
大白话,Hadoop是个存储数据,计算数据的分布式框架。核心组件是HDFS、MapReduce、Yarn。
HDFS:分布式存储
MapReduce:分布式计算
Yarn:调度MapReduce
现在为止我们知道了HDFS、MapReduce、Yarn是干啥的,下面通过一张图再来看看他的整体架构。

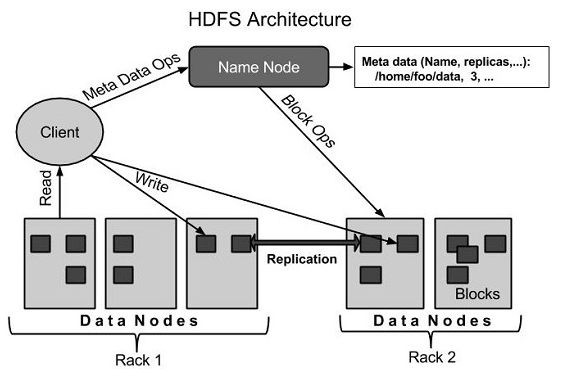
HDFS是Hadoop的存储系统,将庞大的数据存储在多台机器上,并通过数据副本冗余实现容错。HDFS两大核心组件是NameNode与DataNode。
NameNode:管理文件命名空间元数据;实现文件命名、打开关闭操作
SecondaryNameNode:帮助NameNode实现log与数据快照的合并
DataNode:根据客户请求实现文件的读写
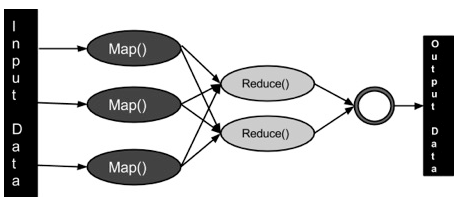
MapReduce是基于Java开发的分布式计算。包含重要的两部分,Map和Reduce。
Map:将数据转成键值对
Reduce:将Map的输出数据聚合减少
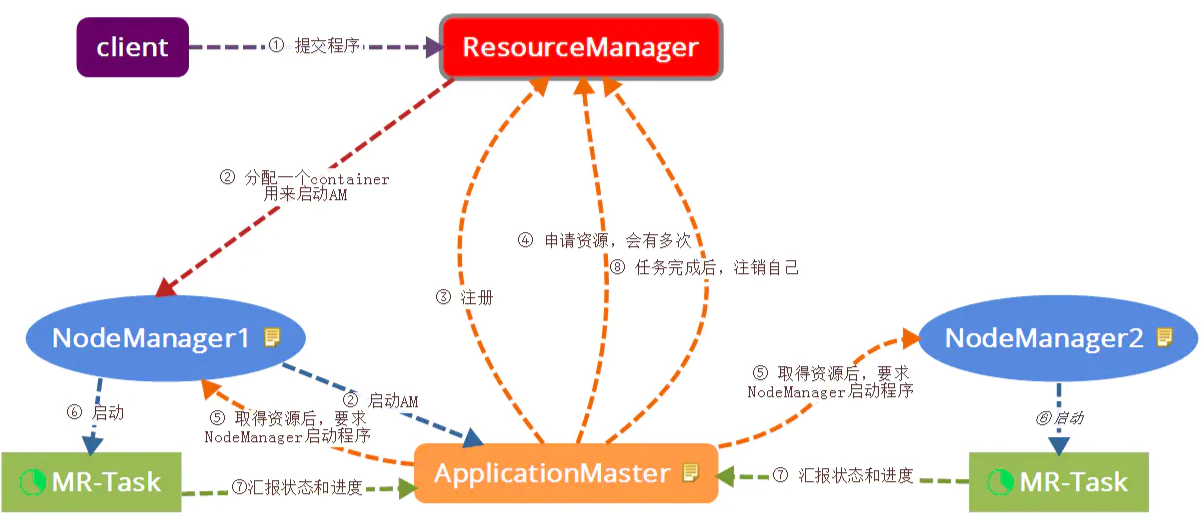
通过对集群资源的监控,调度MapReduce的任务。核心组件有ResourceManager、NodeManager、ApplicationMaster 和 Container。
ResourceManager:处理客户端请求;监控NodeManager与ApplicationMaster;调度资源。
NodeManager:管理节点资源;与ResourceManager ApplicationMaster交互。
ApplicationMaster:为程序申请资源并将资源分配给任务;任务监控。
下载https://www.oracle.com/java/technologies/downloads/
解压
tar -zxvf jdk-8u331-linux-x64.tar.gz
加入环境变量
vi /etc/profile #加入以下内容 JAVA_HOME=/usr/local/java18/jdk1.8.0_331 JRE_HOME=$JAVA_HOME/jre PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib export JAVA_HOME JRE_HOME PATH CLASSPATH //生效 source /etc/profile
验证java
下载https://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-3.2.3/hadoop-3.2.3.tar.gz
解压
tar xzf hadoop-3.2.3.tar.gz
配置本机ssh
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys chmod 0600 ~/.ssh/authorized_keys
配置Hadoop环境变量
cat etc/hadoop/hadoop-env.sh
export JAVA_HOME=/usr/local/java/jdk1.8
配置hdfs地址
cat etc/hadoop/core-site.xml <property> <name>fs.defaultFS</name> <value>hdfs://localhost:9000</value> </property>
配置hafs分片数
cat etc/hadoop/hdfs-site.xml
<property> <name>dfs.replication</name> <value>1</value> </property>
export HADOOP_HOME=/usr/local/hadoop/hadoop-3.2.3 export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin export HADOOP_INSTALL=$HADOOP_HOME export HADOOP_CLASSPATH=${JAVA_HOME}/lib/tools.jar //生效 source /etc/profile
配置mapreduce
vi etc/hadoop/mapred-site.xml <configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.application.classpath</name> <value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*</value> </property> </configuration>
配置yarn
vi etc/hadoop/yarn-site.xml <configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.env-whitelist</name> <value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_HOME,PATH,LANG,TZ,HADOOP_MAPRED_HOME</value> </property> </configuration>
配置相关user
//将sbin/start-dfs.sh,sbin/stop-dfs.sh两个文件顶部添加以下参数 HDFS_DATANODE_USER=root HADOOP_SECURE_DN_USER=hdfs HDFS_NAMENODE_USER=root HDFS_SECONDARYNAMENODE_USER=root //将sbin/start-yarn.sh,sbin/stop-yarn.sh顶部也需添加以下 YARN_RESOURCEMANAGER_USER=root HADOOP_SECURE_DN_USER=yarn YARN_NODEMANAGER_USER=root
初始化hdfs
bin/hdfs namenode -format
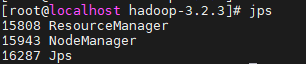
启动yarn
sbin/start-yarn.sh
通过jps查看启动的进程
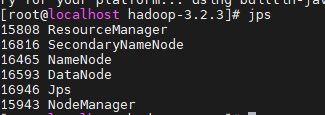
启动hdfs
sbin/start-dfs.sh
通过jps查看进程
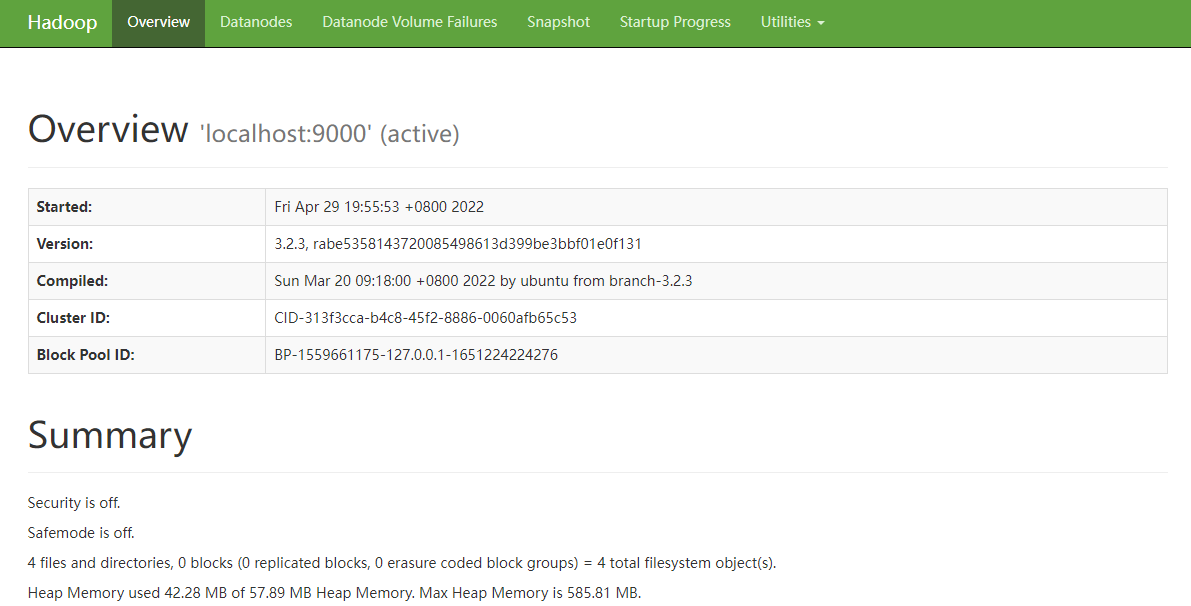
访问hadoopui验证安装是否成功
http://192.168.43.50:9870/dfshealth.html#tab-overview
访问集群ui
http://192.168.43.50:8088/cluster/cluster
评论已关闭。




![洛谷 P11345 [KTSC 2023 R2] 基地简化 题解](http://www.itfaba.com/wp-content/themes/kemi/timthumb.php?src=http://www.itfaba.com/wp-content/themes/kemi/img/random/3.jpg&w=218&h=124&zc=1)
