
MPK(Mirage Persistent Kernel)源码笔记(3)--- 系统接口
0x00 概述
因为转译系统需要通过persistent_kernel.py来完成,所以我们先介绍persistent_kernel.py。
persistent_kernel.py是 Persistent Kernel的Python接口,本质是Python到CUDA持久化内核系统的桥梁,允许用户用python定义复杂的计算图,然后在GPU上高效执行。主要功能包括:
- 持久化内核管理。提供了 PersistentKernel 作为接口类来管理和执行持久化CUDA内核。
- 内核编译。将Python定义的计算图编译为CUDA代码并生成共享库。集成了nvcc编译器来编译生成CUDA代码。
- 内核执行。提供接口来初始化、启动和执行持久化内核。
此外,在 HARD_CODE 定义的C函数是底层入口点,具体如下:
- init_func:初始化内核。
- launch_func:启动内核执行。会调用到 launch_persistent_kernel。
- finalize_func:清理和终止内核。
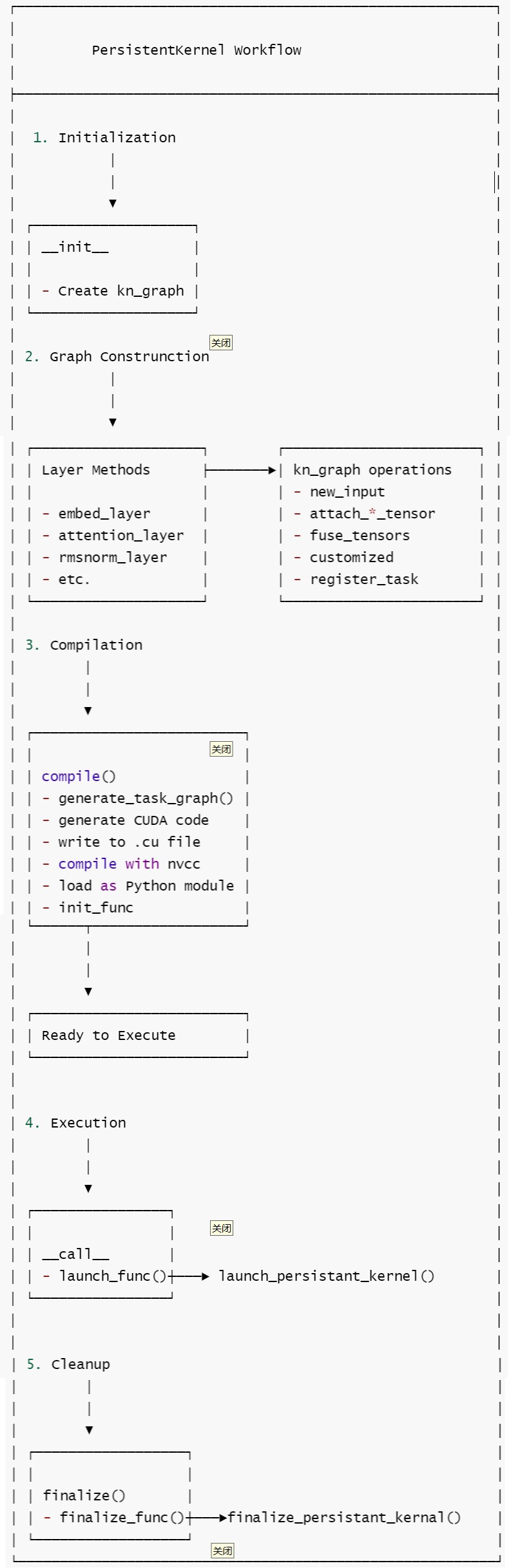
0x01 流程
persistent_kernel.py的工作流程如下:
- 初始化:创建 PersistentKernel 类。
- 定义计算图:使用各种layer方法(如embed_layer、attention_layer等)定义计算图。
- 编译。调用compile()方法生成和编译CUDA内核。
- 生成任务图。
- 创建CUDA代码。
- 调用nvcc编译器。
- 创建Python绑定模块
- 执行:调用call()方法启动内核执行。 self.launch_func()
- 清理:调用finalize()方法或者自动析构。
具体如下图所示。
0x02 初始化
初始化函数会创建 PersistentKernel 类。
因为此处只是系统接口,大部分有意义的工作在C++代码中实现,因此此处略过。
class PersistentKernel: def __init__( self, world_size: int, mpi_rank: int, num_workers: int, num_local_schedulers: int, num_remote_schedulers: int, max_seq_length: int, eos_token_id: int64, meta_tensors: list[torch.Tensor], profiler_tensor: torch.Tensor, spec_decode_config: SpecDecodeConfig ): self.__finalized__ = False self._is_compiled = False self.world_size = world_size self.mpi_rank = mpi_rank self.num_workers = num_workers self.num_local_schedulers = num_local_schedulers self.num_remote_schedulers = num_remote_schedulers self.max_seq_length = max_seq_length self.eos_token_id = eos_token_id self.kn_graph = KNGraph(CyKNGraph(disable_fingerprint=True)) self.meta_tensors = meta_tensors self.profiler_tensor = profiler_tensor self.use_nvshmem = True if world_size > 1 else False self.spec_decode_config = spec_decode_config self._spec_decode_handlers = { "promptlookup": self.prompt_lookup_spec_handler, } self._spec_verify_handlers = { "promptlookup": self.prompt_lookup_verify_handler, } 0x03 定义计算图
persistent_kernel.py 使用各种layer方法(如embed_layer、attention_layer等)定义计算图。简易流程如下:
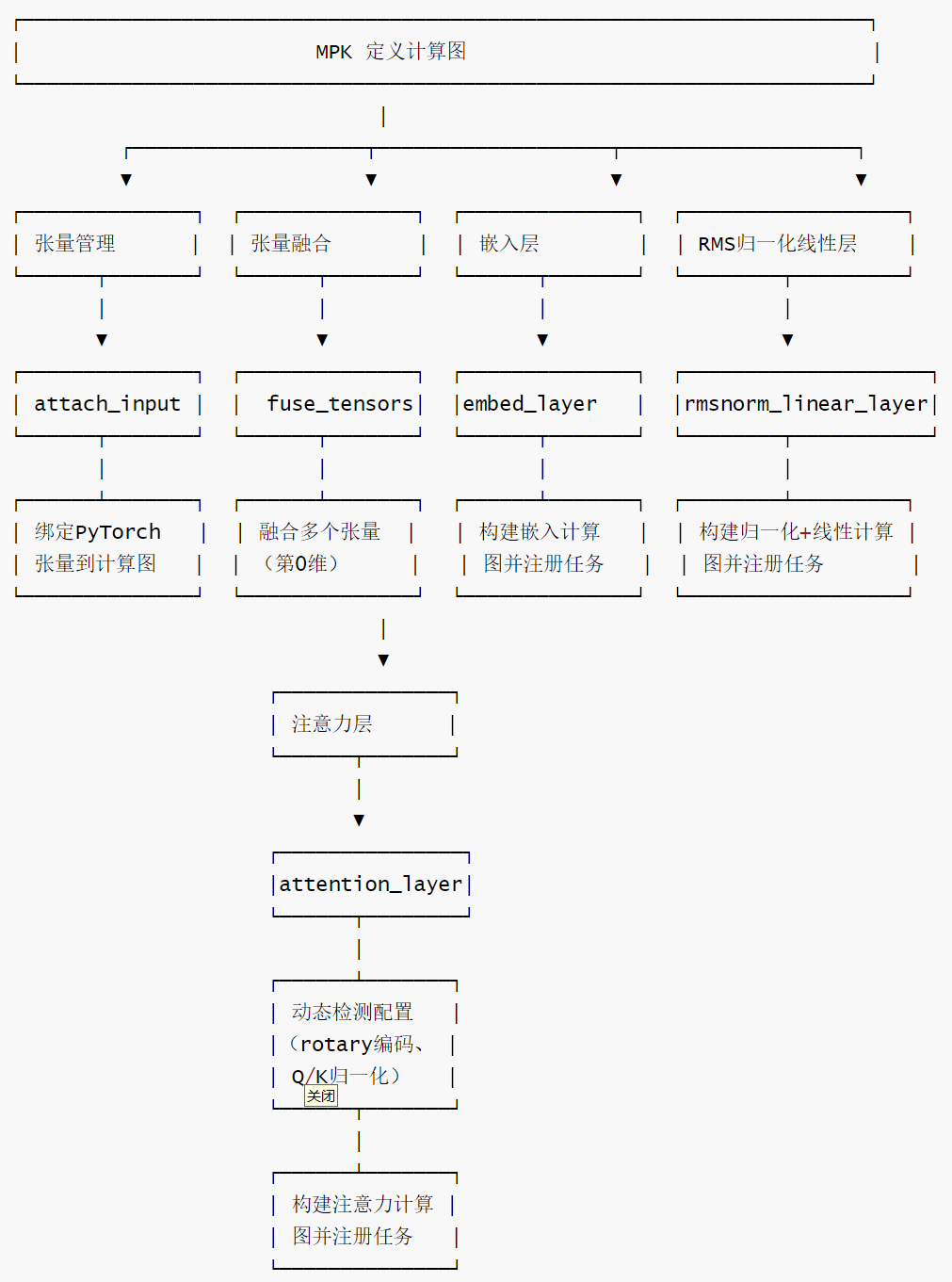
对应的代码举例如下:
def attach_input(self, torch_tensor: torch.Tensor, name: str = None) -> DTensor: """ 将PyTorch张量附加到计算图,创建对应的DTensor(分布式张量)。 参数: torch_tensor: 待附加的PyTorch张量 name: 张量名称(必须指定) 返回: 与输入张量关联的DTensor实例 说明: 仅支持行优先(row-major)内存布局,通过步长校验确保布局正确性 """ # 提取张量维度与步长信息 dims = tuple([d for d in torch_tensor.shape]) strides = tuple([s for s in torch_tensor.stride()]) # 校验是否为行优先布局(高维步长 = 低维步长 × 低维尺寸) for d in range(len(dims) - 1): assert strides[d] == strides[d + 1] * dims[d + 1] # 转换PyTorch数据类型为框架内部 dtype dtype = convert_torch_type_to_dtype(torch_tensor.dtype) # 创建输入张量节点 t = self.kn_graph.new_input(dims=dims, strides=strides, dtype=dtype) # 断言名称非空(当前实现限制) assert name is not None # 将DTensor与PyTorch张量绑定,并注册到计算图 self.kn_graph.attach_torch_tensor(t, torch_tensor, name) return t def new_tensor( self, dims: tuple, strides: tuple = None, dtype: dtype = bfloat16, name: str = None, io_category: str = "cuda_tensor", ) -> DTensor: """ 创建新的DTensor并根据IO类别附加到计算图。 参数: dims: 张量维度元组 strides: 步长元组(默认自动按行优先计算) dtype: 数据类型(默认bfloat16) name: 张量名称(必须指定) io_category: IO类别("cuda_tensor"或"nvshmem_tensor") 返回: 新创建的DTensor实例 说明: 支持CUDA本地张量与NVSHMEM分布式张量两种类型 """ # 若指定步长,校验是否为行优先布局 if strides is not None: for d in range(len(dims) - 1): assert strides[d] == strides[d + 1] * dims[d + 1] # 创建张量节点 t = self.kn_graph.new_input(dims=dims, strides=strides, dtype=dtype) # 断言名称非空(当前实现限制) assert name is not None # 根据IO类别绑定张量到计算图 if io_category == "cuda_tensor": self.kn_graph.attach_cuda_tensor(t, name) # 绑定CUDA张量 elif io_category == "nvshmem_tensor": self.kn_graph.attach_nvshmem_tensor(t, name) # 绑定NVSHMEM分布式张量 else: raise RuntimeError(f"Invalid io_category: {io_category}") return t def fuse_tensors( self, inputs: list[DTensor], fused_dim: int, num_groups: int, name: str = None ) -> DTensor: """ 融合多个张量到单个张量(当前仅支持第0维融合)。 参数: inputs: 待融合的DTensor列表 fused_dim: 融合维度(必须为0) num_groups: 分组数量 name: 融合后张量名称 返回: 融合后的DTensor实例 """ # 当前仅支持第0维融合 assert fused_dim == 0 # 调用计算图的张量融合接口 t = self.kn_graph.fuse_tensors(inputs, fused_dim, num_groups, name) return t def embed_layer( self, input: DTensor, # 输入张量 [batch_size, num_spec_tokens] weight: DTensor, # 嵌入权重 [vocab_size, hidden_size] output: DTensor, # 输出张量 [batch_size, hidden_size] grid_dim: tuple, # CUDA网格维度 block_dim: tuple, # CUDA块维度 input_source: int = 0, # 输入源类型(0: 全 tokens, 1: 输入 token) ): """ 定义嵌入层计算,将输入张量通过嵌入权重映射到隐藏空间。 参数: input: 输入张量 weight: 嵌入权重张量 output: 输出张量(用于存储结果) grid_dim: CUDA kernel的网格维度 block_dim: CUDA kernel的块维度 input_source: 输入源类型标记 说明: 内部创建线程块图(TBGraph),定义输入输出映射关系,并注册为"embedding"任务 """ # 创建线程块图(CyTBGraph为底层实现,64为共享内存大小) tb_graph = TBGraph(CyTBGraph(grid_dim, block_dim, 1, 64)) # 定义输入输出张量的维度映射规则 tb_graph.new_input(input, (-1, 1, -1), -1, True) # 输入张量维度映射 tb_graph.new_input(weight, (1, -1, -1), -1, True) # 权重张量维度映射 tb_graph.new_input(output, (1, 0, -1), -1, True) # 输出张量维度映射 # 将张量与线程块图关联 self.kn_graph.customized([input, weight, output], tb_graph) # 注册嵌入层任务,附加输入源参数 self.kn_graph.register_task(tb_graph, "embedding", [input_source]) def rmsnorm_linear_layer( self, input: DTensor, # 输入张量 weight_norm: DTensor, # 归一化权重 weight_linear: DTensor, # 线性层权重 output: DTensor, # 输出张量 grid_dim: tuple, # CUDA网格维度 block_dim: tuple, # CUDA块维度 ): """ 定义RMS归一化+线性变换组合层。 参数: input: 输入张量(2D) weight_norm: RMS归一化权重(2D) weight_linear: 线性层权重(2D) output: 输出张量(2D) grid_dim: CUDA kernel的网格维度 block_dim: CUDA kernel的块维度 说明: 先对输入执行RMS归一化,再通过线性层变换,输出结果存储到output """ # 校验输入张量维度(当前仅支持2D张量) assert input.num_dims == 2 assert weight_linear.num_dims == 2 assert output.num_dims == 2 # 创建线程块图 tb_graph = TBGraph(CyTBGraph(grid_dim, block_dim, 1, 64)) # 定义输入输出维度映射 tb_graph.new_input(input, (-1, -1, -1), 1, True) # 输入张量 tb_graph.new_input(weight_norm, (-1, -1, -1), 0, True) # 归一化权重 tb_graph.new_input(weight_linear, (0, -1, -1), 1, True) # 线性层权重 tb_graph.new_input(output, (1, -1, -1), -1, True) # 输出张量 # 关联张量与线程块图 self.kn_graph.customized([input, weight_norm, weight_linear, output], tb_graph) # 注册RMS归一化+线性层任务 self.kn_graph.register_task(tb_graph, "rmsnorm_linear") def attention_layer( self, input: DTensor, # 输入张量 (batch_size, fused_outdim / world_size) k_cache: DTensor, # K缓存 (batch_size, seq_len, kv_heads, head_dim) v_cache: DTensor, # V缓存 (batch_size, seq_len, kv_heads, head_dim) q_norm: DTensor, # Q归一化权重 (可选) k_norm: DTensor, # K归一化权重 (可选) cos_pos_embed: DTensor, # 余弦位置编码 (可选) sin_pos_embed: DTensor, # 正弦位置编码 (可选) output: DTensor, # 输出张量 (batch_size, hidden_size / world_size) grid_dim: tuple, # CUDA网格维度 block_dim: tuple, # CUDA块维度 ): """ 定义注意力层计算,支持 rotary 位置编码与 Q/K 归一化。 参数: input: 输入张量(2D) k_cache: 键缓存张量(4D) v_cache: 值缓存张量(4D) q_norm: Q归一化权重(可选,1D) k_norm: K归一化权重(可选,1D) cos_pos_embed: 余弦位置编码(可选,2D) sin_pos_embed: 正弦位置编码(可选,2D) output: 输出张量(2D) grid_dim: CUDA kernel的网格维度 block_dim: CUDA kernel的块维度 说明: 自动检测是否启用 rotary 编码与 Q/K 归一化,动态调整计算逻辑 """ # 校验输入输出张量维度 assert input.num_dims == 2 # (batch_size, fused_outdim / world_size) assert output.num_dims == 2 # (batch_size, hidden_size / world_size) assert k_cache.num_dims == 4 # (batch_size, seq_len, kv_heads, head_dim) assert v_cache.num_dims == 4 # (batch_size, seq_len, kv_heads, head_dim) # 提取注意力头相关参数 head_dim = k_cache.dim(3) # 头维度 num_kv_heads = k_cache.dim(2) # KV头数量 num_q_heads = output.dim(1) // head_dim # Q头数量 # 检测是否启用 rotary 位置编码 rotary_embed = 0 if cos_pos_embed is not None or sin_pos_embed is not None: assert cos_pos_embed.num_dims == 2 # (seq_len, head_dim) assert sin_pos_embed.num_dims == 2 # (seq_len, head_dim) assert cos_pos_embed.dim(1) == head_dim assert sin_pos_embed.dim(1) == head_dim rotary_embed = 1 # 标记启用rotary编码 # 检测是否启用Q/K归一化 qk_norm = 0 if q_norm is not None or k_norm is not None: assert q_norm.num_dims == 1 # (head_dim) assert k_norm.num_dims == 1 # (head_dim) qk_norm = 1 # 标记启用Q/K归一化 assert q_norm.dim(0) == head_dim assert k_norm.dim(0) == head_dim # 注意力层参数列表 params = [num_q_heads, num_kv_heads, qk_norm, rotary_embed] # 创建线程块图 tb_graph = TBGraph(CyTBGraph(grid_dim, block_dim, 1, 64)) # 定义输入输出维度映射 tb_graph.new_input(input, (0, 1, -1), -1, True) # 输入张量 tb_graph.new_input(k_cache, (0, 2, -1), 1, True) # K缓存 tb_graph.new_input(v_cache, (0, 2, -1), 1, True) # V缓存 tb_graph.new_input(q_norm, (-1, -1, -1), -1, True) # Q归一化权重 tb_graph.new_input(k_norm, (-1, -1, -1), -1, True) # K归一化权重 tb_graph.new_input(cos_pos_embed, (-1, -1, -1), -1, True) # 余弦位置编码 tb_graph.new_input(sin_pos_embed, (-1, -1, -1), -1, True) # 正弦位置编码 tb_graph.new_input(output, (0, 1, -1), -1, True) # 输出张量 # 关联所有张量与线程块图 self.kn_graph.customized( [ input, k_cache, v_cache, q_norm, k_norm, cos_pos_embed, sin_pos_embed, output, ], tb_graph, ) # 注册注意力层任务,附加参数 self.kn_graph.register_task(tb_graph, "attention", params) 0x04 编译
persistent_kernel.py的compile 函数主要功能是将定义好的内核图(kernel graph)编译成可执行的 CUDA 代码,并生成一个 Python 共享库(.so 文件),以便在 Python 环境中调用执行,具体如下:
-
生成任务图和 CUDA 代码。
- 调用 self.kn_graph.generate_task_graph 方法,基于当前定义的内核图(KNGraph)生成任务图(task graph)和对应的 CUDA 代码。这一步会根据图中的操作(如矩阵乘法、元素级运算等)生成优化后的 CUDA 实现。
-
准备编译环境。
- 创建临时目录用于存放生成的代码文件和编译产物。
- 将生成的 CUDA 代码写入 .cu 文件。
- 将任务图的 JSON 表示写入文件,便于调试或后续分析。
-
配置编译参数
- 获取 CUDA 编译器(nvcc)路径。
- 确定 Python 头文件路径,以便生成的库可以与 Python 交互。
- 获取 Mirage 框架的头文件和依赖库路径。
- 如果使用 NVSHMEM(多 GPU 通信库),则还需要配置 NVSHMEM 和 MPI 的头文件及库路径。
-
执行编译
- 构建完整的 nvcc 编译命令,包括源文件、包含路径、编译选项、目标架构等。
- 调用 subprocess.check_call 执行编译命令,生成一个 Python 可导入的共享库(.so 文件)。
-
加载编译结果
- 使用 importlib.util.spec_from_file_location 和 importlib.util.module_from_spec动态加载编译生成的 .so 文件作为 Python 模块。
- 从加载的模块中获取初始化、执行和终结函数(init_func, launch_func, finalize_func),并保存为 PersistentKernel 对象的成员变量,供后续调用。
流程图如下:

具体代码如下:
def compile( self, **kwargs, ): # 从关键字参数中获取输出目录,默认为None output_dir = kwargs.get("output_dir", None) # 获取Mirage相关的核心路径(根目录、包含目录、依赖目录) MIRAGE_ROOT, INCLUDE_PATH, DEPS_PATH = get_key_paths() # 创建临时目录用于存放编译过程中的中间文件 tempdir_obj = tempfile.TemporaryDirectory() tempdir = tempdir_obj.name # 生成任务图:根据GPU数量和当前GPU ID划分计算任务 results = self.kn_graph.generate.generate_task_graph(num_gpus=self.world_size, my_gpu_id=self.mpi_rank) # 定义CUDA代码和编译产物的临时路径 cuda_code_path = os.path.join(tempdir, "test.cu") # 生成的CUDA源代码路径 so_path = os.path.join(tempdir, "test.cpython-38-x86_64-linux-gnu.so") # 编译后的的共享库路径 # 定义任务图JSON文件的临时路径 json_file_path = os.path.join(tempdir, "task_graph.json") # 将任务图数据写入JSON文件 with open(json_file_path, "w") as f: f.write(results["json_file"]) # 将生成的CUDA代码与硬编码补充内容合并后写入文件 with open(cuda_code_path, "w") as f: f.write(results["cuda_code"] + HARD_CODE) # 若指定了输出目录,将生成的CUDA代码和JSON文件复制到该目录 if output_dir is not None: os.makedirs(output_dir, exist_ok=True) # 确保输出目录存在(已存在则不报错) shutil.copy(cuda_code_path, os.path.join(output_dir, "test.cu")) # 复制CUDA代码 shutil.copy(json_file_path, os.path.join(output_dir, "task_graph.json")) # 复制任务图JSON # 检查nvcc(CUDA编译器)是否存在 cc = shutil.which("nvcc") if cc is None: # 若未找到nvcc,抛出运行时错误提示用户安装CUDA raise RuntimeError( "nvcc not found. Please make sure you have installed CUDA." ) # 确定Python的默认安装路径方案(适配不同Python版本的API差异) # Python 3.10及以上版本使用get_default_scheme方法 if hasattr(sysconfig, "get_default_scheme"): scheme = sysconfig.get_default_scheme() else: # 旧版本Python使用内部方法_get_default_scheme scheme = sysconfig._get_default_scheme() # 修正Debian系统中的路径方案,确保与系统Python兼容 if scheme == "posix_local": scheme = "posix_prefix" # 获取Python的头文件包含目录(用于编译时链接Python库) py_include_dir = sysconfig.get_paths(scheme=scheme)["include"] # 从环境变量中获取Mirage的安装路径(若已设置) if "MIRAGE_HOME" in os.environ: MIRAGE_HOME_PATH = os.environ.get("MIRAGE_HOME") # 初始化NVSHMEM和MPI相关的路径变量(用于分布式通信) NVSHMEM_INC_PATH = None # NVSHMEM头文件目录 NVSHMEM_LIB_PATH = None # NVSHMEM库文件目录 MPI_INC_PATH = None # MPI头文件目录 MPI_LIB_PATH = None # MPI库文件目录 # 若启用NVSHMEM(NVIDIA共享内存库),配置其相关路径 if self.use_nvshmem: # 配置NVSHMEM头文件路径 if "NVSHMEM_INC_PATH" in os.environ: # 优先使用环境变量中指定的路径 NVSHMEM_INC_PATH = os.environ.get("NVSHMEM_INC_PATH") header_file_path = os.path.join(NVSHMEM_INC_PATH, "nvshmem.h") else: # 未指定则使用默认路径 NVSHMEM_INC_PATH = "/usr/include/nvshmem_12/" header_file_path = os.path.join(NVSHMEM_INC_PATH, "nvshmem.h") # 配置NVSHMEM库文件路径 if "NVSHMEM_LIB_PATH" in os.environ: NVSHMEM_LIB_PATH = os.environ.get("NVSHMEM_LIB_PATH") lib_file_path = os.path.join(NVSHMEM_LIB_PATH, "libnvshmem.a") else: NVSHMEM_LIB_PATH = "/usr/lib/x86_64-linux-gnu/" lib_file_path = os.path.join(NVSHMEM_LIB_PATH, "libnvshmem.a") # 配置MPI头文件路径(NVSHMEM依赖MPI) if "MPI_INC_PATH" in os.environ: MPI_INC_PATH = os.environ.get("MPI_INC_PATH") header_file_path = os.path.join(MPI_INC_PATH, "mpi.h") else: MPI_INC_PATH = "/usr/include/" header_file_path = os.path.join(MPI_INC_PATH, "mpi.h") # 配置MPI库文件路径 if "MPI_LIB_PATH" in os.environ: MPI_LIB_PATH = os.environ.get("MPI_LIB_PATH") lib_file_path = os.path.join(MPI_LIB_PATH, "libmpi.so") else: NVSHMEM_LIB_PATH = "/usr/lib/" lib_file_path = os.path.join(MPI_LIB_PATH, "libmpi.so") # 获取当前GPU的计算能力(如86对应A100,75对应T4等) target_cc = ( torch.cuda.get_device_properties(0).major * 10 + torch.cuda.get_device_properties(0).minor ) # 生成CUDA编译命令 cc_cmd = get_compile_command( target_cc=target_cc, # GPU计算能力 cc=cc, # nvcc编译器路径 file_name=cuda_code_path, # 输入的CUDA源代码 py_include_dir=py_include_dir, # Python头文件目录 mirage_home_path=MIRAGE_HOME_PATH, # Mirage根目录 mirage_inc_path=INCLUDE_PATH, # Mirage头文件目录 mirage_deps_path=DEPS_PATH, # Mirage依赖目录 nvshmem_inc_path=NVSHMEM_INC_PATH, # NVSHMEM头文件目录 nvshmem_lib_path=NVSHMEM_LIB_PATH, # NVSHMEM库目录 mpi_inc_path=MPI_INC_PATH, # MPI头文件目录 mpi_lib_path=MPI_LIB_PATH, # MPI库目录 py_so_path=so_path, # 输出的共享库路径 profiling=True if self.profiler_tensor is not None else False, # 是否启用性能分析 use_nvshmem=self.use_nvshmem, # 是否使用NVSHMEM num_workers=self.num_workers, # 工作线程数量 num_local_schedulers=self.num_local_schedulers, # 本地调度器数量 num_remote_schedulers=self.num_remote_schedulers, # 远程调度器数量 ) # 执行编译命令,生成共享库 subprocess.check_call(cc_cmd) # 动态导入编译生成的共享库 import importlib.util # 创建模块规格:指定模块名称和共享库路径 spec = importlib.util.spec_from_file_location("__mirage_launcher", so_path) # 从规格创建模块 mod = importlib.util.module_from_spec(spec) # 执行模块加载 spec.loader.exec_module(mod) # 绑定模块中的核心函数(初始化、启动、结束) self.init_func = getattr(mod, "init_func") self.launch_func = getattr(mod, "launch_func") self.finalize_func = getattr(mod, "finalize_func") # 打印编译完成提示 print("Finished megakernel compilation...") # 收集元数据张量的内存地址指针 meta_tensors_ptr = [tensor.data_ptr() for tensor in self.meta_tensors] # 获取性能分析缓冲区的内存地址(若启用性能分析) profiler_buffer_ptr = ( self.profiler_tensor.data_ptr() if self.profiler_tensor is not None else 0 ) # 调用初始化函数,传入必要的参数 self.init_func( meta_tensors_ptr, # 元数据张量指针列表 profiler_buffer_ptr, # 性能分析缓冲区指针 self.mpi_rank, # 当前MPI进程编号 self.num_workers, # 工作线程数量 self.num_local_schedulers, # 本地调度器数量 self.num_remote_schedulers, # 远程调度器数量 self.max_seq_length, # 最大序列长度 self.eos_token_id, # 结束符token ID ) # 标记编译完成状态 self._is_compiled = True 总的来说,compile 函数的作用是将用户通过 PersistentKernel API 定义的计算图转换为高度优化的 CUDA 代码,并将其编译为可在当前系统上运行的 Python 模块,从而实现高性能的 GPU 计算。编译成功后,用户可以通过调用 init_func, launch_func, finalize_func 来初始化、执行和清理内核。
0x05 执行
persistent_kernel.py调用call()方法启动内核执行。
def __call__(self, **kwargs): self.launch_func() if self.profiler_tensor is not None: from .profiler_persistent import export_to_perfetto_trace export_to_perfetto_trace( self.profiler_tensor, f"mirage_{self.mpi_rank}.perfetto-trace" ) launch_func()函数会调用launch_persistent_kernel()来启动内核。
static PyObject *launch_func(PyObject *self, PyObject *args) { launch_persistent_kernel(); Py_RETURN_NONE; } 0xFF 参考
如何评价CMU将LLM转化为巨型内核的Mirage Persistent Kernel(MPK)工作?
Mirage: A Multi-Level Superoptimizer for Tensor Programs 简记 尘伊光
OSDI2025论文笔记:Mirage: A Multi-Level Superoptimizer for Tensor Programs 画饼充饥
Mirage: A Compiler for High-Performance Tensor Programs on GPUs
https://mirage-project.readthedocs.io/en/latest/mugraph.html
https://mirage-project.readthedocs.io/en/latest/transpiler.html




![洛谷 P11345 [KTSC 2023 R2] 基地简化 题解](http://www.itfaba.com/wp-content/themes/kemi/timthumb.php?src=http://www.itfaba.com/wp-content/themes/kemi/img/random/1.jpg&w=218&h=124&zc=1)
