
本文代码、标记工具、测试训练集均已开源,仅需关注 萤火初芒 公众号回复AISharp即可查看仓库地址,供学习交流使用,无套路(部分测试图片为网图,侵删)。
一、Yolo训练的实现基础
实现纯C#训练Yolo,我们可以选择在 YoloSharp (https://github.com/IntptrMax/YoloSharp) 的基础上进行实现。需要注意的是搜出来的高星同名YoloSharp项目有两个,一个是跑模型的(dme-compunet/YoloSharp),另一个才是可训练的(IntptrMax/YoloSharp),我们使用后者,后续提到YoloSharp均指IntptrMax/YoloSharp。
在YoloSharp代码中可以看到,项目包含了多个不同版本Yolo的TorchSharp实现(对TorchSharp不了解的可以看之前将TorchSharp的文章)。可自行调整或保持与Yolov11一致的结构。YoloSharp中的Yolo11模型代码如下:
public class Yolov11 : Yolov8 { protected override int[] outputIndexs => new int[] { 4, 6, 10, 13, 16, 19, 22 }; public Yolov11(int nc = 80, YoloSize yoloSize = YoloSize.n, Device? device = null, torch.ScalarType? dtype = null, int[] kpt_shape = null) : base(nc, yoloSize, device, dtype, kpt_shape: kpt_shape) { } internal override ModuleList<Module> BuildModel(int nc, YoloSize yoloSize, Device? device, torch.ScalarType? dtype) { (float depth_multiple, float width_multiple, int max_channels, bool useC3k) = yoloSize switch { YoloSize.n => (0.5f, 0.25f, 1024, false), YoloSize.s => (0.5f, 0.5f, 1024, false), YoloSize.m => (0.5f, 1.0f, 512, true), YoloSize.l => (1.0f, 1.0f, 512, true), YoloSize.x => (1.0f, 1.5f, 768, true), _ => throw new ArgumentOutOfRangeException(nameof(yoloSize), yoloSize, null) }; base.widths = new List<int> { 64, 128, 256, 512, 1024 }.Select(w => Math.Min((int)(w * width_multiple), max_channels)).ToArray(); int depthSize = (int)(2 * depth_multiple); ch = new int[] { widths[2], widths[3], widths[4] }; ModuleList<Module> mod = new ModuleList<Module>( new Conv(3, widths[0], 3, 2, device: device, dtype: dtype), new Conv(widths[0], widths[1], 3, 2, device: device, dtype: dtype), new C3k2(widths[1], widths[2], depthSize, useC3k, e: 0.25f, device: device, dtype: dtype), new Conv(widths[2], widths[2], 3, 2, device: device, dtype: dtype), new C3k2(widths[2], widths[3], depthSize, useC3k, e: 0.25f, device: device, dtype: dtype), new Conv(widths[3], widths[3], 3, 2, device: device, dtype: dtype), new C3k2(widths[3], widths[3], depthSize, c3k: true, device: device, dtype: dtype), new Conv(widths[3], widths[4], 3, 2, device: device, dtype: dtype), new C3k2(widths[4], widths[4], depthSize, c3k: true, device: device, dtype: dtype), new SPPF(widths[4], widths[4], 5, device: device, dtype: dtype), new C2PSA(widths[4], widths[4], depthSize, device: device, dtype: dtype), Upsample(scale_factor: new double[] { 2, 2 }, mode: UpsampleMode.Nearest), new Concat(), new C3k2(widths[4] + widths[3], widths[3], depthSize, useC3k, device: device, dtype: dtype), Upsample(scale_factor: new double[] { 2, 2 }, mode: UpsampleMode.Nearest), new Concat(), new C3k2(widths[3] + widths[3], widths[2], depthSize, useC3k, device: device, dtype: dtype), new Conv(widths[2], widths[2], 3, 2, device: device, dtype: dtype), new Concat(), new C3k2(widths[3] + widths[2], widths[3], depthSize, useC3k, device: device, dtype: dtype), new Conv(widths[3], widths[3], 3, 2, device: device, dtype: dtype), new Concat(), new C3k2(widths[4] + widths[3], widths[4], depthSize, c3k: true, device: device, dtype: dtype), new Yolov8Detect(nc, ch, false, device: device, dtype: dtype) ); return mod; } } 二、数据集准备
训练开始前需要先准备训练集。以目标检测为例,每一张图片和该图片对应的分类标签构成了一个case,比如 001.jpg 和 001.txt。
图片:如果图片尺寸不同,模型读取后会自行适配大小。当某些群体或场景在数据集中代表性不足或过度代表时,会导致泛化能力差。因此尽量需要从多个来源收集数据,以捕获不同的视角和场景,如果实在样本不够还可以对代表性不足的类别进行过采样、或考虑数据增强和公平感知算法。
标注:常见的标注有边界框(对象检测任务)、多边形(实例分割)、掩码(语义分割)、关键点(姿势估计和面部特征点检测)等。
以对象检测任务为例, 假设001.jpg是训练集中的一个图像,001.txt是与图片对应的标注数据:
// 001.txt 0 0.486622 0.287910 0.273133 0.243852 1 0.386423 0.549155 0.532456 0.732381 每行有5列数据,各自对应的含义如下:
| 类别 | 中心x | 中心y | 对象框宽度 | 对象框高度 |
|---|---|---|---|---|
| 0 | 0.486622 | 0.287910 | 0.273133 | 0.243852 |
制作数据集是入门的第一道坎。为了提高效率,有多种开源工具可以帮助简化数据标注流程。本项目中用的是Yolo_Label,提供了较好的快捷键与简单的操作逻辑,仅需选择分类,框选即可完成标记,显著提升了标注速度。
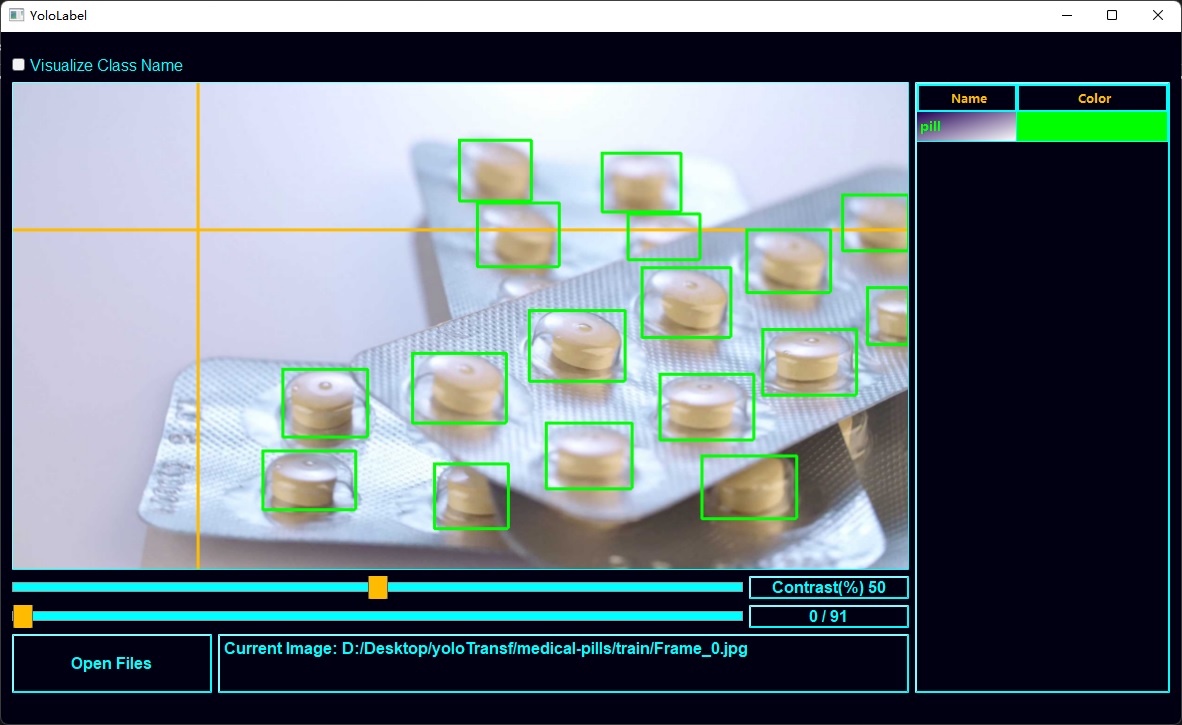
三、模型训练
3.1 训练前参数配置
开源的YoloSharp开放了很多参数可以直接用。如果没有开放的,比如想修改optimizer(默认为SGD),也可以直接去源码中对TorchSharp代码进行修改。
下面是YoloSharp给出的Demo中用到的参数,以及相关说明。
本项目中对trainDataPath和valDataPath的路径配置进行了修改,为了方便使标记与图片放在了同一个文件夹下,这样就和Yolo_Label输出路径一致了。
// 训练集根目录 string rootPath = @"D:DesktopyoloTransfmedical-pills"; // 训练数据的目录,存放图片和标注 xxxx.jpg xxxx.txt string trainDataPath = @"train"; // 用于评估训练过程数据的目录,存放图片 xxxx.jpg xxxx.txt // 也可以用训练集来评估 string valDataPath = @"val"; // 模型输出位置,自动保存 best.bin 和 last.bin string outputPath = @"D:DesktopyoloTransfmedical-pillsresult"; // 批训练组大小 int batchSize = 5; // 总类别的数量,设置不对会报错 int numberClass = 1; // 训练迭代次数 int epochs = 120; // 训练时所有图像被统一缩放到的边长 int imageSize = 480; // 预测时 float predictThreshold = 0.3f; float iouThreshold = 0.5f; // YoloSharp自带的枚举值 YoloType yoloType = YoloType.Yolov11; // Yolo代 DeviceType deviceType = DeviceType.CUDA; // Cpu or GPU ScalarType dtype = ScalarType.Float32; // 候选 Float16 YoloSize yoloSize = YoloSize.n; // 预设几档大小 n, s , m, l, x ImageProcessType imageProcessType = ImageProcessType.Mosiac; // 候选 LetterBox TaskType taskType = TaskType.Detection; // YoloSharp目前支持的几种任务类型:Detection, Segmentation, Obb, Pose Classification = 4, 3.2 模型训练
模型训练主要代码就4行。需要先实例化一个YoloTask实例;然后选择性的可加载之前预训练的模型; 如果不加载也可以从头开始直接Train; 手动另存SaveModel(原项YoloSharp自动保存没有SaveModel方法,这个是自己改的)。
// 实例化 YoloTask yoloTask = new YoloTask(taskType, numberClass, yoloType: yoloType, deviceType: deviceType, yoloSize: yoloSize, dtype: dtype); // 可选 // yoloTask.LoadModel(@"d:medical-pills.yolo11", skipNcNotEqualLayers: true); // 训练 yoloTask.Train(rootPath, trainDataPath, valDataPath, lr: 1E-4f, outputPath: outputPath, imageSize: imageSize, batchSize: batchSize, epochs: epochs, imageProcessType: imageProcessType); // 另存 yoloTask.SaveModel(@"d:medical-pills.yolo11"); 在单纯运行预测的时候,把train和saveModel全部注释掉,仅实例化YoloTask就可以了。
3.3 模型预测
定义一个路径,然后读取,传入加载好的模型执行预测,生成YoloResult。YoloResult的各个元素就代表着一个对象检测任务中识别到的结果。
string predictImagePath = @"D:DesktopyoloTransfmedical-pillsvalFrame_456.jpg"; Mat predictImage = Cv2.ImRead(predictImagePath); float predictThreshold = 0.3f; // 检测置信度的阈值,越低越容易检出 float iouThreshold = 0.5f; // 区域重叠度的阈值,越低越容易检出 List<YoloResult> predictResult = yoloTask.ImagePredict(predictImage, predictThreshold, iouThreshold); 其他包括在图片上绘制检测框以及类别标注就比较简单,demo里都有不再赘述。
四、模型效果
以下案例都是在笔记本上训练10来分钟就停止了,并不代表YoloSharp的最终效果。仅作为可用性的初探以及使用的示例。
4.1 公开数据集测试
检查模型及代码效果首先可以尝试官方的数据集,如ultralytics提供了很多经典数据集免费下载还有详细说明(https://docs.ultralytics.com/zh/datasets/)。
我们先试试医疗药丸(medical-pills )案例。效果看起来还不错,用了最小的模型,其他参数默认,效果还不错,具体如下:
| 训练集大小 | 文件大小 | 图像尺寸 | 模型大小 | 训练时长 | 内存占用 | GPU负载 |
|---|---|---|---|---|---|---|
| 98 | 6.92 MB | 1920×1080 | n: 11 MB | 10 min | 9 GB | - |
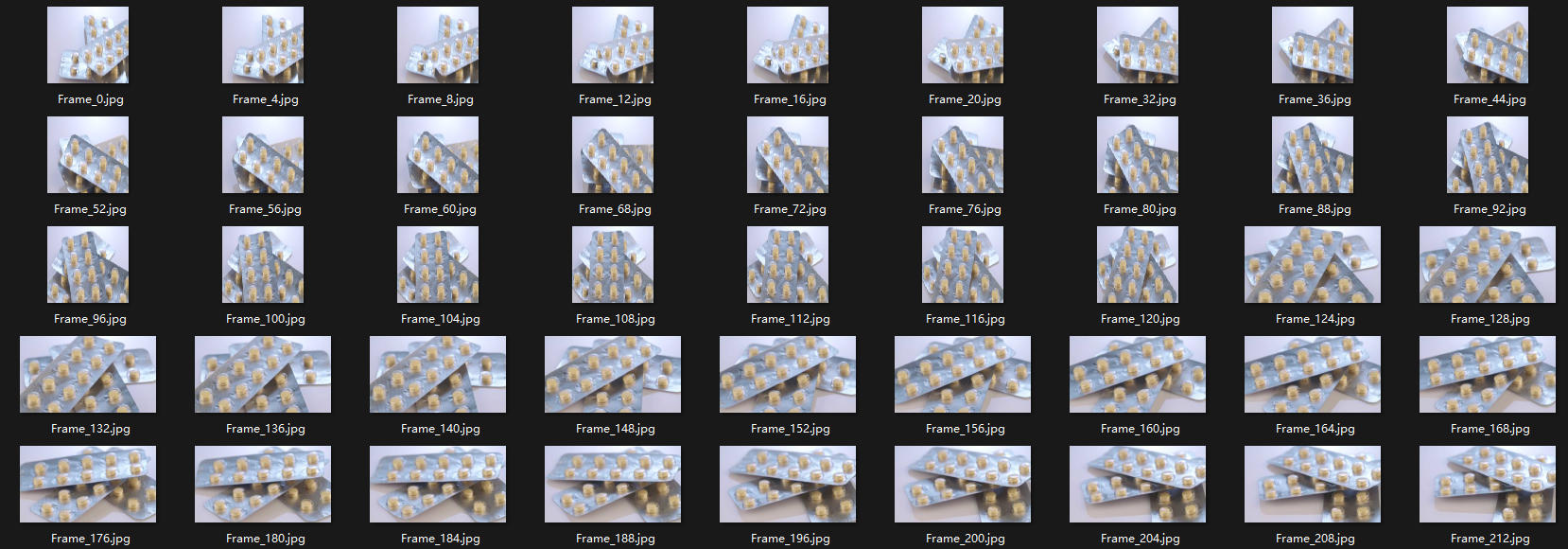
官方训练集图片及标注示意:
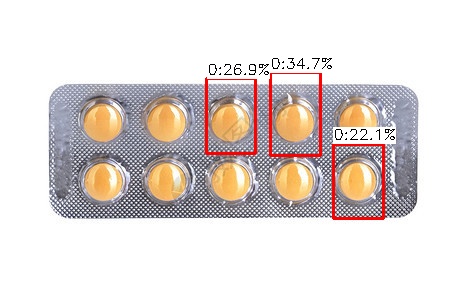
使用官方图片检验预测效果(下图),训练集质量很高,形状特征简单明显,最终效果看着很好:

外部图片检验预测效果(下图),泛化比较差,也与训练集过于单一有关:
4.2 自定义数据集测试
尝试在网上搜集了部分持烟的照片,象征性的进行了训练,能在部分场景下,大致识别出人头部位,说明模型能用,最终效果还得看训练集质量。
| 训练集大小 | 文件大小 | 图像尺寸 | 模型大小 | 训练时长 | 内存占用 | GPU 负载 |
|---|---|---|---|---|---|---|
| 50 | 3.99 MB | 不定 | l: 77 MB | 30 min | 16 GB | 99 % |
训练集图片示意:

自定义的标注分类(下图),将头部分为smoke(持烟)和nosmoke(未持烟)两类:
:

预测效果,部分图片仅能识别出0类别(即抽烟的头部),且置信度很低:


反过来对训练集的预测效果检查发现(下图),仅仅训练出了头部的识别,可能与训练样本中二者比例相差过大,样本太小,训练不充分有关:


六、 最后
在C# 训练Yolo模型貌似是可行的。尽管语法不如python那么灵活,运行不如脚本化那么方便。但是,C# 开发工具适配工具的能力强啊,说不定分分钟就整出来美观友好全界面操作人人都能上手的UI了。
感谢您的阅读,本案例及更加完整丰富的机器学习模型案例的代码已全部开源,关注公众号回复AISharp即可查看仓库地址,本期相关代码在仓库下面的YoloInSharp_YoloSharp文件夹里可以找到。





