特征向量。将所有的一维特征向量堆叠起来就形成了一个二维的特征矩阵。)
- 然后将这个二维的特征矩阵进行PCA降维操作,PCA的目的是找到一个新的低维特征空间,其中第一个主成分捕捉原始高维特征中的最大方差。通过PCA,数据被投影到第一个主成分(即PCA向量)上,生成一个新的一维特征表示。这个一维表示是每个原始高维特征向量在PCA方向上的投影长度。
- 根据一维PCA值为每个视角生成初步的行人掩膜(即二值图像,设定一个阈值,其中行人前景(大于阈值)被标记为1,背景(小于等于阈值)为0)。
-
零样本分类视觉-语言模型CLIP:
CLIP拥有两个模块- CLIP Visual Encoder
输入的是多个摄像头的同步图像数据
输出是视觉特征图 - CLIP Text Encoder
输入是与行人相关的文本描述
生成语言特征向量 - 将语言特征向量与视觉特征图进行余弦相似度计算,得出图 $ {S}^{human} $
- CLIP Visual Encoder
-
两模块结合操作:
- 将CLIP生成的 $ {S}^{human} $ 与PCA生成的前景掩码进行重叠,来判断哪些前景掩码属于行人前景,然后将这些前景掩码继续用PCA进行迭代以及CLIP判断直到规定的迭代次数将前景掩码输入到下一部分作为伪标签。
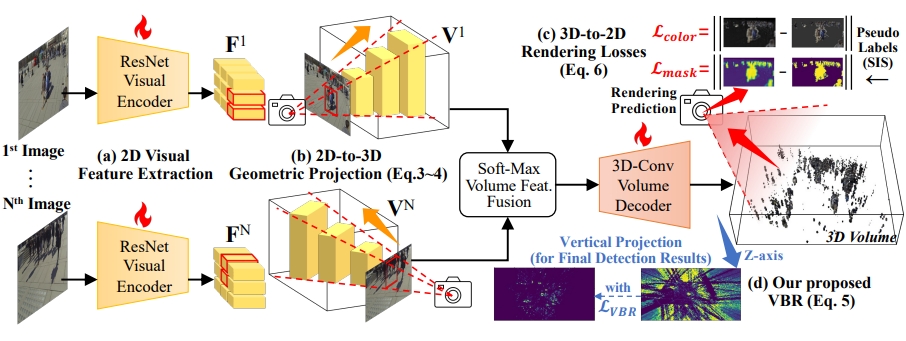
几何感知体积探测器 Geometric-aware Volume-based Detector(GVD)
PS: 该模块所在部分就是第一张图红色框部分
- 2D特征提取:每个视角拍摄的图都用ResNet Visual Encoder进行特征提取。
- 2D到3D的几何投影:提取的特征随后被映射到3D空间中。这一步骤涉及到使用相机的内参和外参矩阵,将2D图像中的像素点映射到3D空间中的体素上。这个过程基于针孔相机模型,通过几何变换将2D图像中的信息转换为3D体积的一部分。
- 3D体积融合:由于每个视角都会生成一个3D体积,GVD模块需要将这些体积融合成一个统一的3D体积。这通常通过一个Soft-Max Volume Feat. Fusion函数来实现,该函数可以对来自不同视角的3D体积进行加权和融合。
- 3D卷积网络解码器:融合后的3D体积被送入一个3D卷积网络解码器,该解码器负责预测每个体素的密度和颜色。这个解码器通常由一系列3D卷积层组成,能够学习从2D图像到3D体积的复杂映射关系。(论文中没有给出该解码器具体是怎么设计的)
- 3D渲染为2D:作者用PyTorch3D可微分渲染框架将预测的3D密度 $ {D} $ 渲染为2D掩码 (tilde{M}) ,并且将预测的3D颜色 $ {C} $ 渲染为2D图像 (tilde{I}) , $ {M} $ 为SIS输出的前景掩码, $ {I} $ 论文中说是根据前景掩码得出的颜色图像(猜测应该是前景图像中为1的部分才保留原图颜色)。
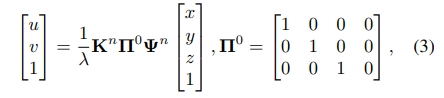
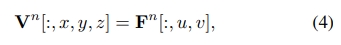
垂直感知BEV正则化 Vertical-aware BEV Regularization
- 通过GVD得出的3D体积中的密度信息沿着Z轴(垂直轴)进行最大值投影,以生成BEV(Bird Eye View)表示。这样可以得到一个二维平面图,其中高密度区域表示行人的位置,得出结果。
- 并且为了应对出现的行人躺着或者斜着的情况(在大多数情况下,行人的姿态是接近垂直的),论文提出了Vertical-aware BEV Regularization(VBR)方法。通过计算 $ {L}_{VBR} $ 损失函数来优化这个影响。
- 损失函数
运用了Huber Loss
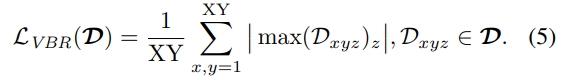
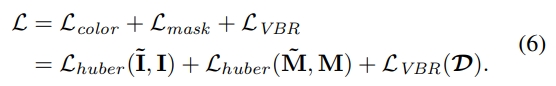
效果图

后记
作者最后应该还做了些后处理,但是论文中没有提及具体内容。该篇内容细节很多,公式变换复杂,有些细节我做了一定的省略,建议结合着论文原文来看。
ps:终于干完这篇了,鼠鼠我要逝了🥵




