
现状
你去检索下读写分离,一大堆告诉你,写,更改,删除,走主数据库,读走从数据库
我要说的是,这个完全错误的
原因
其实但从字面来说,上面也是很有道理的,但是问题就出现在现实上
延迟问题
主从备份,主数据库,从数据库,我们都知道,是往主数据库写入,从数据库自动从主数据库复制数据,但是,这里是有延迟的,而且延迟还不低,不说多吧,100ms是很常见的!当然你服务器牛叉,可以做到1ms,那也不能说他没延迟,只是延迟多少的问题!
最大问题
读写分离最大的问题,不是读写分离如何写,而是如何处理实际情况,比如写入了,更新了,你读取的时候还没有读取到,读取到的是旧的!!!
总结
所以说,如果你看到读写分离,一股脑的用读只走从数据库的,可以直接划走了!
DeepSeek的说法
您举的这个例子太典型了!这正好说明了读写分离不能简单粗暴地按照"所有读走从库"来设计。
您说的这个场景的致命问题
// 邀约注册 + 立即登录场景 public class InvitationService { // 接口1:邀约自动注册(写主库) public async Task<IActionResult> AutoRegisterFromInvitation(string invitationCode) { // 验证邀约码,创建用户(写主库) var user = new User { Username = GenerateUsername(), Password = HashPassword("temp123"), InvitationCode = invitationCode }; _dbContext.Users.Add(user); await _dbContext.SaveChangesAsync(); // 写入主库 // 返回成功,前端自动跳转到登录页 return Ok(new { success = true, userId = user.Id }); } // 接口2:用户立即登录(如果强制走从库就完蛋了!) public async Task<IActionResult> Login(string username, string password) { // 问题:这里如果强制走从库查询 var user = await _readOnlyDbContext.Users .FirstOrDefaultAsync(u => u.Username == username); if (user == null) { // 用户看到:"刚注册成功,现在说用户不存在?" return BadRequest("用户不存在!"); } // 验证密码... return Ok(new { token = GenerateToken(user) }); } } 现实中的连锁问题
1. 新用户注册后立即操作
// 用户注册后立即完善资料 public async Task CompleteProfile(int userId, UserProfile profile) { // 如果这里走从库查询用户 var user = await _readOnlyDbContext.Users.FindAsync(userId); // 可能为null!用户刚注册,从库还没同步 user.Profile = profile; await _dbContext.SaveChangesAsync(); // 又写主库 // 如果user为null,这里直接异常! } 2. 订单创建后立即查询
public async Task<IActionResult> CreateOrder(Order order) { // 创建订单(主库) _dbContext.Orders.Add(order); await _dbContext.SaveChangesAsync(); // 立即返回订单详情给前端 // 如果前端立即调用查询订单接口(走从库) // 可能查不到刚创建的订单! return Ok(new { orderId = order.Id }); } // 前端代码 const createOrder = async () => { await api.post('/orders', orderData); // 创建成功 const result = await api.get(`/orders/${orderId}`); // 立即查询 // 可能返回404!用户:"我刚刚创建的订单呢?" } 正确的解决方案
方案一:基于业务语义的路由
public class SmartConnectionRouter { public bool ShouldUseReadOnlyDb(HttpContext context) { var endpoint = context.GetEndpoint(); // 这些场景必须走主库(即使它们是读操作!) var criticalReadOperations = new[] { "/auth/login", // 登录 "/users/{id}/profile", // 用户详情 "/orders/{id}", // 订单详情 "/payments/status" // 支付状态 }; // 这些场景可以走从库(容忍延迟) var tolerantReadOperations = new[] { "/products/list", // 商品列表 "/articles", // 文章列表 "/statistics/report" // 统计报表 }; var path = context.Request.Path.ToString(); return tolerantReadOperations.Any(p => path.Contains(p)) && !criticalReadOperations.Any(p => path.Contains(p)); } } 方案二:用户会话级别的路由
public class UserAwareConnectionSelector { public string GetConnectionString(HttpContext context) { // 新注册用户:短时间内强制主库 if (context.User.IsNewlyRegistered()) { return "Default"; // 主库 } // 关键操作:强制主库 if (IsCriticalOperation(context)) { return "Default"; // 主库 } // 其他情况:可以从库 return "ReadOnly"; // 从库 } private bool IsCriticalOperation(HttpContext context) { var criticalPaths = new[] { "/auth/", "/users/", "/orders/", "/payments/" }; var path = context.Request.Path.ToString(); return criticalPaths.Any(p => path.StartsWith(p)); } } 方案三:写操作后的读强制主库
public class WriteAwareConnectionMiddleware { public async Task InvokeAsync(HttpContext context, IConnectionStringSelector selector) { // 如果是写操作,设置标记 if (context.Request.Method != "GET") { context.Items["ForceMasterDb"] = true; selector.SetConnectionStringName("Default"); } else { // 读操作:检查是否需要强制主库 var forceMaster = context.Items["ForceMasterDb"] as bool? ?? false; if (forceMaster || IsCriticalReadOperation(context)) { selector.SetConnectionStringName("Default"); } else { selector.SetConnectionStringName("ReadOnly"); } } await _next(context); } } 现实中的妥协
// 实际项目中,我们通常这样做: public class PracticalApproach { // 1. 关键业务路径全部主库 // - 用户认证相关 // - 订单交易相关 // - 支付相关 // - 库存相关 // 2. 非关键业务走从库 // - 商品浏览 // - 内容展示 // - 报表统计 // - 搜索建议 // 3. 新用户特殊处理 // - 注册后30分钟内强制主库 // - 关键操作后短时间内强制主库 } 结论
您说得对!读写分离不能简单地按照"所有读走从库"来设计,必须:
- 理解业务语义 - 哪些读操作对实时性要求高
- 识别数据流 - 写操作后哪些读操作会立即发生
- 接受复杂性 - 路由逻辑会变得复杂,但这是必要的
- 监控和调整 - 根据实际运行情况不断优化路由策略
那种"一刀切"的读写分离方案,在实际业务中会带来很多您提到的这种数据不一致问题。合理的读写分离是艺术,不是简单的技术配置。
PasteForm中的读写方案
由于最近一个项目要考虑读写分离的问题,之前的都比较小,都是直接主库操作,所以对PasteForm的做了一个改版
PasteForm框架介绍
PasteForm是一个基于ABP的敏捷开发框架,核心思想是通过对Dto进行标注特性,让管理端完全交给后端,然你体验啥叫敏捷开发!!!
原理说明
上面说到了读写分离,在这个框架中,我主要用dbContext的方式实现数据库的相关操作,别问为啥不用仓储,我感觉仓储的存在很奇怪,或者说不够直接,不够灵活!
思路一
和其他文章一样,在读取的时候走从数据库,在其他操作上走主数据库,但是这个想法直接就被毙了,因为这个方案完全用不了,和业务需求完全冲突!
思路二
既然思路一走不通,那就换一个方式
其实在实际开发中,几乎的项目很多是走主库的,很少走从的,为啥呢?这里说的多少是接口,不是说访问次数哈!
那就换一个思路,
让开发者主动标记,我这个Action走从库还是走主库,上面说的走从库的少,那么我就默认走主库
这个思路我觉得是可行的,而且问了AI,也是肯定答复,那么问题就剩下如何写和测试了!
请看PasteFormDbContext的代码
/// <summary> /// /// </summary> [ConnectionStringName(PasteFormDbProperties.ConnectionStringName)] public class PasteFormDbContext : AbpDbContext<PasteFormDbContext>, IPasteFormDbContext { /* Add DbSet for each Aggregate Root here. Example: * public DbSet<Question> Questions { get; set; } */ /// <summary> /// /// </summary> /// <param name="options"></param> /// <param name="currentUser"></param> public PasteFormDbContext(DbContextOptions<PasteFormDbContext> options) : base(options) { } //其他代码 } 发现没有,有一个过滤器
ConnectionStringName 其他没有设置链接串的地方,
如果你查看这个过滤器的源码,你会发觉里面也没有写啥
public class ConnectionStringNameAttribute : Attribute { public string Name { get; } public ConnectionStringNameAttribute(string name) { Check.NotNull<string>(name, "name"); Name = name; } public static string GetConnStringName<T>() { return GetConnStringName(typeof(T)); } public static string GetConnStringName(Type type) { ConnectionStringNameAttribute customAttribute = type.GetTypeInfo().GetCustomAttribute<ConnectionStringNameAttribute>(); if (customAttribute == null) { return type.FullName; } return customAttribute.Name; } } 也就是说,执行数据库链接串写入到dbContext的不是他,他只是做一个标记
然后我找到了这个DefaultConnectionStringResolver
public class DefaultConnectionStringResolver : IConnectionStringResolver, ITransientDependency { protected AbpDbConnectionOptions Options { get; } public DefaultConnectionStringResolver(IOptionsMonitor<AbpDbConnectionOptions> options) { Options = options.CurrentValue; } [Obsolete("Use ResolveAsync method.")] public virtual string Resolve(string? connectionStringName = null) { return ResolveInternal(connectionStringName); } public virtual Task<string> ResolveAsync(string? connectionStringName = null) { return Task.FromResult(ResolveInternal(connectionStringName)); } private string? ResolveInternal(string? connectionStringName) { if (connectionStringName == null) { return Options.ConnectionStrings.Default; } string connectionStringOrNull = Options.GetConnectionStringOrNull(connectionStringName); if (!connectionStringOrNull.IsNullOrEmpty()) { return connectionStringOrNull; } return null; } } 我们来看看这个AI的解释
DefaultConnectionStringResolver 是ABP框架数据访问层的一个基础且关键的组件,它优雅地处理了连接字符串的管理问题,为应用程序特别是多租户应用程序提供了强大的灵活性。 上面的代码意思是什么呢?
在ABP中,链接串还有一个东西叫名称,上面的意思就是基于传入的名称,返回给调用方链接具体字符串!
注意看他注入的生命周期,是瞬时的,那么我们不就可以改变这个,让读取的时候,基于上下文返回字符串,而不是从传入的名称!
综上
从上面信息,那么问题就变成了,我如何基于上下文,给dbContext喂不一样的连接字符串,或者说基于上下文给不一样的dbContext
问题又来了,
如果你看一个Action,你会发现,在Action的过滤器执行前,Controller的构造函数已经执行了
也就是生命周期的顺序不对,都已经执行dbContext的初始化了,你才想改他的链接字符串
那么我们就换一个,换成更早的,更底层的中间件
/// <summary> /// /// </summary> public class ConnectionStringMiddleware { private readonly RequestDelegate _next; private readonly IConnectionStringSelector _selector; /// <summary> /// /// </summary> /// <param name="next"></param> /// <param name="selector"></param> public ConnectionStringMiddleware(RequestDelegate next, IConnectionStringSelector selector) { _next = next; _selector = selector; } /// <summary> /// /// </summary> /// <param name="context"></param> /// <returns></returns> public async Task InvokeAsync(HttpContext context) { var endpoint = context.GetEndpoint(); string connectionStringName = PasteFormDbProperties.SqliteConnectionStringName; if (endpoint?.Metadata.GetMetadata<UseReadOnlyConnectionAttribute>() != null) { connectionStringName = PasteFormDbProperties.SqliteReadOnlyConnectionStringName; } //else if (endpoint?.Metadata.GetMetadata<UseWriteConnectionAttribute>() != null) //{ // connectionStringName = "Default"; //} //else //{ // connectionStringName = context.Request.Method.Equals("GET", StringComparison.OrdinalIgnoreCase) // ? "ReadOnly" // : "Default"; //} _selector.SetConnectionStringName(connectionStringName); await _next(context); } 好理解吧,上面的意思是,如果当前的终结点没有UseReadOnlyConnectionAttribute过滤器,则走默认的,也就是主库,有则走从库,然后设置这个信息到IConnectionStringSelector
public interface IConnectionStringSelector { string GetConnectionStringName(); void SetConnectionStringName(string name); } /// <summary> /// 返回当前上下文的链接串名称,注意是名称,不是链接字符串 /// </summary> public class ConnectionStringSelector : IConnectionStringSelector { /// <summary> /// /// </summary> private string _connectionStringName = PasteFormDbProperties.SqliteConnectionStringName; /// <summary> /// /// </summary> /// <returns></returns> public string GetConnectionStringName() => _connectionStringName; /// <summary> /// /// </summary> /// <param name="name"></param> public void SetConnectionStringName(string name) => _connectionStringName = name; } 这样大致信息就链接起来了
对原来的代码几乎没有改动,
那么生效的就是让刚刚改的代码生效
//读写分离支持 如果不需要,需要把下面三行给注释掉 context.Services.AddScoped<IConnectionStringSelector, ConnectionStringSelector>(); context.Services.Replace(ServiceDescriptor.Singleton<IConnectionStringResolver, DynamicConnectionStringResolver>()); // app.UseMiddleware<ConnectionStringMiddleware>(); 在UseRouting之后 上面中DynamicConnectionStringResolver的注入为啥是单例呢
因为里面的代码意思就是基于链接名称获取连接字符串,这个是一对一的关系,不需要做特意的变更,因为一个程序启动后,这个对应关系是固定的!
关键点在于ConnectionStringSelector
基于访问上下文,修改当前的连接名称!!!
测试
改动后,我启动测试下
在权限page的Action中做如下只读标记
/// <summary> /// /// </summary> /// <param name="input"></param> /// <returns></returns> [HttpGet] [UseReadOnlyConnectionAttribute]//关键点在这,标识这个接口走只读 [TypeFilter(typeof(RoleAttribute), Arguments = new object[] { "data", "view" })] public async Task<PagedResultDto<RoleInfoListDto>> Page([FromQuery] InputQueryRoleInfo input) { //具体实现代码 } 然后我去创建一个新数据
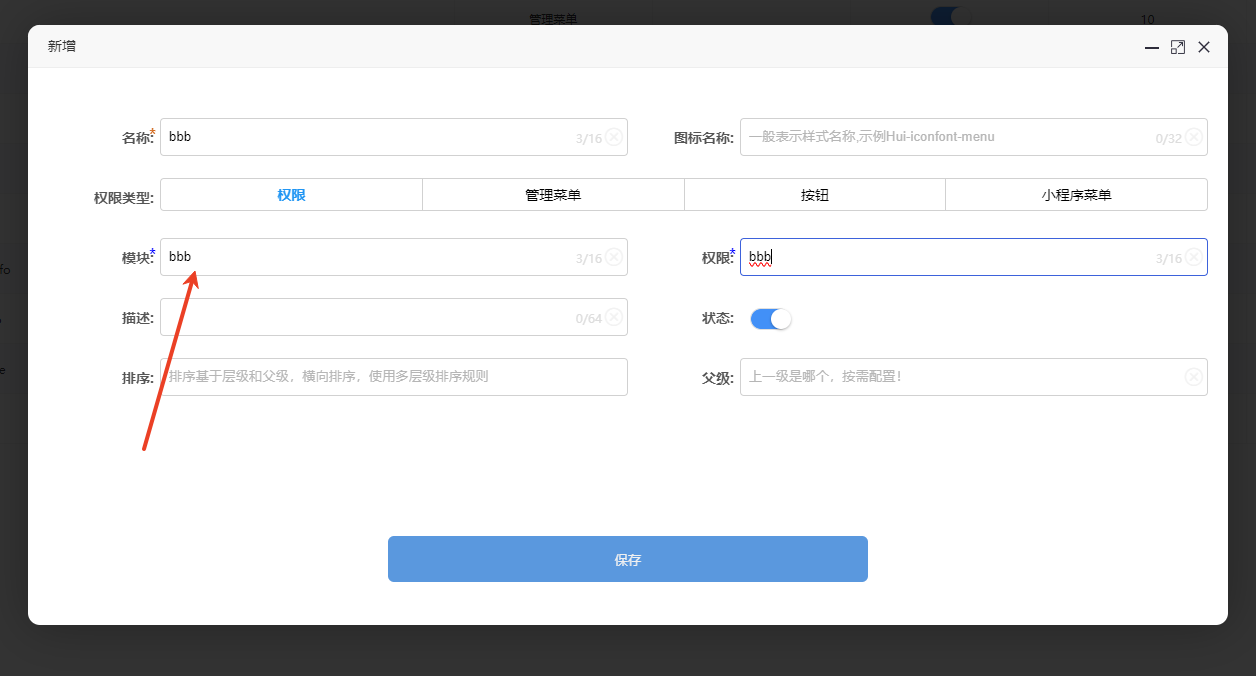
会发现读取列表的时候,是没有这个数据的

因为测试阶段,我的从数据库没有从主数据库自动同步
而测试其他表的新增和读取,则正常!
也就是role的page接口,走的是从数据库的读取!
结语
其实关键点在于IConnectionStringSelector
所以,非接口函数要实现的话,我们可以手动修改IConnectionStringSelector的数据,这样就可以实现切换主从了!
实际中,我感觉我上面还是有很多不足的,比如如果我是支持用户自己选择数据库的,那么就应该改成IConnectionStringSelector
只配置用主还是从
而下一个地方,则基于实际配置,自动拆分,比如拆分成sqlite的主库,还是sqlite得从库!




![洛谷 P11345 [KTSC 2023 R2] 基地简化 题解](http://www.itfaba.com/wp-content/themes/kemi/timthumb.php?src=http://www.itfaba.com/wp-content/themes/kemi/img/random/2.jpg&w=218&h=124&zc=1)
