
MPK(Mirage Persistent Kernel)源码笔记(4)--- 转译系统
0x00 概要
此处的”转译系统“包含两部分:
- 把计算图转换为任务图。
- 将 Mirage 生成的(优化过的)计算图转换为高效的 CUDA 代码
0x01 Task和Event
在 Mirage 持久化内核(Persistent Kernel)的设计与实现中,需突破三个关键技术瓶颈:
- 如何将抽象算子转化为可执行任务。
- 如何处理任务间的数据依赖。
- 如何高效分配任务至 GPU 计算单元。
这三个问题的解决,直接决定了内核能否充分发挥 GPU 并行性能,适配复杂张量计算场景(如大语言模型推理)。Mirage 通过引入Task和Event,与三层图一起来解决上述问题:
- Kernel Graph 定义张量数据流
- Block Graph 定义内存访问模式
- Task 执行具体计算
- Event 管理任务依赖关系
- Thread Graph 执行底层并行计算
1.1 可执行任务
GPU 执行 CUDA 或 Triton 代码时,需将算子的整体计算逻辑切分为多个 “计算块”(Block)—— 每个计算块对应 GPU 流式多处理器(SM)可承载的基本计算单元,最终由调度系统分配至不同 SM 并行执行。基于这一硬件特性,Mirage 持久化内核将 “单个计算块的计算” 定义为最小任务单元(Task),实现算子到任务的结构化转化。
1.1.1 任务定义
任务的由TaskDesc 来实现。
struct TaskDesc { TaskDesc(TaskType t, int _variant_id) : task_type(t), variant_id(_variant_id), num_inputs(0), num_outputs(0), trigger_event(EVENT_INVALID_ID), dependent_event(EVENT_INVALID_ID) {} TaskDesc() {} TaskType task_type; // 任务类型 unsigned variant_id; // 变体ID int num_inputs, num_outputs; EventId trigger_event; // 触发事件 EventId dependent_event; // 依赖事件 TensorDesc inputs[MAX_INPUTS_PER_TASK]; // 张量描述 TensorDesc outputs[MAX_OUTPUTS_PER_TASK]; }; 1.1.2 任务类型
任务类型如下:
enum TaskType { TASK_TERMINATE = 0, // 终止任务 TASK_BEGIN_TASK_GRAPH = 10, // 人物图开始标记 // compute task starts from 100 TASK_EMBEDDING = 101, // 嵌入层 TASK_RMS_NORM_LINEAR = 102, // RMS归一化和线性层组合 TASK_ATTENTION_1 = 103, // 注意力机制第一部分 TASK_ATTENTION_2 = 104, // 注意力机制第二部分 TASK_SILU_MUL_LINEAR_WITH_RESIDUAL = 105, TASK_ALLREDUCE = 106, TASK_REDUCE = 107, TASK_LINEAR_WITH_RESIDUAL = 108, TASK_ARGMAX = 109, TASK_ARGMAX_PARTIAL = 110, TASK_ARGMAX_REDUCE = 111, TASK_FIND_NGRAM_PARTIAL = 112, //部分n-gram查找 TASK_FIND_NGRAM_GLOBAL = 113, // 全局n-gram查找 TASK_TARGET_VERIFY_GREEDY = 114, // 贪心目标验证 TASK_SINGLE_BATCH_EXTEND_ATTENTION = 115, TASK_NVSHMEM_COPY = 199, // 使用NVSHMEM进行跨GPU的数据复制 TASK_SCHD_TASKS = 200, // 调度任务 TASK_SCHD_EVENTS = 201, // 调度事件 TASK_GET_EVENT = 202, // 获取事件 TASK_GET_NEXT_TASK = 203, // 获取任务 }; 1.2 事件
传统内核设计中,数据依赖关系以算子为单位定义 —— 只有前一个算子的所有计算完全结束,后一个算子才能启动,这种粗粒度依赖会导致大量计算资源闲置(例如前一算子仅剩余少量计算未完成时,后一算子需持续等待)。Mirage 持久化内核将依赖关系下沉至任务级别,实现更精细的并行调度。具体而言,算子级依赖会被拆解为任务间的依赖链,即事件。
1.2.1 事件定义
事件的由 EventDesc 来实现。
struct EventDesc { EventDesc(void) : event_type(EVENT_INVALID), num_triggers(0), first_task_id(TASK_INVALID_ID), last_task_id(TASK_INVALID_ID) {} EventDesc(EventType type, int nt, TaskId f, TaskId l) : event_type(type), num_triggers(nt), first_task_id(f), last_task_id(l) {} EventType event_type; int num_triggers; // 触发器数量 TaskId first_task_id, last_task_id; // 首尾任务ID范围 }; 1.2.2 事件类型
事件类型如下:
enum EventType { EVENT_EMPTY = 900, // 空事件 EVENT_LAUNCH_TASKS = 901, // 启动任务 EVENT_LAUNCH_MASSIVE_TASKS = 902, // 启动大规模任务 EVENT_LAUNCH_DEPENDENT_TASKS = 903, // 启动依赖任务 EVENT_END_OF_TASK_GRAPH = 910, // 任务图结束 EVENT_TERMINATION = 911, // 终止事件 EVENT_INVALID = 999, //无效事件 }; 下图展示了如何确定事件类型。

0x02 生成CUDA代码
TaskDesc 结构体本身并不直接包含可执行代码。它更像是一个任务的描述符或配置信息,包含了任务执行所需的一些元数据。
2.1 生成代码
实际的可执行代码是通过以下方式来生成的。
register_muggraph
- 在 runtime.cc 的 register_mugraph 函数中,会遍历 Graph 中的 KN_CUSTOMIZED_OP 操作符。
- 对于每个操作符,它会从 task_configs(即 Graph::task_config)中查找对应的配置(输入数、输出数、TaskType, variant_id)。
- 创建 TaskDesc 结构体,会将获取到的 TaskType 和 variant_id 填入 TaskDesc。
在生成计算图时候,会调用 register_task,实际上是生成CUDA代码,比如:
def embed_layer( self, input: DTensor, # [batch_size, num_spec_tokens] weight: DTensor, # [vocab_size, hidden_size] output: DTensor, # [batch_size, hidden_size] grid_dim: tuple, block_dim: tuple, input_source: int = 0, # 0: all_tokens, 1: input_token ): tb_graph = TBGraph(CyTBGraph(grid_dim, block_dim, 1, 64)) tb_graph.new_input(input, (-1, 1, -1), -1, True) tb_graph.new_input(weight, (1, -1, -1), -1, True) tb_graph.new_input(output, (1, 0, -1), -1, True) self.kn_graph.customized([input, weight, output], tb_graph) # 会生成CUDA代码 self.kn_graph.register_task(tb_graph, "embedding", [input_source]) 当用户调用 Graph::register_task 时,它会获取当前图中最后一个操作符(必须是 KN_CUSTOMIZED_OP),根据传入的 task_type 字符串和参数,调用 TaskRegister 对应的 register_*_task 函数。
注册成功后,它会将任务的输入/输出数量、TaskType 和 variant_id 存储在 Graph 的 task_config 映射中,以 KNOperator* 为键。
register_task的实现位于graph.cc,具体代码如下:
void Graph::register_task(char const *task_type, std::vector<int> params) { std::string name = std::string(task_type); KNOperator const *op = operators.back(); assert(op->op_type == type::KN_CUSTOMIZED_OP); KNCustomizedOp const *customized = static_cast<KNCustomizedOp const *>(op); TaskRegister *task_register = TaskRegister::get_instance(); if (name == "embedding") { int variant_id = task_register->register_embedding_task(customized->bgraph, params); task_config[op] = std::make_tuple(2, 1, TASK_EMBEDDING, variant_id); } else if (name == "rmsnorm_linear") { int variant_id = task_register->register_rmsnorm_linear_task(customized->bgraph, params); task_config[op] = std::make_tuple(3, 1, TASK_RMS_NORM_LINEAR, variant_id); } else if (name == "attention") { int variant_id = task_register->register_attention_task(customized->bgraph, params); task_config[op] = std::make_tuple(7, 1, TASK_ATTENTION_1, variant_id); } else if (name == "single_batch_extend_attention") { int variant_id = task_register->register_single_batch_extend_attention_task( customized->bgraph, params); task_config[op] = std::make_tuple(7, 1, TASK_SINGLE_BATCH_EXTEND_ATTENTION, variant_id); } else if (name == "linear_with_residual") { int variant_id = task_register->register_linear_with_residual_task( customized->bgraph, params); task_config[op] = std::make_tuple(3, 1, TASK_LINEAR_WITH_RESIDUAL, variant_id); } else if (name == "silu_mul_linear_with_residual") { int variant_id = task_register->register_silu_mul_linear_with_residual_task( customized->bgraph, params); task_config[op] = std::make_tuple(3, 1, TASK_SILU_MUL_LINEAR_WITH_RESIDUAL, variant_id); } else if (name == "argmax") { task_config[op] = std::make_tuple(1, 1, TASK_ARGMAX, 0); } else if (name == "argmax_partial") { int variant_id = task_register->register_arrrgmax_partial_task(customized->bgraph, params); task_config[op] = std::make_tuple(1, 2, TASK_ARGMAX_PARTIAL, variant_id); } else if (name == "argmax_reduce") { int variant_id = task_register->register_argmax_reduce_task(customized->bgraph, params); task_config[op] = std::make_tuple(2, 1, TASK_ARGMAX_REDUCE, variant_id); } else if (name == "allreduce") { task_config[op] = std::make_tuple(2, 1, TASK_ALLREDUCE, 0); } else if (name == "find_ngram_partial") { int variant_id = task_register->register_find_ngram_partial_task( customized->bgraph, params); task_config[op] = std::make_tuple(1, 1, TASK_FIND_NGRAM_PARTIAL, variant_id); } else if (name == "find_ngram_global") { int variant_id = task_register->register_find_ngram_global_task( customized->bgraph, params); task_config[op] = std::make_tuple(2, 1, TASK_FIND_NGRAM_GLOBAL, variant_id); } else if (name == "target_verify_greedy") { int variant_id = task_register->register_target_verify_greedy_task( customized->bgraph, params); task_config[op] = std::make_tuple(2, 1, TASK_TARGET_VERIFY_GREEDY, variant_id); } } 以register_embedding_task为例,其代码如下:
int TaskRegister::register_embedding_task(threadblock::Graph const &bgraph, std::vector<int> const ¶ms) { assert(params.size() == 1); // params[0]: input source (0: tokens, 1: input_token) int batch_size = 0, output_size = 0, output_stride = 0; std::vector<tb::TBInputOp *> input_ops; std::vector<tb::TBInputOp *> output_ops; int num_inputs = 2; int num_outputs = 1; assert(bgraph.operators.size() == (size_t)num_inputs + num_outputs); for (auto const &op : bgraph.operators) { assert(op->op_type == mirage::type::TB_INPUT_OP); if (input_ops.size() < (size_t)num_inputs) { input_ops.push_back(static_cast<tb::TBInputOp *>(op)); } else { output_ops.push_back(static_cast<tb::TBInputOp *>(op)); } } assert(output_ops[0]->output_tensors[0].num_dims == 2); batch_size = output_ops[0]->output_tensors[0].dim[0]; output_size = output_ops[0]->output_tensors[0].dim[1]; kn::KNInputOp *kn_input_op = static_cast<kn::KNInputOp *>(output_ops[0]->dtensor.owner_op); output_stride = static_cast<int>(kn_input_op->input_strides[0]); mirage::transpiler::CodeKeeper code; code.inc_indent(); code.e("kernel::embedding_kernel<bfloat16, $, $, $>(", batch_size, output_size, output_stride); if (params[0] == 0) { code.e(" runtime_config.tokens + runtime_config.step[0], "); } else if (params[0] == 1) { code.e(" task_desc.inputs[0].base_ptr,"); } code.e(" task_desc.inputs[1].base_ptr,"); code.e(" task_desc.outputs[0].base_ptr);"); return register_task_variant(TASK_EMBEDDING, code.to_string()); } 最终算子embedding_kernel定义如下:
namespace kernel { template <typename T, int BATCH_SIZE, int CHUNK_SIZE, int OUTPUT_DIM_SIZE> __device__ __forceinline__ void embedding_kernel(void const *__restrict__ input_ptr, void const *__restrict__ embedding_ptr, void *__restrict__ output_ptr) { int64_t const *__restrict__ input_ids = static_cast<int64_t const *>(input_ptr); T const *__restrict__ embedding = static_cast<T const *>(embedding_ptr); T *__restrict__ output = static_cast<T *>(output_ptr); #pragma unroll for (int batch_idx = 0; batch_idx < BATCH_SIZE; batch_idx++) { int64_t wordIdx = input_ids[batch_idx]; if (wordIdx >= 0) { #pragma unroll for (int i = threadIdx.x; i < CHUNK_SIZE; i += NUM_THREADS) { output[batch_idx * OUTPUT_DIM_SIZE + i] = embedding[wordIdx * OUTPUT_DIM_SIZE + i]; } } else { // TODO: This might not be necessary for (int i = threadIdx.x; i < CHUNK_SIZE; i += NUM_THREADS) { // writing 0 to output output[batch_idx * OUTPUT_DIM_SIZE + i] = T(0.0f); } } } } } // namespace kernel 2.2 注册代码
上述代码TaskRegister::register_embedding_task 调用了 register_task_variant 函数来对all_task_variants 进行设置。TaskRegister:register_*_task 函数(如 register_embedding_task, register_custom_task 等)会根据 TaskBlock::Graph 和参数生成特定的 CUDA 调用代码字符串,并将其注册到 all_task_variants 中,返回该变体在向量中的索引(即 variant_id)。
TaskRegister 单例:
mirage::runtime::TaskRegister 是一个单例类,负责管理和注册所有可能的任务变体代码。它内部维护一个映射:std::map<runtime::TaskType, std::vector<std::string> all_task_variants>。
all_task_variants 的作用是:存储和管理不同类型任务的代码变体。
- 键是任务类型(TaskType),task_type 指定了任务的大类(例如 TASK_EMBEDDING, TASK_ATTENTION_1, TASK_LINEAR_WITH_RESIDUAL 等)。
- 值是该类型任务的代表变体列表。
- all_task_variants为每种任务类型维护一个代码变体集合。在register_task_variant中,会检查是否存在相同的代码变体,避免重复存储。这样可以允许同一种任务类型有不同的实现方式。variant_id 指定了同一任务类型下的具体变体(因为同一逻辑任务可能有多种不同的实现或参数配置)。
即,all_task_variants这个映射将每个 TaskType 关联到一个字符串向量,向量中的每个字符串代表该任务类型的一个具体实现代码(通常是以字符串形式生成的 CUDA kernel 调用代码)。
register_task_variant函数
register_task_variant函数代码如下:
int TaskRegister::register_task_variant(runtime::TaskType type, std::string const &code) { std::vector<std::string> &variants = all_task_variants[type]; for (size_t i = 0; i < variants.size(); i++) { if (variants[i] == code) { return (int)(i); } } // Add a new variant variants.push_back(code); return (int)(variants.size() - 1); } 2.3 获取代码
回忆下,在生成任务图时,会做如下操作。
- 在 runtime.cc 的 register_mugraph 函数中,会遍历 Graph 中的 KN_CUSTOMIZED_OP 操作符。
- 对于每个操作符,它会从 task_configs(即 Graph::task_config)中查找对应的配置(输入数、输出数、TaskType, variant_id)。
- 创建 TaskDesc 结构体,会将获取到的 TaskType 和 variant_id 填入 TaskDesc。
运行时获取代码的过程如下:
- 当持久化内核(persistent kernel)运行时,执行到某个 TaskDesc,它会根据其 task_type 和 variant_id进行操作。
- task_type 指定了任务的大类(例如 TASK_EMBEDDING, TASK_ATTENTION_1, TASK_LINEAR_WITH_RESIDUAL 等)。
- variant_id 指定了同一任务类型下的具体变体(因为同一逻辑任务可能有多种不同的实现或参数配置)。
- 在 TaskRegister::all_task_variants 中找到对应的任务类型向量。
- 使用 variant_id 作为索引,从该向量中取出预先生成好的 CUDA kernel 调用代码字符串。
- 这个字符串通常会被编译成实际的 kernel 函数(可能通过 JIT 编译或预先编译的库),然后通过 CUDA API(如 cudaLaunchKernel 或类似的封装)来执行。
0x03 生成任务图
3.1 入口
persistent_kernel.py 的 compile 函数会调用kn_graph.generate_task_graph来生成任务图,即从计算图生成cu文件。
def compile( self, **kwargs, ): output_dir = kwargs.get("output_dir", None) MIRAGE_ROOT, INCLUDE_PATH, DEPS_PATH = get_key_paths() tempdir_obj = tempfile.TemporaryDirectory() tempdir = tempdir_obj.name results = self.kn_graph.generate_task_graph(num_gpus=self.world_size, my_gpu_id=self.mpi_rank) generate_task_graph的代码如下:
def generate_task_graph(self, num_gpus: int, my_gpu_id: int): return self.cygraph.generate_task_graph(num_gpus, my_gpu_id) 3.2 runtime.cc主体
generate_task_graph 调用register_mugraph来进行转换(建立event和task),调用print_task_graph把代码转换出来。
TaskGraphResult Graph::generate_task_graph(int _num_gpus, int _my_gpu_id) { std::vector<TaskDesc> all_tasks; std::vector<EventDesc> all_events; std::vector<TaskId> first_tasks; int num_gpus, my_gpu_id; std::map<kernel::KNOperator *, std::map<dim3, TaskId, Dim3Comparator>> all_task_maps; num_gpus = _num_gpus; my_gpu_id = _my_gpu_id; // add the termination event to the event lists EventDesc e(EVENT_TERMINATION, 1, 0, 0); all_events.push_back(e); TaskDesc t(TASK_TERMINATE, 0 /*variant_id*/); all_tasks.push_back(t); register_mugraph(*this, num_gpus, my_gpu_id, all_tasks, all_events, first_tasks, all_task_maps, task_config); assert(sanity_check(*this, all_tasks, all_events, first_tasks)); return print_task_graph(*this, num_gpus, my_gpu_id, all_tasks, all_events, first_tasks, all_task_maps, task_config, io_config, true /*use_json_format*/); } 这些代码都位于runtime.cc。
3.2.1 runtime.cc的功能
runtime.cc本质是转译器,将高级内核图转换为可以在持久化内核运行时系统中执行的低级任务图表示。
runtime.cc和persistent_kernel.py共同构成了Mirage系统中持久化内核执行系统的核心部分。
- runtime.cc:C++实现,负责底层的任务图生成、事件管理和代码生成。
- persistent_kernel.py:Python实现,提供高层接口和抽象,用于定义和配置持久化内核的数据流关系。
persistent_kernel.py中定义的内核配置和图结构会被传递给runtime.cc,runtime.cc会使用这些信息生成实际的CUDA代码和任务图。两者的协同工作流程如下:
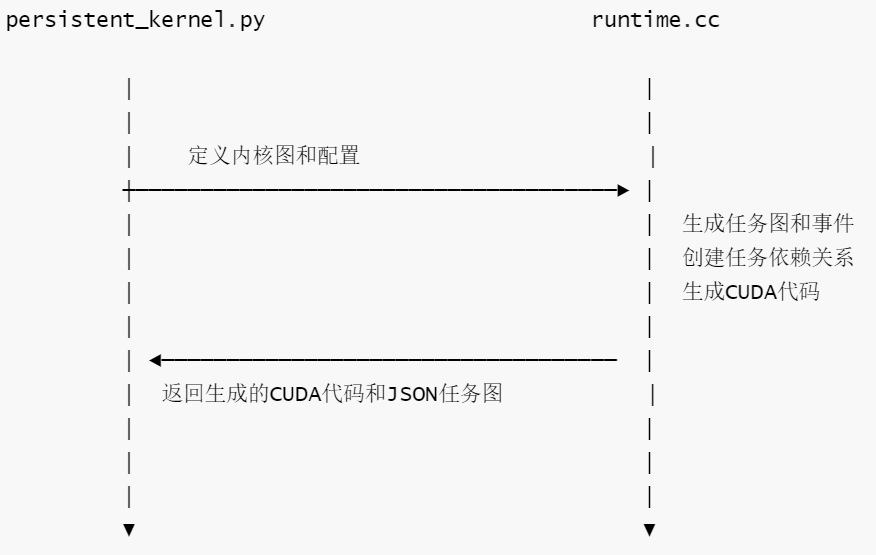
具体交互点如下:
- 任务配置传递。
- persistent_kernel.py的配置通过task_config传递给runtime.cc
- runtime.cc的register_mugraph函数使用这些配置来创建任务
- I/O配置传递
- persistent_kernel.py定义的I/O配置通过io_config传递给runtime.cc
- runtime.cc的print_task_graph函数使用这些配置来生成正确的内存分配代码。
- 代码生成
- runtime.cc的print_task_graph函数生成实际的CUDA代码,生成的代码例如
_init_persistent_kernel和_execute_task函数,这些生成的函数会被persistent_kernel.py使用,来执行实际的内核
- runtime.cc的print_task_graph函数生成实际的CUDA代码,生成的代码例如
- 事件和任务管理
- runtime.cc负责创建和管理事件及任务之间的依赖关系,这些事件(如EVENT_LAUNCH_TASKS)在两个文件中都 被使用。
3.2.2 runtime.cc总体流程
runtime.cc总体流程如下:
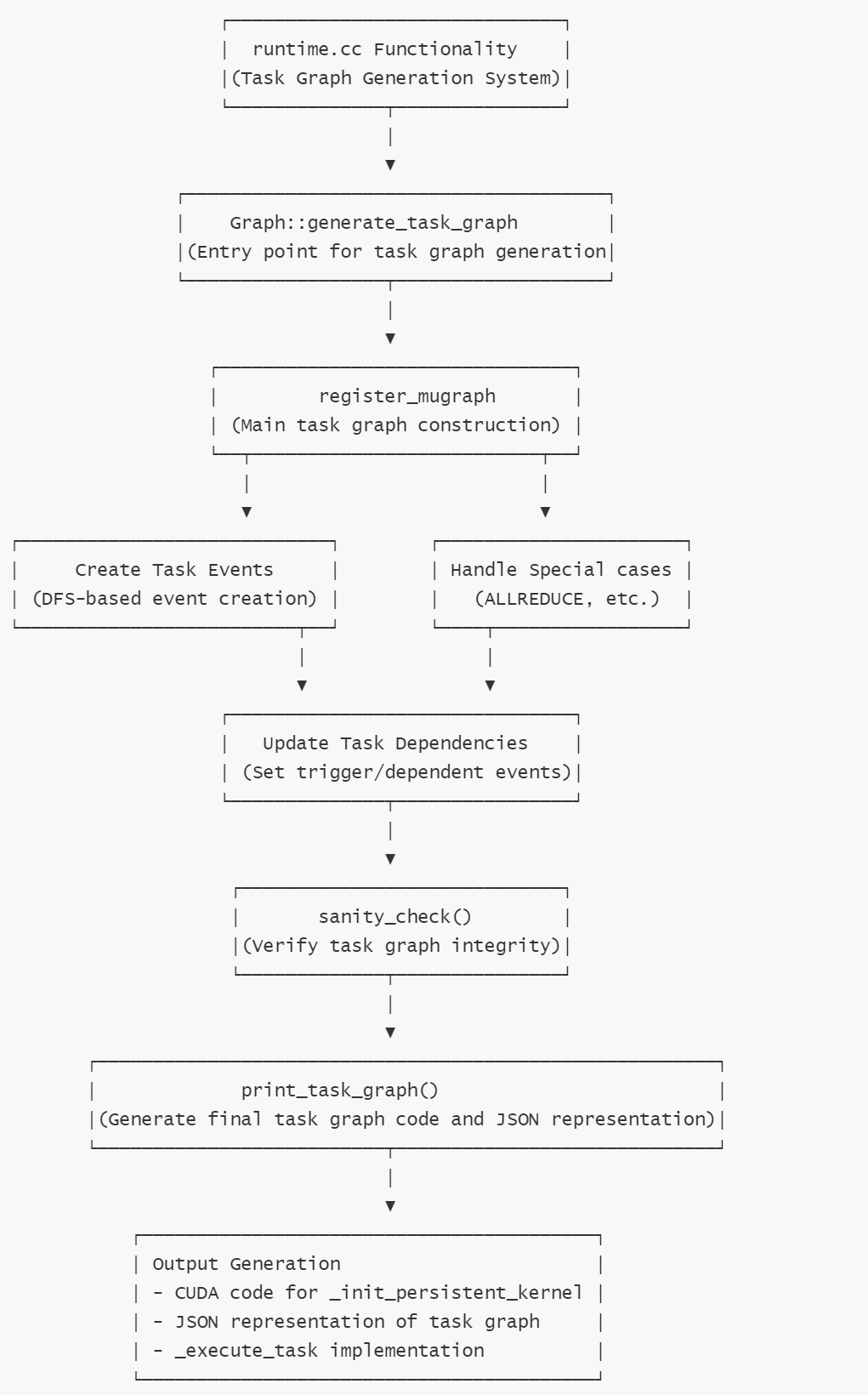
3.2.3 runtime.cc的具体函数
具体函数如下:
- generate_task_graph:主入口点,协调整个任务图的生成过程。
- register_mugraph:核心函数,负责:
1 将内核图转换为任务和事件,即TaskDesc和EventDesc序列
2 处理特殊操作如ALLREDUCE。
3 使用事件设置任务间的正确依赖关系。
4 根据任务数量确定适当的事件类型。
5 建立操作符到任务ID的映射关系 - dfs_create_events_add_tasks :递归函数,负责:
1 使用深度优先搜索方法创建事件和任务。
2 处理多维任务分区。
3 在生成者和消费者任务之间分配正确的依赖关系。 - sanity_check():验证函数,负责:
1 确保所有任务都能被执行。
2 验证所有事件都能被触发。 - print_task_graph:输出生成函数,负责:
1 创建用于初始化持久化内核的CUDA代码
2 生成任务图的JSON表示
3 生成执行任务的设备函数
3.3 建立依赖关系
register_mugraph函数完成了从内核图(由KNOperator组成)到可执行的任务图的关键转换过程:
- 图结构转换:将 KNOperator 图转换为 TaskDesc 和 EventDesc 序列
- 依赖关系建立:通过事件机制建立任务间的依赖关系
- 分布式支持:特殊处理 ALLREDUCE 等分布式操作
- 任务映射:建立操作符到任务ID的映射关系
- 资源配置:为运行时执行准备必要的任务和事件描述
register_mugraph函数是连接计算图定义和实际 GPU 执行的重要桥梁。
3.3.1 流程
具体流程如下:
- 初始化任务图结构
- 添加开始任务和事件来启动依赖任务。
- 遍历图中所有操作符。
- 特殊处理ALLREDUCE操作等分布式操作。
- 创建NVSHMEM复制任务用于跨GPU数据传输
- 创建REDUCE任务用于规约操作。
- 为每个操作创建任务描述
- 创建操作间依赖事件。
- 特殊处理ALLREDUCE操作等分布式操作。
- 更新触发事件。
其中, num_shared_tensors 变量的作用时统计当前操作符与前一个操作符之间共享的张量数量。当找到共享变量时,会记录下相关的映射信息,这些信息会在后续创建事件和任务时会使用。

3.3.2 结果
register_mugraph生成的主要结果为:
- 任务描述列表all_tasks:
- 包含所有需要执行的任务描述(TaskDesc)
- 每个任务包含任务类型、变体ID、输入输出张量等描述信息。
- 任务按照执行顺序排列。
- 事件描述列表all_events:
- 包含所有事件的描述(EventDesc)。
- 每个事件描述包含事件类型、触发任务数量、任务ID范围等。
- 控制任务间的依赖关系和执行顺序。
- 首任务列表 first_tasks
- 包含任务图中第一批可以执行的任务ID
- 任务映射表 all_tasks_maps
- 映射每个操作符到其对应的任务ID映射表
- 用于定位特定操作符生成的任务。
后续print_task_graph会利用这些生成结果。
3.3.3 代码
register_mugraph具体代码如下:
void register_mugraph( // 接受一个kernel图,GPU数量,当前GPU ID,以及任务和事件相关容器 mirage::kernel::Graph const &graph, int num_gpus, int my_gpu_id, std::vector<TaskDesc> &all_tasks, std::vector<EventDesc> &all_events, std::vector<TaskId> &first_tasks, std::map<kernel::KNOperator *, std::map<dim3, TaskId, Dim3Comparator>> &all_task_maps, std::unordered_map<kn::KNOperator const *, std::tuple<int, int, TaskType, int>> const &task_configs) { // push a begin-graph task and a event to launch dependent asks // 添加一个开始任务图的事件和任务,即初始化任务图结构 { EventDesc e(EVENT_LAUNCH_DEPENDENT_TASKS, 1, 0, 0); TaskDesc t(TASK_BEGIN_TASK_GRAPH, 0 /*variant_id*/); // 设置任务触发事件ID t.trigger_event = get_event_id(my_gpu_id, all_events.size(), false); all_tasks.push_back(t); all_events.push_back(e); } // 保存前一个操作的输出操作符和映射关系 std::vector<tb::TBInputOp *> pre_output_ops; kn::KNCustomizedOp const *pre_op = nullptr; std::map<dim3, TaskId, Dim3Comparator> pre_task_map; // 遍历图中所有的操作符 for (auto const &op : graph.operators) { // 跳过输入操作符 if (op->op_type == type::KNOperatorType::KN_INPUT_OP) { continue; } // 获取当前操作的任务配置 std::tuple<int, int, TaskType, int> task_config = task_configs.find(op)->second; // 获取当前操作的任务映射 std::map<dim3, TaskId, Dim3Comparator> cur_task_map; assert(op->op_type == type::KNOperatorType::KN_CUSTOMIZED_OP); // Customized op // 将操作转换为自定义操作类型 kn::KNCustomizedOp const *cur_op = dynamic_cast<kn::KNCustomizedOp const *>(op); // 获取线程块图 tb::Graph const &bgraph = cur_op->bgraph; dim3 bid; // 存储任务描述的向量 std::vector<TaskDesc> tasks; // 存储输入输出操作符 std::vector<tb::TBInputOp *> input_ops; std::vector<tb::TBInputOp *> output_ops; // 从配置中获取输入输出数量和任务类型 int num_inputs = std::get<0>(task_config); int num_outputs = std::get<1>(task_config); TaskType task_type = std::get<2>(task_config); int variant_id = std::get<3>(task_config); // 确保操作符数量为输出输出之和 assert(bgraph.operators.size() == (size_t)num_inputs + num_outputs); // 分离输入输出操作符 for (auto const &op : bgraph.operators) { assert(op->op_type == mirage::type::TB_INPUT_OP); if (input_ops.size() < (size_t)num_inputs) { input_ops.push_back(static_cast<tb::TBInputOp *>(op)); } else { output_ops.push_back(static_cast<tb::TBInputOp *>(op)); } } // Specical handling for ALLREDUCE if (task_type == TASK_ALLREDUCE) { // Shouldn't have AllReduce when num_gpus == 1 assert(num_gpus > 1); // 需要多个GPU assert(input_ops.size() == 2); // 确保输入输出数量正确 assert(output_ops.size() == 1); // To simplify the implementation, asserting that // produce/consumer must have the same partition int num_shared_tensors = 0; int3 input_map, output_map; // 查找共享张量并获取映射关系 for (auto const &input : input_ops) { for (auto const &output : pre_output_ops) { if (input->dtensor.guid == output->dtensor.guid) { input_map = input->input_map; output_map = output->input_map; num_shared_tensors++; } } } assert(num_shared_tensors == 1); // 确保有一个共享张量 assert(input_map == output_map); // 确保映射关系相同且网格维度一致 assert(bgraph.grid_dim == pre_op->bgraph.grid_dim); dim3 bid; // 存储ALLGather前任务映射 std::map<dim3, std::map<int, TaskId>, Dim3Comparator> ag_pre_task_map; // 遍历所有线程块维度 for (bid.x = 0; bid.x < bgraph.grid_dim.x; bid.x++) { for (bid.y = 0; bid.y < bgraph.grid_dim.y; bid.y++) { for (bid.z = 0; bid.z < bgraph.grid_dim.z; bid.z++) { // event_desc_0 is the trigger_event of previous_task // event_desc_1 is the trigger_event of allgather // 创建事件描述,用于触发前一个任务 EventDesc event_desc_0; event_desc_0.event_type = EVENT_LAUNCH_TASKS; event_desc_0.num_triggers = 1; event_desc_0.first_task_id = all_tasks.size(); event_desc_0.last_task_id = all_tasks.size() + num_gpus - 1; // 确保前一个任务映射中存在当前块 assert(pre_task_map.find(bid) != pre_task_map.end()); int task_id = pre_task_map.find(bid)->second; // 设置前一个任务的触发事件 all_tasks[task_id].trigger_event = get_event_id(my_gpu_id, all_events.size(), false); all_events.push_back(event_desc_0); // Step 1: create (num_gpus - 1) tasks for allgather std::map<int, TaskId> pre_tasks; for (int tgt_gpu_id = 0; tgt_gpu_id < num_gpus; tgt_gpu_id++) { if (tgt_gpu_id == my_gpu_id) { continue; // 跳过当前GPU } // 创建 TASK_NVSHMEM_COPY 复制任务 TaskDesc task(TASK_NVSHMEM_COPY, 0 /*variant_id*/); // task.trigger_event = get_event_id( // tgt_gpu_id, all_events.size(), true /*nvshmem_event*/); // Initialize input tensors to the task { TensorDesc desc; assert(input_ops[0]->output_tensors.size() == 1); tb::STensor stensor = input_ops[0]->output_tensors[0]; desc.num_dims = stensor.num_dims; desc.data_type = stensor.data_type; for (int d = stensor.num_dims - 1; d >= 0; d--) { desc.dim[d] = stensor.dim[d]; desc.stride[d] = (d == stensor.num_dims - 1) ? 1 : desc.stride[d + 1] * input_ops[0]->dtensor.dim[d + 1]; } task.inputs[task.num_inputs++] = desc; } // Initialize output tensors to the task { TensorDesc desc; assert(input_ops[1]->output_tensors.size() == 1); tb::STensor stensor = input_ops[1]->output_tensors[0]; desc.num_dims = stensor.num_dims; desc.data_type = stensor.data_type; for (int d = stensor.num_dims - 1; d >= 0; d--) { desc.dim[d] = stensor.dim[d]; desc.stride[d] = (d == stensor.num_dims - 1) ? 1 : desc.stride[d + 1] * input_ops[1]->dtensor.dim[d + 1]; } task.outputs[task.num_outputs++] = desc; } all_tasks.push_back(task); pre_tasks[tgt_gpu_id] = all_tasks.size() - 1; } // for tgt_gpu_id ag_pre_task_map[bid] = pre_tasks; } // for bid.z } // for bid.y } // for bid.x // 遍历所有线程块维度,处理reduce 任务 for (bid.x = 0; bid.x < bgraph.grid_dim.x; bid.x++) { for (bid.y = 0; bid.y < bgraph.grid_dim.y; bid.y++) { for (bid.z = 0; bid.z < bgraph.grid_dim.z; bid.z++) { // event_desc_1 is the trigger_event of allgather // 创建allgather 的触发事件 EventDesc event_desc_1; event_desc_1.event_type = EVENT_LAUNCH_TASKS; event_desc_1.first_task_id = all_tasks.size(); event_desc_1.last_task_id = all_tasks.size() + 1; event_desc_1.num_triggers = num_gpus - 1; // 确保存在当前任务映射 assert(ag_pre_task_map.find(bid) != ag_pre_task_map.end()); std::map<int, TaskId> pre_tasks = ag_pre_task_map.find(bid)->second; // 设置所有前任务的触发事件 for (auto const &t : pre_tasks) { all_tasks[t.second].trigger_event = get_event_id(t.first, all_events.size(), true); } all_events.push_back(event_desc_1); // Step 2: create a task for reduce TaskDesc task(TASK_REDUCE, 0 /*variant_id*/); // 初始化输入张量 for (int i = 0; i < 2; i++) { TensorDesc desc; tb::STensor stensor = input_ops[i]->output_tensors[0]; desc.num_dims = stensor.num_dims; desc.data_type = stensor.data_type; for (int d = stensor.num_dims - 1; d >= 0; d--) { desc.dim[d] = stensor.dim[d]; desc.stride[d] = (d == stensor.num_dims - 1) ? 1 : desc.stride[d + 1] * input_ops[1]->dtensor.dim[d + 1]; } task.inputs[task.num_inputs++] = desc; } // Create output tensor { TensorDesc desc; tb::STensor stensor = output_ops[0]->output_tensors[0]; desc.num_dims = stensor.num_dims; desc.data_type = stensor.data_type; for (int d = stensor.num_dims - 1; d >= 0; d--) { desc.dim[d] = stensor.dim[d]; desc.stride[d] = (d == stensor.num_dims - 1) ? 1 : desc.stride[d + 1] * output_ops[0]->dtensor.dim[d + 1]; } task.inputs[task.num_outputs++] = desc; all_tasks.push_back(task); // Update current task map // 当前任务映射 cur_task_map[bid] = all_tasks.size() - 1; } } } } // 更新前操作相关变量 pre_output_ops = output_ops; pre_op = cur_op; pre_task_map = cur_task_map; all_task_maps.emplace(op, cur_task_map); continue; } // Step 1: add all tasks based on their blockIdx // (bid.x, bid.y, bid.z) ordering // 根据 blockIdx 添加所有任务 (bid.x, bid.y, bid.z)的顺序 for (bid.x = 0; bid.x < bgraph.grid_dim.x; bid.x++) { for (bid.y = 0; bid.y < bgraph.grid_dim.y; bid.y++) { for (bid.z = 0; bid.z < bgraph.grid_dim.z; bid.z++) { TaskDesc task(task_type, variant_id); // 创建任务描述 // Initialize input tensors to the task for (auto const &input : input_ops) { // 初始化任务的输入张量 TensorDesc desc; assert(input->output_tensors.size() == 1); tb::STensor stensor = input->output_tensors[0]; desc.num_dims = stensor.num_dims; desc.data_type = stensor.data_type; for (int d = stensor.num_dims - 1; d >= 0; d--) { desc.dim[d] = stensor.dim[d]; desc.stride[d] = (d == stensor.num_dims - 1) ? 1 : desc.stride[d + 1] * input->dtensor.dim[d + 1]; } task.inputs[task.num_inputs++] = desc; } // Initialize output tensors to the task for (auto const &output : output_ops) { // 初始化任务的输出张量 TensorDesc desc; assert(output->output_tensors.size() == 1); tb::STensor stensor = output->output_tensors[0]; desc.num_dims = stensor.num_dims; desc.data_type = stensor.data_type; for (int d = stensor.num_dims - 1; d >= 0; d--) { desc.dim[d] = stensor.dim[d]; desc.stride[d] = (d == stensor.num_dims - 1) ? 1 : desc.stride[d + 1] * output->dtensor.dim[d + 1]; } task.outputs[task.num_outputs++] = desc; } tasks.push_back(task); } } } // Step 2: create events between operators // 在操作符之间创建事件 if (pre_op == nullptr) { // 如果是第一个操作符,添加到first_tasks dim3 bid; for (bid.x = 0; bid.x < bgraph.grid_dim.x; bid.x++) { for (bid.y = 0; bid.y < bgraph.grid_dim.y; bid.y++) { for (bid.z = 0; bid.z < bgraph.grid_dim.z; bid.z++) { cur_task_map[bid] = all_tasks.size(); int offset = bid.x * bgraph.grid_dim.y * bgraph.grid_dim.z + bid.y * bgraph.grid_dim.z + bid.z; first_tasks.push_back(all_tasks.size()); all_tasks.push_back(tasks[offset]); } } } } else { // Step 2.1: analyze dependencies between thread blocks of the two ops // 分析两个操作之间线程块的依赖关系 std::vector<int> producer_partition(mirage::config::MAX_TENSOR_DIMS, 1); std::vector<int> consumer_partition(mirage::config::MAX_TENSOR_DIMS, 1); int num_shared_tensors = 0; int3 input_map, output_map; // 查找共享张量并获取映射关系 for (auto const &input : input_ops) { for (auto const &output : pre_output_ops) { if (input->dtensor.guid == output->dtensor.guid) { input_map = input->input_map; output_map = output->input_map; num_shared_tensors++; } } } // assert that their is at least a single tensor shared between ops assert(num_shared_tensors >= 1); // 确保至少有一个共享张量 // 设置生产者和消费者的分区 for (int d = 0; d < mirage::config::MAX_TENSOR_DIMS; d++) { if (d == input_map.x) { consumer_partition[d] = bgraph.grid_dim.x; } if (d == input_map.y) { consumer_partition[d] = bgraph.grid_dim.y; } if (d == input_map.z) { consumer_partition[d] = bgraph.grid_dim.z; } if (d == output_map.x) { producer_partition[d] = pre_op->bgraph.grid_dim.x; } if (d == output_map.y) { producer_partition[d] = pre_op->bgraph.grid_dim.y; } if (d == output_map.z) { producer_partition[d] = pre_op->bgraph.grid_dim.z; } } // Step 2.2: create events and add tasks 创建事件并添加任务 // number of events is the product of gcd of producer/consumer std::vector<int> event_dims(mirage::config::MAX_TENSOR_DIMS, 1); for (int d = 0; d < mirage::config::MAX_TENSOR_DIMS; d++) { event_dims[d] = std::gcd(producer_partition[d], consumer_partition[d]); } // 利用深度优先搜索创建事件和添加任务 dfs_create_events_add_tasks(0, /*depth*/ my_gpu_id, /*my_gpu_id*/ event_dims, /*event_dims*/ input_map, /*input_map*/ output_map, /*output_map*/ bgraph.grid_dim, /*consumer_grid_dim*/ pre_op->bgraph.grid_dim, /*producer_grid_dim*/ dim3(0, 0, 0), /*consumer_lo_bid*/ bgraph.grid_dim, /*consumer_hi_bid*/ dim3(0, 0, 0), /*producer_lo_bid*/ pre_op->bgraph.grid_dim, /*producer_hi_bid*/ all_events, all_tasks, tasks, /*cur_op_tasks*/ pre_task_map, /*pre_task_map*/ cur_task_map /*cur_task_map)*/); } pre_output_ops = output_ops; pre_op = cur_op; pre_task_map = cur_task_map; all_task_maps.emplace(op, cur_task_map); } // Update the trigger event for all tasks in pre_task_map for (auto const &it : pre_task_map) { all_tasks[it.second].trigger_event = get_event_id(my_gpu_id, all_events.size(), false /*nvshmem_event*/); } // 添加任务图结束事件 all_events.push_back( EventDesc(EVENT_END_OF_TASK_GRAPH, pre_task_map.size(), 0, 0)); // Prelaunch all tasks at the begining of an iteration // 迭代开始时,预启动所有任务 all_events[1].first_task_id = 2; all_events[1].last_task_id = all_tasks.size(); for (size_t e = 2; e < all_events.size(); e++) { // 对于任务启动事件,将其转换为空事件 if (all_events[e].event_type == EVENT_LAUNCH_TASKS || all_events[e].event_type == EVENT_LAUNCH_MASSIVE_TASKS) { all_events[e].event_type = EVENT_EMPTY; // 为相关任务设置依赖事件 for (size_t t = all_events[e].first_task_id; t < all_events[e].last_task_id; t++) { all_tasks[t].dependent_event = get_event_id(my_gpu_id, e, false /*nvshmem_event*/); } } } } 3.4 输出代码
print_task_graph包括两部分。
- 代码生成:在print_task_graph中生成完整的CUDA源文件。
- 文件输出:将生成的CUDA代码写入.cu文件供后续编译使用。
上述方式允许系统根据计算图结构动态生成优化的CUDA kernel代码。

3.4.1 逻辑
print_task_graph接受register_mugraph生成的所有关键数据结构:
- all_tasks:包含所有任务描述的向量。
- all_events:包含所有事件描述的向量。
- first_tasks:包含第一批任务ID的向量。
- all_task_maps:操作符到任务的映射表。
print_task_graph生成的CUDA代码包括:
- 任务图构造函数 construct_task_graph
- 任务和事件的初始化代码 _init_persistent_kernel。
- 内存分配代码(CUDA,NVSHMEM张量)
- _execute_task
print_task_graph生成的JSON包括
- 从task_graph.json文件读取任务信息
- 解析任务输入输出张量描述
- 重建完整的任务结构。
print_task_graph 利用如下信息生成任务依赖关系。
- all_tasks中的trigger_event和dependent_event字段
- all_events中的事件触发关系
- first_tasks确定任务图的入口点。
3.4.2 代码
print_task_graph具体代码如下:
TaskGraphResult print_task_graph( // 函数参数:内核图、GPU数量、当前GPU ID、所有任务描述、所有事件描述、首任务列表 mirage::kernel::Graph const &graph, int num_gpus, int my_gpu_id, std::vector<TaskDesc> const &all_tasks, std::vector<EventDesc> const &all_events, std::vector<TaskId> const &first_tasks, // 所有操作符到任务映射的映射 std::map<kernel::KNOperator *, std::map<dim3, TaskId, Dim3Comparator>> const &all_task_maps, // 操作符到任务设置的映射 std::unordered_map<kn::KNOperator const *, std::tuple<int, int, TaskType, int>> const &task_configs, // 输入输出配置映射 std::map<mirage::type::GuidType, IODesc> const &io_configs, bool use_json_format) { using mirage::runtime::IODesc; // 创建代码生成器实例 mirage::transpiler::CodeKeeper code; mirage::transpiler::CodeKeeper tgbody; tgbody.inc_indent(); // 添加必要的头文件包含 code.e("#include "persistent_kernel.cuh""); if (use_json_format) { code.e("#include <nlohmann/json.hpp>"); code.e("#include <fstream>"); code.e("#include <filesystem>"); code.e("using json = nlohmann::json;"); } // 添加运行时命名空间声明 code.e("using namespace mirage::runtime;"); // 生成获取事件ID的函数 code.e("size_t get_event_id(int my_gpu_id, size_t event_pos, bool " "nvshmem_event) {"); code.e("size_t event_id = ((static_cast<size_t>(my_gpu_id) << 32) | " "event_pos);"); code.e("if (nvshmem_event) {"); code.e("event_id = event_id | EVENT_NVSHMEM_TAG;"); code.e("}"); code.e("return event_id;"); code.e("}"); code.e(""); // function that loads json file and generates task graph // 如果使用JSON格式,生成从JSON文件构造人物图的函数 if (use_json_format) { code.e("void construct_task_graph(int num_gpus,"); code.e(" int my_gpu_id,"); code.e(" std::vector<TaskDesc> &all_tasks,"); code.e(" std::vector<EventDesc> &all_events,"); code.e(" std::vector<TaskId> &first_tasks,"); code.e(" std::map<std::string, void*> const " "&all_tensors) {"); code.e("std::filesystem::path file_path(__FILE__);"); code.e("std::ifstream " "json_file(file_path.parent_path().string()+"/task_graph.json");"); code.e("nlohmann::json json_task_graph;"); code.e("json_file >> json_task_graph;"); // load tasks // 加载任务 code.e("for (json const &task : json_task_graph["all_tasks"]) {"); code.e("TaskDesc task_desc(static_cast<TaskType>(task.at("task_type")),"); code.e(" task.at("variant_id"));"); code.e("if (task.at("trigger_event").is_number_integer()) {"); code.e("task_desc.trigger_event = task.at("trigger_event").get<unsigned " "long long int>();"); code.e("}"); code.e("else {"); code.e("assert(false);"); code.e("}"); code.e("if (task.at("dependent_event").is_number_integer()) {"); code.e("task_desc.dependent_event = " "task.at("dependent_event").get<unsigned long long int>();"); code.e("}"); code.e("else {"); code.e("assert(false);"); code.e("}"); // load inputs 加载输入张量 code.e("task_desc.num_inputs = 0;"); code.e("for (json const &tensor : task["inputs"]) {"); code.e("TensorDesc input;"); code.e("std::string name = tensor.at("base_ptr").get<std::string>();"); code.e("assert(all_tensors.find(name) != all_tensors.end());"); code.e("off_t offset = tensor.at("offset").get<off_t>();"); code.e("input.base_ptr = static_cast<char*>(all_tensors.at(name))+offset;"); code.e( "assert(tensor.at("dims").size() == tensor.at("strides").size());"); code.e("input.num_dims = tensor.at("dims").size();"); code.e("input.data_type = tensor.at("data_type").get<int>();"); code.e("for (int i = 0; i < input.num_dims; i++) {"); code.e("input.dim[i] = tensor["dims"][i].get<int>();"); code.e("input.stride[i] = tensor["strides"][i].get<int>();"); code.e("}"); code.e("task_desc.inputs[task_desc.num_inputs++] = input;"); code.e("}"); // load outputs 加载输出张量 code.e("task_desc.num_outputs = 0;"); code.e("for (json const &tensor : task["outputs"]) {"); code.e("TensorDesc output;"); code.e("std::string name = tensor.at("base_ptr").get<std::string>();"); code.e("assert(all_tensors.find(name) != all_tensors.end());"); code.e("off_t offset = tensor.at("offset").get<off_t>();"); code.e( "output.base_ptr = static_cast<char*>(all_tensors.at(name))+offset;"); code.e( "assert(tensor.at("dims").size() == tensor.at("strides").size());"); code.e("output.num_dims = tensor.at("dims").size();"); code.e("output.data_type = tensor.at("data_type").get<int>();"); code.e("for (int i = 0; i < output.num_dims; i++) {"); code.e("output.dim[i] = tensor["dims"][i];"); code.e("output.stride[i] = tensor["strides"][i];"); code.e("}"); code.e("task_desc.outputs[task_desc.num_outputs++] = output;"); code.e("}"); code.e("all_tasks.push_back(task_desc);"); code.e("}"); // load events 加载事件 code.e("for (json const &e : json_task_graph["all_events"]) {"); code.e("EventType event_type = " "static_cast<EventType>(e.at("event_type").get<int>());"); code.e("int num_triggers = e.at("num_triggers").get<int>();"); code.e("int first_task_id = e.at("first_task_id").get<int>();"); code.e("int last_task_id = e.at("last_task_id").get<int>();"); code.e("all_events.push_back(EventDesc(event_type, num_triggers, " "first_task_id, last_task_id));"); code.e("}"); // load first tasks 加载首任务 code.e("for (json const &t : json_task_graph["first_tasks"]) {"); code.e("first_tasks.push_back(t.get<int>());"); code.e("}"); code.e("}"); code.e(""); } // 生成初始化持久内核的函数 code.e( "static void _init_persistent_kernel(std::vector<TaskDesc> &all_tasks,"); code.e(" std::vector<EventDesc> " "&all_events,"); code.e(" std::vector<TaskId> &first_tasks,"); code.e(" int num_gpus,"); code.e(" int my_gpu_id) {"); code.e("assert(num_gpus = $);", num_gpus); if (use_json_format) { // 创建张量映射 code.e("std::map<std::string, void*> all_tensors;"); } for (auto const &iter : io_configs) { // 输出输入输出配置 IODesc desc = iter.second; switch (desc.type) { case IODesc::TorchTensor: { // 处理Torch张量 code.e("char *$ = (char*)($);", desc.name, desc.torch_data_ptr); if (use_json_format) { code.e("all_tensors["$"] = $;", desc.name, desc.name); } break; } case IODesc::FusedTorchTensor: { // 处理融合张量 for (auto const &sdesc : desc.sub_descs) { code.e("char *$ = (char*)($);", sdesc.name, sdesc.torch_data_ptr); if (use_json_format) { code.e("all_tensors["$"] = $;", sdesc.name, sdesc.name); } } break; } case IODesc::CUDAMallocTensor: { // 处理CUDA分配张量 code.e("void *$;", desc.name); size_t size = mirage::type::get_datatype_size( static_cast<type::DataType>(desc.tensor.data_type)); for (int i = 0; i < desc.tensor.num_dims; i++) { size *= desc.tensor.dim[i]; } code.e("cudaMalloc(&$, $);", desc.name, size); if (use_json_format) { code.e("all_tensors["$"] = $;", desc.name, desc.name); } break; } case IODesc::NVSHMEMMallocTensor: { // 处理NVSHMEM分配张量 size_t size = mirage::type::get_datatype_size( static_cast<type::DataType>(desc.tensor.data_type)); for (int i = 0; i < desc.tensor.num_dims; i++) { size *= desc.tensor.dim[i]; } code.e("void *$ = nvshmem_malloc($);", desc.name, size); if (use_json_format) { code.e("all_tensors["$"] = $;", desc.name, desc.name); } break; } default: assert(false); } } json json_task_graph = { // 创建jSON任务图对象 {"all_tasks", {}}, {"all_events", {}}, {"first_tasks", {}}}; // generate task[0] 终止任务 { tgbody.e("all_tasks.push_back(TaskDesc(TASK_TERMINATE));"); json_task_graph["all_tasks"].push_back( json{{"task_type", TASK_TERMINATE}, {"variant_id", 0}, {"inputs", {}}, {"outputs", {}}, {"trigger_event", EVENT_INVALID_ID}, {"dependent_event", EVENT_INVALID_ID}}); } // generate task[1] 任务图任务, { tgbody.e("all_tasks.push_back(TaskDesc(TASK_BEGIN_TASK_GRAPH));"); json_task_graph["all_tasks"].push_back( json{{"task_type", TASK_BEGIN_TASK_GRAPH}, {"variant_id", 0}, {"inputs", {}}, {"outputs", {}}, {"trigger_event", get_event_id(my_gpu_id, 1 /*event_pos*/, false /*is_nvshmem*/)}, {"dependent_event", EVENT_INVALID_ID}}); } // generate all other tasks 生成所有其它任务 size_t task_pos = 2; for (auto const &op : graph.operators) { if (op->op_type == type::KNOperatorType::KN_INPUT_OP) { continue; } assert(op->op_type == type::KNOperatorType::KN_CUSTOMIZED_OP); std::tuple<int, int, TaskType, int> task_config = task_configs.find(op)->second; assert(all_task_maps.find(op) != all_task_maps.end()); std::map<dim3, TaskId, Dim3Comparator> const &task_map = all_task_maps.find(op)->second; // Customized op kn::KNCustomizedOp const *cur_op = dynamic_cast<kn::KNCustomizedOp const *>(op); tb::Graph const &bgraph = cur_op->bgraph; dim3 bid; std::vector<tb::TBInputOp *> input_ops; std::vector<tb::TBInputOp *> output_ops; int num_inputs = std::get<0>(task_config); // int num_outputs = std::get<1>(task_config); TaskType task_type = std::get<2>(task_config); // 收集输入和输出操作 for (auto const &op : bgraph.operators) { assert(op->op_type == mirage::type::TB_INPUT_OP); if (input_ops.size() < (size_t)num_inputs) { input_ops.push_back(static_cast<tb::TBInputOp *>(op)); } else { output_ops.push_back(static_cast<tb::TBInputOp *>(op)); } } if (task_type == TASK_ALLREDUCE) { // 处理特殊任务 for (bid.x = 0; bid.x < bgraph.grid_dim.x; bid.x++) { for (bid.y = 0; bid.y < bgraph.grid_dim.y; bid.y++) { for (bid.z = 0; bid.z < bgraph.grid_dim.z; bid.z++) { // To perform allreduce, we first launch (num_gpus-1) tasks for // allgather for (int tgt_gpu_id = 0; tgt_gpu_id < num_gpus; tgt_gpu_id++) { if (tgt_gpu_id == my_gpu_id) { continue; } TaskDesc task_desc = all_tasks[task_pos]; assert(task_desc.task_type == TASK_NVSHMEM_COPY); tgbody.e("// task[$]", task_pos); tgbody.e("{"); tgbody.e("TaskDesc task_desc(static_cast<TaskType>($));", task_desc.task_type); bool is_nvshmem_event = ((task_desc.trigger_event & EVENT_NVSHMEM_TAG) > 0); assert(is_nvshmem_event); assert(task_desc.dependent_event != EVENT_INVALID_ID); assert(task_desc.num_inputs == 1); assert(task_desc.num_outputs == 1); json json_task = {{"task_type", task_desc.task_type}, {"variant_id", task_desc.variant_id}, {"inputs", {}}, {"outputs", {}}, {"trigger_event", task_desc.trigger_event}, {"dependent_event", task_desc.dependent_event}}; off_t offset = 0; // Add input int3 input_map = input_ops[0]->input_map; IODesc io_desc = io_configs.find(input_ops[0]->dtensor.guid)->second; if (input_map.x >= 0) { size_t block_size = io_desc.tensor.dim[input_map.x] / bgraph.grid_dim.x; offset += block_size * bid.x * io_desc.tensor.stride[input_map.x]; } if (input_map.y >= 0) { size_t block_size = io_desc.tensor.dim[input_map.y] / bgraph.grid_dim.y; offset += block_size * bid.y * io_desc.tensor.stride[input_map.y]; } if (input_map.z >= 0) { size_t block_size = io_desc.tensor.dim[input_map.z] / bgraph.grid_dim.z; offset += block_size * bid.z * io_desc.tensor.stride[input_map.z]; } tgbody.e("TensorDesc input$;", 0); tgbody.e("input$.base_ptr = static_cast<char*>($) + $;", 0, io_desc.name, offset * type::get_datatype_size(static_cast<type::DataType>( io_desc.tensor.data_type))); tgbody.e("input$.num_dims = $;", 0, task_desc.inputs[0].num_dims); tgbody.e( "input$.data_type = $;", 0, task_desc.inputs[0].data_type); json json_dims = json::array(), json_strides = json::array(); for (int d = 0; d < task_desc.inputs[0].num_dims; d++) { tgbody.e( "input$.dim[$] = $;", 0, d, task_desc.inputs[0].dim[d]); tgbody.e("input$.stride[$] = $;", 0, d, task_desc.inputs[0].stride[d]); json_dims.push_back(task_desc.inputs[0].dim[d]); json_strides.push_back(task_desc.inputs[0].stride[d]); } tgbody.e("task_desc.inputs[$] = input$;", 0, 0); json_task["inputs"].push_back(json{ {"base_ptr", io_desc.name}, {"offset", offset * type::get_datatype_size(static_cast<type::DataType>( io_desc.tensor.data_type))}, {"data_type", task_desc.inputs[0].data_type}, {"dims", json_dims}, {"strides", json_strides}}); // Add nvshmem_copy output // Note that nvshmem_copy's output is stored in input_ops[1] offset = my_gpu_id * input_ops[0]->dtensor.num_elements(); int3 output_map = input_ops[1]->input_map; io_desc = io_configs.find(input_ops[1]->dtensor.guid)->second; if (output_map.x >= 0) { size_t block_size = io_desc.tensor.dim[output_map.x] / bgraph.grid_dim.x; offset += block_size * bid.x * io_desc.tensor.stride[output_map.x]; } if (output_map.y >= 0) { size_t block_size = io_desc.tensor.dim[output_map.y] / bgraph.grid_dim.y; offset += block_size * bid.y * io_desc.tensor.stride[output_map.y]; } if (output_map.z >= 0) { size_t block_size = io_desc.tensor.dim[output_map.z] / bgraph.grid_dim.z; offset += block_size * bid.z * io_desc.tensor.stride[output_map.z]; } tgbody.e("TensorDesc output$;", 0); tgbody.e("output$.base_ptr = static_cast<char*>($) + $;", 0, io_desc.name, offset * type::get_datatype_size(static_cast<type::DataType>( io_desc.tensor.data_type))); tgbody.e( "output$.num_dims = $;", 0, task_desc.outputs[0].num_dims); tgbody.e( "output$.data_type = $;", 0, task_desc.outputs[0].data_type); json_dims = json::array(); json_strides = json::array(); for (int d = 0; d < task_desc.outputs[0].num_dims; d++) { tgbody.e( "output$.dim[$] = $;", 0, d, task_desc.outputs[0].dim[d]); tgbody.e("output$.stride[$] = $;", 0, d, task_desc.outputs[0].stride[d]); json_dims.push_back(task_desc.outputs[0].dim[d]); json_strides.push_back(task_desc.outputs[0].stride[d]); } tgbody.e("task_desc.outputs[$] = output$;", 0, 0); json_task["outputs"].push_back(json{ {"base_ptr", io_desc.name}, {"offset", offset * type::get_datatype_size(static_cast<type::DataType>( io_desc.tensor.data_type))}, {"data_type", task_desc.outputs[0].data_type}, {"dims", json_dims}, {"strides", json_strides}}); tgbody.e("all_tasks.push_back(task_desc);"); json_task_graph["all_tasks"].push_back(json_task); tgbody.e("}"); task_pos++; } // for tgt_gpu_id } // for bid.z } // for bid.y } // for bid.x } // if task_type == TASK_ALLREDUCE // 为每个线程块生成任务 for (bid.x = 0; bid.x < bgraph.grid_dim.x; bid.x++) { for (bid.y = 0; bid.y < bgraph.grid_dim.y; bid.y++) { for (bid.z = 0; bid.z < bgraph.grid_dim.z; bid.z++) { TaskId task_id = task_map.at(bid); TaskDesc task_desc = all_tasks[task_pos]; assert(task_desc.task_type == task_type || task_type == TASK_ALLREDUCE); assert(task_pos == (task_id & 0xffffffff)); tgbody.e("// task[$]", task_pos); tgbody.e("{"); tgbody.e("TaskDesc task_desc(static_cast<TaskType>($));", task_desc.task_type); size_t gpu_id = ((task_desc.trigger_event >> 32) & 0xffff); size_t event_pos = (task_desc.trigger_event & 0xffffffff); bool is_nvshmem_event = ((task_desc.trigger_event & EVENT_NVSHMEM_TAG) > 0); assert(gpu_id == my_gpu_id); assert(!is_nvshmem_event); json json_task; // 创建任务描述 json_task = {{"task_type", task_desc.task_type}, {"variant_id", task_desc.variant_id}, {"inputs", {}}, {"outputs", {}}, {"trigger_event", task_desc.trigger_event}, {"dependent_event", task_desc.dependent_event}}; for (int i = 0; i < task_desc.num_inputs; i++) { // 处理输入张量 if (input_ops[i]->dtensor == kernel::DTensor::EMPTY_TENSOR) { json json_dims = json::array(); json json_strides = json::array(); json_task["inputs"].push_back( json{{"base_ptr", "nullptr"}, {"offset", 0}, {"data_type", type::DT_UNKNOWN}, {"dims", json_dims}, {"strides", json_strides}}); continue; } off_t offset = 0; int num_dims = input_ops[i]->dtensor.num_dims; int3 input_map = input_ops[i]->input_map; IODesc io_desc = io_configs.find(input_ops[i]->dtensor.guid)->second; assert(input_ops[i]->dtensor.owner_op->op_type == type::KN_INPUT_OP); if (io_desc.type == IODesc::FusedTorchTensor) { // 处理融合张量 // Currently assert that we fuse the 0-th dim (i.e., 0) int fused_group_size = 0; std::vector<int> group_sizes; for (auto const &sub_desc : io_desc.sub_descs) { assert(sub_desc.tensor.num_dims == num_dims); assert(sub_desc.tensor.dim[0] % io_desc.num_groups == 0); int my_group_size = sub_desc.tensor.dim[0] / io_desc.num_groups; fused_group_size += my_group_size; group_sizes.push_back(my_group_size); } assert(io_desc.tensor.dim[0] == fused_group_size * io_desc.num_groups); assert(io_desc.tensor.num_dims == num_dims); int fused_dim_off = 0; if (input_map.x == 0) { fused_dim_off = io_desc.tensor.dim[0] / bgraph.grid_dim.x * bid.x; } if (input_map.y == 0) { fused_dim_off = io_desc.tensor.dim[0] / bgraph.grid_dim.y * bid.y; } if (input_map.z == 0) { fused_dim_off = io_desc.tensor.dim[0] / bgraph.grid_dim.z * bid.z; } int fused_dim_off_in_group = fused_dim_off % fused_group_size; size_t index = 0; while (index < group_sizes.size()) { if (fused_dim_off_in_group >= group_sizes[index]) { fused_dim_off_in_group -= group_sizes[index]; index++; } else { break; } } IODesc sub_desc = io_desc.sub_descs[index]; int fused_dim_off_subtensor = fused_dim_off / fused_group_size * group_sizes[index] + fused_dim_off_in_group; // Assert that it is within range assert(fused_dim_off_subtensor < sub_desc.tensor.dim[0]); if (input_map.x > 0) { size_t block_size = sub_desc.tensor.dim[input_map.x] / bgraph.grid_dim.x; offset += block_size * bid.x * sub_desc.tensor.stride[input_map.x]; } else if (input_map.x == 0) { offset += fused_dim_off_subtensor * sub_desc.tensor.stride[input_map.x]; } if (input_map.y > 0) { size_t block_size = sub_desc.tensor.dim[input_map.y] / bgraph.grid_dim.y; offset += block_size * bid.y * sub_desc.tensor.stride[input_map.y]; } else if (input_map.y == 0) { offset += fused_dim_off_subtensor * sub_desc.tensor.stride[input_map.y]; } if (input_map.z > 0) { size_t block_size = sub_desc.tensor.dim[input_map.z] / bgraph.grid_dim.z; offset += block_size * bid.z * sub_desc.tensor.stride[input_map.z]; } else if (input_map.z == 0) { offset += fused_dim_off_subtensor * sub_desc.tensor.stride[input_map.z]; } tgbody.e("TensorDesc input$;", i); tgbody.e("input$.base_ptr = static_cast<char*>($) + $;", i, sub_desc.name, offset * type::get_datatype_size(static_cast<type::DataType>( sub_desc.tensor.data_type))); tgbody.e("input$.num_dims = $;", i, task_desc.inputs[i].num_dims); tgbody.e( "input$.data_type = $;", i, task_desc.inputs[i].data_type); json json_dims = json::array(); json json_strides = json::array(); for (int d = 0; d < task_desc.inputs[i].num_dims; d++) { tgbody.e( "input$.dim[$] = $;", i, d, task_desc.inputs[i].dim[d]); tgbody.e( "input$.stride[$] = $;", i, d, sub_desc.tensor.stride[d]); json_dims.push_back(task_desc.inputs[i].dim[d]); json_strides.push_back(sub_desc.tensor.stride[d]); } tgbody.e("task_desc.inputs[$] = input$;", i, i); json_task["inputs"].push_back(json{ {"base_ptr", sub_desc.name}, {"offset", offset * type::get_datatype_size(static_cast<type::DataType>( sub_desc.tensor.data_type))}, {"data_type", task_desc.inputs[i].data_type}, {"dims", json_dims}, {"strides", json_strides}}); } else { // Non-fused case, use io_desc if (input_map.x >= 0) { size_t block_size = io_desc.tensor.dim[input_map.x] / bgraph.grid_dim.x; offset += block_size * bid.x * io_desc.tensor.stride[input_map.x]; } if (input_map.y >= 0) { size_t block_size = io_desc.tensor.dim[input_map.y] / bgraph.grid_dim.y; offset += block_size * bid.y * io_desc.tensor.stride[input_map.y]; } if (input_map.z >= 0) { size_t block_size = io_desc.tensor.dim[input_map.z] / bgraph.grid_dim.z; offset += block_size * bid.z * io_desc.tensor.stride[input_map.z]; } tgbody.e("TensorDesc input$;", i); tgbody.e("input$.base_ptr = static_cast<char*>($) + $;", i, io_desc.name, offset * type::get_datatype_size(static_cast<type::DataType>( io_desc.tensor.data_type))); tgbody.e("input$.num_dims = $;", i, task_desc.inputs[i].num_dims); tgbody.e( "input$.data_type = $;", i, task_desc.inputs[i].data_type); json json_dims = json::array(); json json_strides = json::array(); for (int d = 0; d < task_desc.inputs[i].num_dims; d++) { tgbody.e( "input$.dim[$] = $;", i, d, task_desc.inputs[i].dim[d]); tgbody.e("input$.stride[$] = $;", i, d, task_desc.inputs[i].stride[d]); json_dims.push_back(task_desc.inputs[i].dim[d]); json_strides.push_back(task_desc.inputs[i].stride[d]); } tgbody.e("task_desc.inputs[$] = input$;", i, i); json_task["inputs"].push_back(json{ {"base_ptr", io_desc.name}, {"offset", offset * type::get_datatype_size(static_cast<type::DataType>( io_desc.tensor.data_type))}, {"data_type", task_desc.inputs[i].data_type}, {"dims", json_dims}, {"strides", json_strides}}); } } for (int i = 0; i < task_desc.num_outputs; i++) { off_t offset = 0; int3 output_map = output_ops[i]->input_map; IODesc io_desc = io_configs.find(output_ops[i]->dtensor.guid)->second; assert(io_desc.type != IODesc::FusedTorchTensor); if (output_map.x >= 0) { size_t block_size = io_desc.tensor.dim[output_map.x] / bgraph.grid_dim.x; offset += block_size * bid.x * io_desc.tensor.stride[output_map.x]; } if (output_map.y >= 0) { size_t block_size = io_desc.tensor.dim[output_map.y] / bgraph.grid_dim.y; offset += block_size * bid.y * io_desc.tensor.stride[output_map.y]; } if (output_map.z >= 0) { size_t block_size = io_desc.tensor.dim[output_map.z] / bgraph.grid_dim.z; offset += block_size * bid.z * io_desc.tensor.stride[output_map.z]; } tgbody.e("TensorDesc output$;", i); tgbody.e("output$.base_ptr = static_cast<char*>($) + $;", i, io_desc.name, offset * type::get_datatype_size(static_cast<type::DataType>( io_desc.tensor.data_type))); tgbody.e("output$.num_dims = $;", i, task_desc.outputs[i].num_dims); tgbody.e( "output$.data_type = $;", i, task_desc.outputs[i].data_type); json json_dims = json::array(); json json_strides = json::array(); for (int d = 0; d < task_desc.outputs[i].num_dims; d++) { tgbody.e( "output$.dim[$] = $;", i, d, task_desc.outputs[i].dim[d]); tgbody.e("output$.stride[$] = $;", i, d, task_desc.outputs[i].stride[d]); json_dims.push_back(task_desc.outputs[i].dim[d]); json_strides.push_back(task_desc.outputs[i].stride[d]); } tgbody.e("task_desc.outputs[$] = output$;", i, i); json_task["outputs"].push_back(json{ {"base_ptr", io_desc.name}, {"offset", offset * type::get_datatype_size(static_cast<type::DataType>( io_desc.tensor.data_type))}, {"data_type", task_desc.outputs[i].data_type}, {"dims", json_dims}, {"strides", json_strides}}); } tgbody.e("all_tasks.push_back(task_desc);"); tgbody.e("}"); json_task_graph["all_tasks"].push_back(json_task); task_pos++; } } } } assert(task_pos == all_tasks.size()); // 验证任务位置 // Add all events for (auto const &event : all_events) { // 添加所有事件 tgbody.e( "all_events.push_back(EventDesc(static_cast<EventType>($), $, $, $));", event.event_type, event.num_triggers, event.first_task_id, event.last_task_id); json_task_graph["all_events"].push_back( json{{"event_type", event.event_type}, {"num_triggers", event.num_triggers}, {"first_task_id", event.first_task_id}, {"last_task_id", event.last_task_id}}); } // Add first task 添加首任务 for (auto const &task : first_tasks) { tgbody.e("first_tasks.push_back($);", task); json_task_graph["first_tasks"].push_back(task); } if (use_json_format) { // Add nullptr for tensors set as None code.e("all_tensors["nullptr"] = nullptr;"); code.e("construct_task_graph(num_gpus, my_gpu_id, all_tasks, all_events, " "first_tasks, all_tensors);"); } else { code.e(tgbody.to_string()); } code.e("}"); code.e(""); // Generate task implementation 生成任务实现 std::map<TaskType, std::string> task_type_to_name; task_type_to_name[TASK_EMBEDDING] = "TASK_EMBEDDING"; task_type_to_name[TASK_RMS_NORM_LINEAR] = "TASK_RMS_NORM_LINEAR"; task_type_to_name[TASK_ATTENTION_1] = "TASK_ATTENTION_1"; task_type_to_name[TASK_SILU_MUL_LINEAR_WITH_RESIDUAL] = "TASK_SILU_MUL_LINEAR_WITH_RESIDUAL"; task_type_to_name[TASK_LINEAR_WITH_RESIDUAL] = "TASK_LINEAR_WITH_RESIDUAL"; task_type_to_name[TASK_ARGMAX_PARTIAL] = "TASK_ARGMAX_PARTIAL"; task_type_to_name[TASK_ARGMAX_REDUCE] = "TASK_ARGMAX_REDUCE"; task_type_to_name[TASK_FIND_NGRAM_PARTIAL] = "TASK_FIND_NGRAM_PARTIAL"; task_type_to_name[TASK_FIND_NGRAM_GLOBAL] = "TASK_FIND_NGRAM_GLOBAL"; task_type_to_name[TASK_TARGET_VERIFY_GREEDY] = "TASK_TARGET_VERIFY_GREEDY"; task_type_to_name[TASK_SINGLE_BATCH_EXTEND_ATTENTION] = "TASK_SINGLE_BATCH_EXTEND_ATTENTION"; code.e("__device__ __forceinline__"); code.e("void _execute_task(TaskDesc const& task_desc,"); code.e(" RuntimeConfig const &runtime_config) {"); TaskRegister *task_register = TaskRegister::get_instance(); bool first_task = true; for (auto const &task : task_register->all_task_variants) { // 为每个任务变体生成执行代码 for (size_t variant_id = 0; variant_id < task.second.size(); variant_id++) { std::string cond = first_task ? "if" : "else if"; assert(task_type_to_name.find(task.first) != task_type_to_name.end()); code.e("$ (task_desc.task_type == $ && task_desc.variant_id == $) {", cond, task_type_to_name[task.first], variant_id); code.e("$", task.second[variant_id]); code.e("}"); first_task = false; } } code.e("}"); // Write json to output file // std::ofstream out("task_graph.json"); // out << json_task_graph.dump(2); // out.close(); TaskGraphResult result; // 创建结果对象并返回 result.cuda_code = code.to_string(); result.json_file = json_task_graph.dump(2); return result; } 0xFF 参考
如何评价CMU将LLM转化为巨型内核的Mirage Persistent Kernel(MPK)工作?
Mirage: A Multi-Level Superoptimizer for Tensor Programs 简记 尘伊光
OSDI2025论文笔记:Mirage: A Multi-Level Superoptimizer for Tensor Programs 画饼充饥
Mirage: A Compiler for High-Performance Tensor Programs on GPUs
https://mirage-project.readthedocs.io/en/latest/mugraph.html
https://mirage-project.readthedocs.io/en/latest/transpiler.html




![洛谷 P11345 [KTSC 2023 R2] 基地简化 题解](http://www.itfaba.com/wp-content/themes/kemi/timthumb.php?src=http://www.itfaba.com/wp-content/themes/kemi/img/random/2.jpg&w=218&h=124&zc=1)
