
KV Cache 与 MQA/GQA:从推理优化看注意力机制的工程化演进
本文将从自回归推理的工程需求出发,系统阐述 KV Cache 的本质、设计原理及其如何自然引出多查询注意力(MQA)与分组查询注意力(GQA)的优化路径。
一、自回归推理的瓶颈与 KV Cache 的诞生
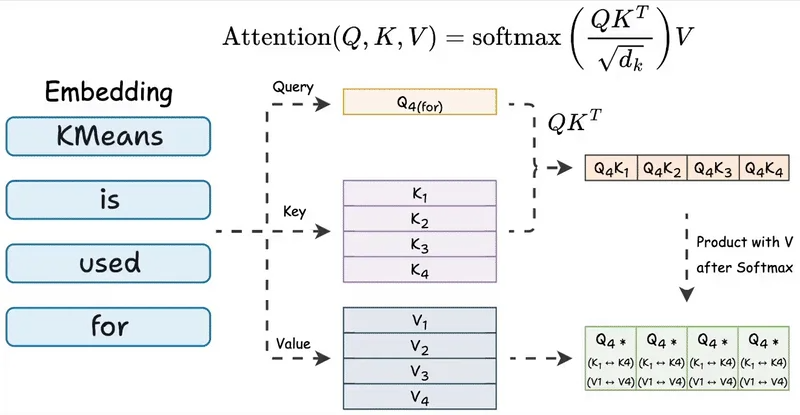
在 Transformer 的自注意力机制中,第 (t) 个位置的输出需要与历史所有位置进行交互:
其中 (Q_t = x_t W_Q),(K_t = x_t W_K),(V_t = x_t W_V)。
训练与推理在计算模式上存在根本差异。训练阶段采用并行计算:整个序列一次性输入,所有位置的注意力同步完成,无需保留中间状态。而自回归推理本质上是串行过程,每步仅生成一个新 token。若不加优化,第 (t) 步需要重新计算前 (t-1) 个位置的 (K) 和 (V) 矩阵,导致大量重复计算。
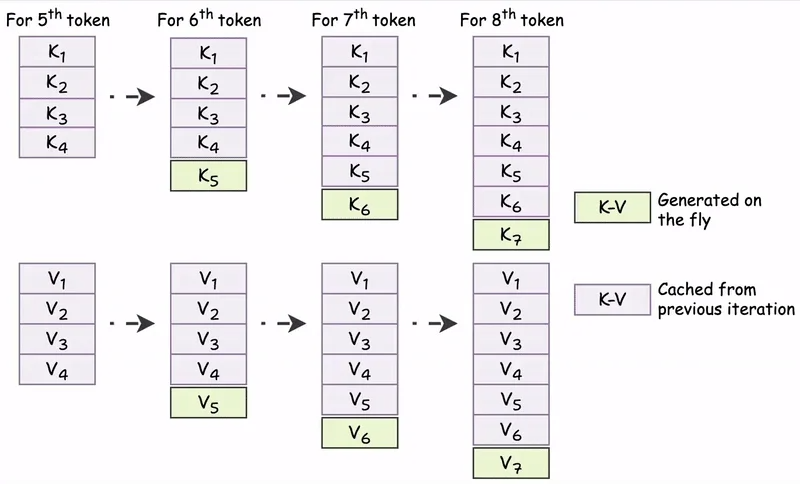
KV Cache 的核心思想是利用注意力计算的增量特性:对于已生成的历史 token,其 (K) 和 (V) 向量在后续步骤中保持不变。因此推理时在每一层维护一个缓存结构,逐步追加新 token 的键值对。第 (t) 步的计算流程简化为:
- 仅为当前 token 计算 (Q_t)、(K_t)、(V_t)
- 将 (K_t) 和 (V_t) 追加到缓存的末尾
- 用 (Q_t) 对完整的 (K_{1:t}) 和 (V_{1:t}) 执行一次注意力操作
这一机制将时间复杂度从每步 (mathcal{O}(t cdot D)) 的键值计算降至 (mathcal{O}(D)),显著减少计算量和内存带宽消耗。
二、KV Cache 的内存结构与规模分析
设模型具有 (L) 层、隐藏维度 (D)、注意力头数 (h)(单头维度 (d_h = D/h)),推理批量大小为 (B),当前序列长度为 (T)。在标准的多头注意力(MHA)中,每一层缓存的形状为:
全模型的 KV Cache 总量为 (2 cdot B cdot L cdot h cdot T cdot d_h = 2BLTD) 个浮点数。以 LLaMA-7B 为例((L=32),(D=4096),单精度浮点),生成长度 (T=2048) 时,单个样本的 KV Cache 约占用 1GB 显存。这一规模随序列长度和批量大小线性增长,成为长文本生成和高并发推理的主要瓶颈。
需要明确的是,KV Cache 存储的是经过线性投影后的连续向量表示,其规模与词表大小无关。缓存的增长完全由历史生成步数 (T) 驱动,这也是长上下文场景下显存压力剧增的根源。
三、从 MHA 到 GQA/MQA:注意力头的冗余与共享
标准 MHA 为每个查询头配备独立的键值头,这在训练阶段有助于学习多样化的注意力模式。然而在推理场景中,这种设计带来两个问题:
显存与带宽压力:KV Cache 规模与头数 (h) 成正比,限制了批量大小和上下文长度。
键值冗余:实证研究表明,不同注意力头学到的键值表示存在高度相关性,维持 (h) 份独立副本的必要性存疑。
多查询注意力(MQA)通过极端共享来解决这一问题:所有查询头共用单一的键值头((g=1))。此时缓存形状变为 ([B, 1, T, d_h]),规模直接缩减至原来的 (1/h)。分组查询注意力(GQA)采用折中策略,将 (h) 个查询头分为 (g) 组((1 < g < h)),每组共享一对键值头。缓存规模降为 (2BLTD cdot (g/h))。
这一演进的数学基础在于键值投影矩阵的参数压缩。MHA 具有 (h) 个独立的 (W_K^{(i)}) 和 (W_V^{(i)})((i=1,ldots,h)),而 GQA 仅保留 (g) 个键值投影,每个服务 (h/g) 个查询头。通过适当的训练策略(如从 MHA 检查点初始化后短暂微调),模型可以在保持大部分性能的前提下,大幅降低推理成本。
四、工程实践中的关键考量
量化与压缩:将 KV Cache 从 FP16 量化至 INT8 或 FP8 可进一步减半显存占用,配合动态缩放技术,精度损失通常在 1% 以内。
分页管理:借鉴操作系统的虚拟内存思想,vLLM 等框架将 KV Cache 切分为固定大小的块(如 16 个 token),动态分配物理显存,显著提升显存利用率和批处理吞吐。
卸载与重算:对超长上下文,可将早期 token 的 KV 缓存卸载至 CPU 内存,或在访问时按需重算。前者适用于内存充裕场景,后者在内存受限但计算资源充足时更优。
架构选择指南:通用高吞吐场景优先采用 GQA((g in {2, 4, 8})),平衡质量与效率;边缘部署或极限长上下文场景考虑 MQA;训练主导的应用保持 MHA 或较大的 (g) 值以充分利用模型容量。
五、面试高频问题解析
Q1:为什么只缓存 K 和 V,不缓存 Q?
查询向量 (Q_t) 仅在第 (t) 步与历史键值交互时使用,后续步骤不再需要。而 (K_t) 和 (V_t) 需要被未来所有步骤访问,必须持久化保存。这是注意力计算的非对称性导致的自然结果。
Q2:KV Cache 如何影响模型的并行性?
训练时的数据并行和张量并行不受影响,KV Cache 仅在推理阶段激活。在张量并行部署中,每个 GPU 存储 (h/N) 个头的键值缓存((N) 为并行度),通信仅发生在最终的输出聚合阶段,缓存本身不跨卡传输。
Q3:GQA 的分组数 (g) 如何确定?
需要在实验中平衡性能与效率。常见实践是设定 (g) 为 (h) 的约数(如 (h=32) 时取 (g in {4, 8})),使每组查询头数相等。元研究表明,(g geq 4) 时性能下降通常小于 2%,而显存节省达 75% 以上。
Q4:KV Cache 与 FlashAttention 是什么关系?
两者解决不同层面的问题。FlashAttention 通过分块计算和 IO 优化降低显存峰值和访问次数,在训练和推理中均有效。KV Cache 专注于推理阶段的增量计算优化。实际部署中两者通常结合使用,FlashAttention 负责单步注意力的高效执行,KV Cache 负责跨步的状态管理。
Q5:如何处理动态批处理中不同样本的序列长度差异?
采用 padding + mask 机制:将批内样本对齐到最大长度,通过 attention mask 屏蔽无效位置。现代框架(如 vLLM)进一步使用 PagedAttention,为每个样本独立分配块,避免 padding 浪费显存。批处理调度器会动态组合长度相近的请求,最大化硬件利用率。
六、总结与展望
KV Cache 是 Transformer 自回归推理的关键优化技术,通过缓存历史键值对将重复计算转化为内存查表,显著降低推理延迟。其内存开销随序列长度和头数线性增长,自然催生了 MQA 和 GQA 等共享机制。这一演进本质上是在模型表达能力与工程效率之间寻找最优平衡点。
随着上下文窗口扩展至百万 token 级别,KV Cache 的优化仍是活跃研究领域。未来的方向包括基于重要性的选择性缓存、低秩分解压缩、以及与检索增强生成(RAG)的深度融合。理解 KV Cache 的设计原理,是掌握大语言模型推理系统的必经之路。




