
在实时数据处理的完整链路中,数据输出(Sink)是最后一个关键环节,它负责将处理后的结果传递到外部系统供后续使用。Flink提供了丰富的数据输出连接器,支持将数据写入Kafka、Elasticsearch、文件系统、数据库等各种目标系统。本文将深入探讨Flink数据输出的核心概念、配置方法和最佳实践,并基于Flink 1.20.1构建一个完整的数据输出案例。
一、Flink Sink概述
1. 什么是Sink
Sink(接收器)是Flink数据处理流水线的末端,负责将计算结果输出到外部存储系统或下游处理系统。在Flink的编程模型中,Sink是DataStream API中的一个转换操作,它接收DataStream并将数据写入指定的外部系统。
2. Sink的分类
Flink的Sink连接器可以分为以下几类:
- 内置Sink:如print()、printToErr()等用于调试的内置输出
- 文件系统Sink:支持写入本地文件系统、HDFS等
- 消息队列Sink:如Kafka、RabbitMQ等
- 数据库Sink:如JDBC、Elasticsearch等
- 自定义Sink:通过实现SinkFunction接口自定义输出逻辑
3. 输出语义保证
Flink为Sink提供了三种输出语义保证:
- 最多一次(At-most-once):数据可能丢失,但不会重复
- 至少一次(At-least-once):数据不会丢失,但可能重复
- 精确一次(Exactly-once):数据既不会丢失,也不会重复
这些语义保证与Flink的检查点(Checkpoint)机制密切相关,我们将在后面详细讨论。
二、环境准备与依赖配置
1. 版本说明
- Flink:1.20.1
- JDK:17+
- Gradle:8.3+
- 外部系统:Kafka 3.4.0、Elasticsearch 7.17.0、MySQL 8.0
2. 核心依赖
dependencies { // Flink核心依赖 implementation 'org.apache.flink:flink_core:1.20.1' implementation 'org.apache.flink:flink-streaming-java:1.20.1' implementation 'org.apache.flink:flink-clients:1.20.1' // Kafka Connector implementation 'org.apache.flink:flink-connector-kafka:3.4.0-1.20' // Elasticsearch Connector implementation 'org.apache.flink:flink-connector-elasticsearch7:3.1.0-1.20' // JDBC Connector implementation 'org.apache.flink:flink-connector-jdbc:3.3.0-1.20' implementation 'mysql:mysql-connector-java:8.0.33' // FileSystem Connector implementation 'org.apache.flink:flink-connector-files:1.20.1' } 三、基础Sink操作
1. 内置调试Sink
Flink提供了一些内置的Sink用于开发和调试阶段:
import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; public class BasicSinkDemo { public static void main(String[] args) throws Exception { // 创建执行环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // 创建数据源 DataStream<String> stream = env.fromElements("Hello", "Flink", "Sink"); // 打印到标准输出 stream.print("StandardOutput"); // 打印到标准错误输出 stream.printToErr("ErrorOutput"); // 执行作业 env.execute("Basic Sink Demo"); } } 2. 文件系统Sink
Flink支持将数据写入本地文件系统、HDFS等。下面是一个写入本地文件系统的示例:
package com.cn.daimajiangxin.flink.sink; import org.apache.flink.api.common.serialization.SimpleStringEncoder; import org.apache.flink.configuration.MemorySize; import org.apache.flink.connector.file.sink.FileSink; import org.apache.flink.core.fs.Path; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.functions.sink.filesystem.RollingPolicy; import org.apache.flink.streaming.api.functions.sink.filesystem.rollingpolicies.DefaultRollingPolicy; import java.time.Duration; public class FileSystemSinkDemo { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); DataStream<Object> stream = env.fromData("Hello", "Flink", "FileSystem", "Sink"); RollingPolicy<Object, String> rollingPolicy = DefaultRollingPolicy.<Object, String>builder() .withRolloverInterval(Duration.ofMinutes(15)) .withInactivityInterval(Duration.ofMinutes(5)) .withMaxPartSize(MemorySize.ofMebiBytes(64)) .build(); // 创建文件系统Sink FileSink<Object> sink = FileSink .forRowFormat(new Path("file:///tmp/flink-output"), new SimpleStringEncoder<>()) .withRollingPolicy(rollingPolicy) .build(); // 添加Sink stream.sinkTo(sink); env.execute("File System Sink Demo"); } } 四、高级Sink连接器
1. Kafka Sink
Kafka是实时数据处理中常用的消息队列,Flink提供了强大的Kafka Sink支持:
import org.apache.flink.api.common.serialization.SimpleStringSchema; import org.apache.flink.connector.kafka.sink.KafkaRecordSerializationSchema; import org.apache.flink.connector.kafka.sink.KafkaSink; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import java.util.Properties; public class KafkaSinkDemo { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // 开启检查点以支持Exactly-Once语义 env.enableCheckpointing(5000); DataStream<String> stream = env.fromElements("Hello Kafka", "Flink to Kafka", "Data Pipeline"); // Kafka配置 Properties props = new Properties(); props.setProperty("bootstrap.servers", "localhost:9092"); // 创建Kafka Sink KafkaSink<String> sink = KafkaSink.<String> builder() .setKafkaProducerConfig(props) .setRecordSerializer(KafkaRecordSerializationSchema.builder() .setTopic("flink-output-topic") .setValueSerializationSchema(new SimpleStringSchema()) .build()) .build(); // 添加Sink stream.sinkTo(sink); env.execute("Kafka Sink Demo"); } } kafka消息队列消息:

2. Elasticsearch Sink
Elasticsearch是一个实时的分布式搜索和分析引擎,非常适合存储和查询Flink处理的实时数据:
package com.cn.daimajiangxin.flink.sink; import com.fasterxml.jackson.databind.ObjectMapper; import org.apache.flink.connector.elasticsearch.sink.Elasticsearch7SinkBuilder; import org.apache.flink.connector.elasticsearch.sink.ElasticsearchSink; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.http.HttpHost; import org.elasticsearch.action.index.IndexRequest; import org.elasticsearch.client.Requests; import java.util.Map; public class ElasticsearchSinkDemo { private static final ObjectMapper objectMapper = new ObjectMapper(); public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.enableCheckpointing(5000); DataStream<String> stream = env.fromData( "{"id":"1","name":"Flink","category":"framework"}", "{"id":"2","name":"Elasticsearch","category":"database"}"); // 配置Elasticsearch节点 HttpHost httpHost=new HttpHost("localhost", 9200, "http"); // 创建Elasticsearch Sink ElasticsearchSink<String> sink=new Elasticsearch7SinkBuilder<String>() .setBulkFlushMaxActions(10) // 批量操作数量 .setBulkFlushInterval(5000) // 批量刷新间隔(毫秒) .setHosts(httpHost) .setConnectionRequestTimeout(60000) // 连接请求超时时间 .setConnectionTimeout(60000) // 连接超时时间 .setSocketTimeout(60000) // Socket 超时时间 .setEmitter((element, context, indexer) -> { try { Map<String, Object> json = objectMapper.readValue(element, Map.class); IndexRequest request = Requests.indexRequest() .index("flink_documents") .id((String) json.get("id")) .source(json); indexer.add(request); } catch (Exception e) { // 处理解析异常 System.err.println("Failed to parse JSON: " + element); } }) .build(); // 添加Sink stream.sinkTo(sink); env.execute("Elasticsearch Sink Demo"); } } 使用post工具查看数据
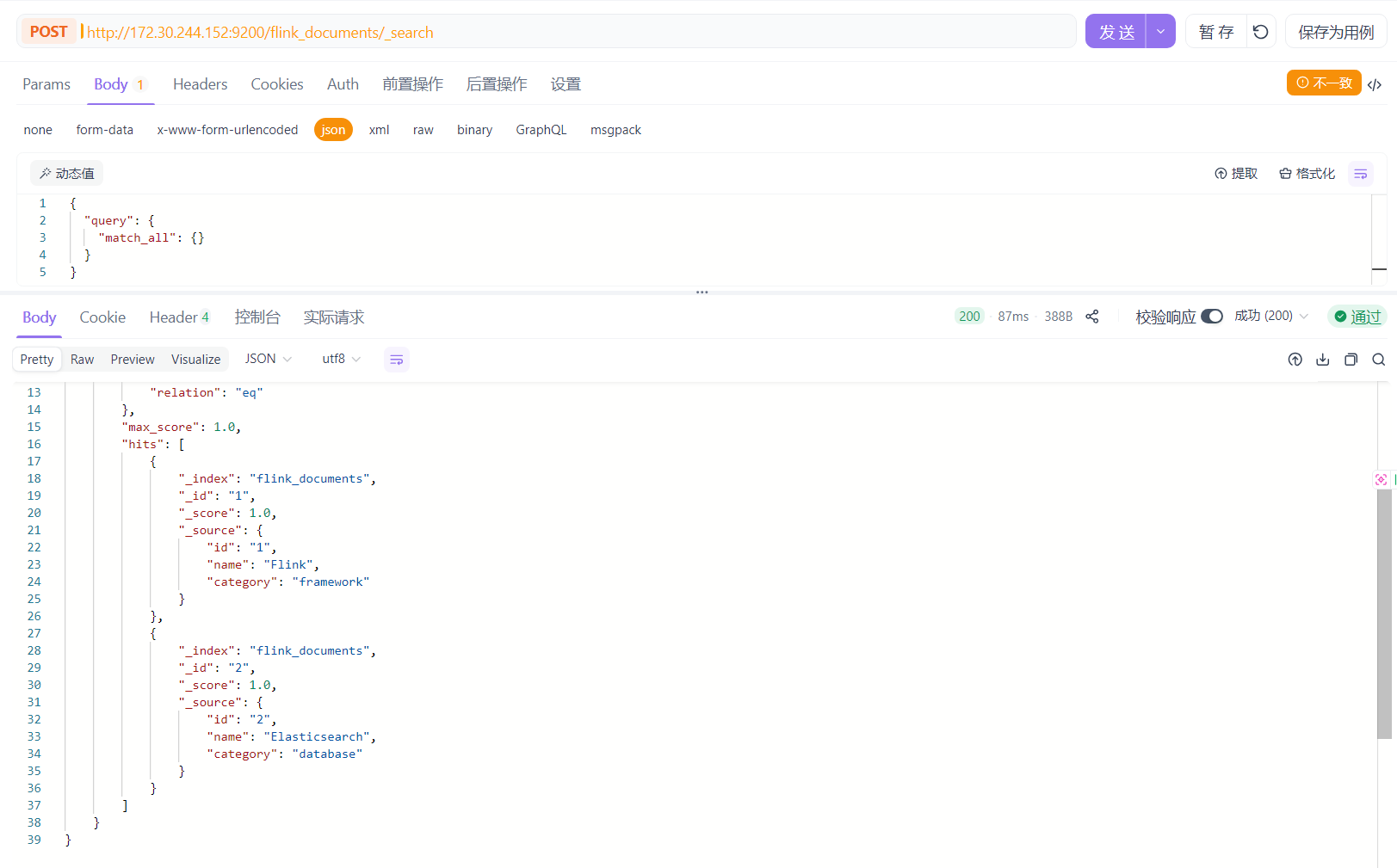
3. JDBC Sink
使用JDBC Sink可以将数据写入各种关系型数据库:
package com.cn.daimajiangxin.flink.sink; import org.apache.flink.connector.jdbc.JdbcConnectionOptions; import org.apache.flink.connector.jdbc.JdbcExecutionOptions; import org.apache.flink.connector.jdbc.JdbcStatementBuilder; import org.apache.flink.connector.jdbc.core.datastream.Jdbc; import org.apache.flink.connector.jdbc.core.datastream.sink.JdbcSink; import org.apache.flink.connector.jdbc.datasource.statements.SimpleJdbcQueryStatement; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import java.util.Arrays; import java.util.List; public class JdbcSinkDemo { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.enableCheckpointing(5000); List<User> userList = Arrays.asList( new User(1, "Alice", 25,"alice"), new User(2, "Bob", 30,"bob"), new User(3, "Charlie", 35,"charlie")); // 模拟用户数据 DataStream<User> userStream = env.fromData(userList); JdbcExecutionOptions jdbcExecutionOptions = JdbcExecutionOptions.builder() .withBatchSize(1000) .withBatchIntervalMs(200) .withMaxRetries(5) .build(); JdbcConnectionOptions connectionOptions = new JdbcConnectionOptions.JdbcConnectionOptionsBuilder() .withUrl("jdbc:mysql://localhost:3306/test") .withDriverName("com.mysql.cj.jdbc.Driver") .withUsername("username") .withPassword("password") .build(); String insertSql = "INSERT INTO user (id, name, age, user_name) VALUES (?, ?, ?, ?)"; JdbcStatementBuilder<User> statementBuilder = (statement, user) -> { statement.setInt(1, user.getId()); statement.setString(2, user.getName()); statement.setInt(3, user.getAge()); statement.setString(4, user.getUserName()); }; // 创建JDBC Sink JdbcSink<User> jdbcSink = new Jdbc().<User>sinkBuilder() .withQueryStatement( new SimpleJdbcQueryStatement<User>(insertSql,statementBuilder)) .withExecutionOptions(jdbcExecutionOptions) .buildAtLeastOnce(connectionOptions); // 添加Sink userStream.sinkTo(jdbcSink); env.execute("JDBC Sink Demo"); } // 用户实体类 public static class User { private int id; private String name; private String userName; private int age; public User(int id, String name, int age,String userName) { this.id = id; this.name = name; this.age = age; this.userName=userName; } public int getId() { return id; } public String getName() { return name; } public int getAge() { return age; } public String getUserName() { return userName; } } } 登录mysql客户端查看数据
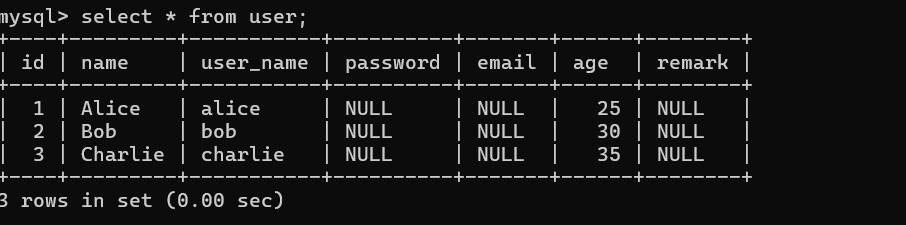
五、Sink的可靠性保证机制
1. 检查点与保存点
Flink的检查点(Checkpoint)机制是实现精确一次语义的基础。当开启检查点后,Flink会定期将作业的状态保存到持久化存储中。如果作业失败,Flink可以从最近的检查点恢复,确保数据不会丢失。
// 配置检查点 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // 启用检查点,间隔5000ms env.enableCheckpointing(5000); // 配置检查点模式为EXACTLY_ONCE(默认) env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE); // 设置检查点超时时间 env.getCheckpointConfig().setCheckpointTimeout(60000); // 设置最大并行检查点数量 env.getCheckpointConfig().setMaxConcurrentCheckpoints(1); // 开启外部化检查点,作业失败时保留检查点 env.getCheckpointConfig().enableExternalizedCheckpoints( CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION); 2. 事务与二阶段提交
对于支持事务的外部系统,Flink使用二阶段提交(Two-Phase Commit)协议来实现精确一次语义:
- 第一阶段(预提交):Flink将数据写入外部系统的预提交区域,但不提交
- 第二阶段(提交):所有算子完成预提交后,Flink通知外部系统提交数据
这种机制确保了即使在作业失败或恢复的情况下,数据也不会被重复写入或丢失。
3. 不同Sink的语义保证级别
不同的Sink连接器支持不同级别的语义保证:
- 支持精确一次(Exactly-once):Kafka、Elasticsearch(版本支持)、文件系统(预写日志模式)
- 支持至少一次(At-least-once):JDBC、Redis、RabbitMQ
- 最多一次(At-most-once):简单的无状态输出
六、自定义Sink实现
当Flink内置的Sink连接器不能满足需求时,我们可以通过实现SinkFunction接口来自定义Sink:
package com.cn.daimajiangxin.flink.sink; import org.apache.flink.api.common.functions.RuntimeContext; import org.apache.flink.api.connector.sink2.Sink; import org.apache.flink.api.connector.sink2.SinkWriter; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.functions.sink.RichSinkFunction; import java.io.IOException; public class CustomSinkDemo { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); DataStream<String> stream = env.fromElements("Custom", "Sink", "Example"); // 使用自定义Sink stream.sinkTo(new CustomSink()); env.execute("Custom Sink Demo"); } // 自定义Sink实现 - 使用新API public static class CustomSink implements Sink<String> { @Override public SinkWriter<String> createWriter(InitContext context) { return new CustomSinkWriter(); } // SinkWriter负责实际的数据写入逻辑 private static class CustomSinkWriter implements SinkWriter<String> { // 初始化资源 public CustomSinkWriter() { // 初始化连接、客户端等资源 System.out.println("CustomSink initialized"); } // 处理每个元素 @Override public void write(String value, Context context) throws IOException, InterruptedException { // 实际的写入逻辑 System.out.println("Writing to custom sink: " + value); } // 刷新缓冲区 @Override public void flush(boolean endOfInput) { // 刷新逻辑(如果需要) } // 清理资源 @Override public void close() throws Exception { // 关闭连接、客户端等资源 System.out.println("CustomSink closed"); } } } } 
七、实战案例:实时数据处理流水线
下面我们将构建一个完整的实时数据处理流水线,从Kafka读取数据,进行转换处理,然后输出到多个目标系统:
1. 系统架构
Kafka Source -> Flink Processing -> Multiple Sinks |-> Kafka Sink |-> Elasticsearch Sink |-> JDBC Sink 2. 数据模型
我们将使用日志数据模型,定义一个LogEntry类来表示日志条目:
package com.cn.daimajiangxin.flink.sink; public class LogEntry { private String timestamp; private String logLevel; private String source; private String message; public String getTimestamp() { return timestamp; } public void setTimestamp(String timestamp) { this.timestamp = timestamp; } public String getLogLevel() { return logLevel; } public void setLogLevel(String logLevel) { this.logLevel = logLevel; } public String getSource() { return source; } public void setSource(String source) { this.source = source; } public String getMessage() { return message; } public void setMessage(String message) { this.message = message; } @Override public String toString() { return String.format("LogEntry{timestamp='%s', logLevel='%s', source='%s', message='%s'}", timestamp, logLevel, source, message); } } 定义一个日志统计实体类LogStats,用于表示每个源的日志统计信息:
package com.cn.daimajiangxin.flink.sink; public class LogStats { private String source; private long count; public LogStats() { } public LogStats(String source, long count) { this.source = source; this.count = count; } public String getSource() { return source; } public void setSource(String source) { this.source = source; } public long getCount() { return count; } public void setCount(long count) { this.count = count; } @Override public String toString() { return String.format("LogStats{source='%s', count=%d}", source, count); } } 3. 完整实现代码
package com.cn.daimajiangxin.flink.sink; import org.apache.flink.api.common.eventtime.WatermarkStrategy; import org.apache.flink.api.common.serialization.SimpleStringSchema; import org.apache.flink.connector.jdbc.JdbcConnectionOptions; import org.apache.flink.connector.jdbc.JdbcExecutionOptions; import org.apache.flink.connector.jdbc.JdbcStatementBuilder; import org.apache.flink.connector.jdbc.core.datastream.Jdbc; import org.apache.flink.connector.jdbc.core.datastream.sink.JdbcSink; import org.apache.flink.connector.jdbc.datasource.statements.SimpleJdbcQueryStatement; import org.apache.flink.connector.kafka.sink.KafkaRecordSerializationSchema; import org.apache.flink.connector.kafka.sink.KafkaSink; import org.apache.flink.connector.kafka.source.KafkaSource; import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.connector.elasticsearch.sink.Elasticsearch7SinkBuilder; import org.apache.flink.connector.elasticsearch.sink.ElasticsearchSink; import org.apache.http.HttpHost; import org.elasticsearch.action.index.IndexRequest; import org.elasticsearch.client.Requests; import java.sql.PreparedStatement; import java.time.LocalDateTime; import java.util.ArrayList; import java.util.HashMap; import java.util.List; import java.util.Map; import java.util.Properties; public class MultiSinkPipeline { public static void main(String[] args) throws Exception { // 1. 创建执行环境并配置检查点 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.enableCheckpointing(5000); // 2. 创建Kafka Source KafkaSource<String> source = KafkaSource.<String> builder() .setBootstrapServers("localhost:9092") .setTopics("logs-input-topic") .setGroupId("flink-group") .setStartingOffsets(OffsetsInitializer.earliest()) .setValueOnlyDeserializer(new SimpleStringSchema()) .build(); // 3. 读取数据并解析 DataStream<String> kafkaStream = env.fromSource(source, WatermarkStrategy.noWatermarks(), "Kafka Source"); // 解析日志数据 DataStream<LogEntry> logStream = kafkaStream .map(line -> { String[] parts = line.split("\|"); return new LogEntry(parts[0], parts[1], parts[2], parts[3]); }) .name("Log Parser"); // 4. 过滤错误日志 DataStream<LogEntry> errorLogStream = logStream .filter(log -> "ERROR".equals(log.getLogLevel())) .name("Error Log Filter"); // 5. 配置并添加Kafka Sink - 输出错误日志 // Kafka配置 Properties props = new Properties(); props.setProperty("bootstrap.servers", "localhost:9092"); // 创建Kafka Sink KafkaSink<LogEntry> kafkaSink = KafkaSink.<LogEntry>builder() .setKafkaProducerConfig(props) .setRecordSerializer(KafkaRecordSerializationSchema.<LogEntry>builder() .setTopic("error-logs-topic") .setValueSerializationSchema(element -> element.toString().getBytes()) .build()) .build(); errorLogStream.sinkTo(kafkaSink).name("Error Logs Kafka Sink"); // 6. 配置并添加Elasticsearch Sink - 存储所有日志 // 配置Elasticsearch节点 HttpHost httpHost=new HttpHost("localhost", 9200, "http"); ElasticsearchSink<LogEntry> esSink = new Elasticsearch7SinkBuilder<LogEntry>() .setBulkFlushMaxActions(10) // 批量操作数量 .setBulkFlushInterval(5000) // 批量刷新间隔(毫秒) .setHosts(httpHost) .setConnectionRequestTimeout(60000) // 连接请求超时时间 .setConnectionTimeout(60000) // 连接超时时间 .setSocketTimeout(60000) // Socket 超时时间 .setEmitter((element, context, indexer) -> { Map<String, Object> json = new HashMap<>(); json.put("timestamp", element.getTimestamp()); json.put("logLevel", element.getLogLevel()); json.put("source", element.getSource()); json.put("message", element.getMessage()); IndexRequest request = Requests.indexRequest() .index("logs_index") .source(json); indexer.add(request); }) .build(); logStream.sinkTo(esSink).name("Elasticsearch Sink"); // 7. 配置并添加JDBC Sink - 存储错误日志统计 // 先进行统计 DataStream<LogStats> statsStream = errorLogStream .map(log -> new LogStats(log.getSource(), 1)) .keyBy(LogStats::getSource) .sum("count") .name("Error Log Stats"); JdbcExecutionOptions jdbcExecutionOptions = JdbcExecutionOptions.builder() .withBatchSize(1000) .withBatchIntervalMs(200) .withMaxRetries(5) .build(); JdbcConnectionOptions connectionOptions = new JdbcConnectionOptions.JdbcConnectionOptionsBuilder() .withUrl("jdbc:mysql://localhost:3306/test") .withDriverName("com.mysql.cj.jdbc.Driver") .withUsername("mysql用户名") .withPassword("mysql密码") .build(); String insertSql = "INSERT INTO error_log_stats (source, count, last_updated) VALUES (?, ?, ?) " + "ON DUPLICATE KEY UPDATE count = count + VALUES(count), last_updated = VALUES(last_updated)"; JdbcStatementBuilder<LogStats> statementBuilder = (statement, stats) -> { statement.setString(1, stats.getSource()); statement.setLong(2, stats.getCount()); statement.setTimestamp(3, java.sql.Timestamp.valueOf(LocalDateTime.now())); }; // 创建JDBC Sink JdbcSink<LogStats> jdbcSink = new Jdbc().<LogStats>sinkBuilder() .withQueryStatement( new SimpleJdbcQueryStatement<LogStats>(insertSql,statementBuilder)) .withExecutionOptions(jdbcExecutionOptions) .buildAtLeastOnce(connectionOptions); statsStream.sinkTo(jdbcSink).name("JDBC Sink"); // 8. 执行作业 env.execute("Multi-Sink Data Pipeline"); } } 4. 测试与验证
要测试这个完整的流水线,我们需要:
-
启动Kafka并创建必要的主题:
# 创建输入主题 kafka-topics.sh --create --topic logs-input-topic --bootstrap-server localhost:9092 --partitions 1 --replication-factor 1 # 创建错误日志输出主题 kafka-topics.sh --create --topic error-logs-topic --bootstrap-server localhost:9092 --partitions 1 --replication-factor 1 -
启动Elasticsearch并确保服务正常运行
-
在MySQL中创建必要的表:
CREATE DATABASE test; USE test; CREATE TABLE error_log_stats ( source VARCHAR(100) PRIMARY KEY, count BIGINT NOT NULL, last_updated TIMESTAMP NOT NULL ); -
向Kafka发送测试数据:
kafka-console-producer.sh --topic logs-input-topic --bootstrap-server localhost:9092 # 输入以下测试数据 2025-09-29 12:00:00|INFO|application-service|Application started successfully 2025-09-29 12:01:30|ERROR|database-service|Failed to connect to database 2025-09-29 12:02:15|WARN|cache-service|Cache eviction threshold reached 2025-09-29 12:03:00|ERROR|authentication-service|Invalid credentials detected -
运行Flink作业并观察数据流向各个目标系统
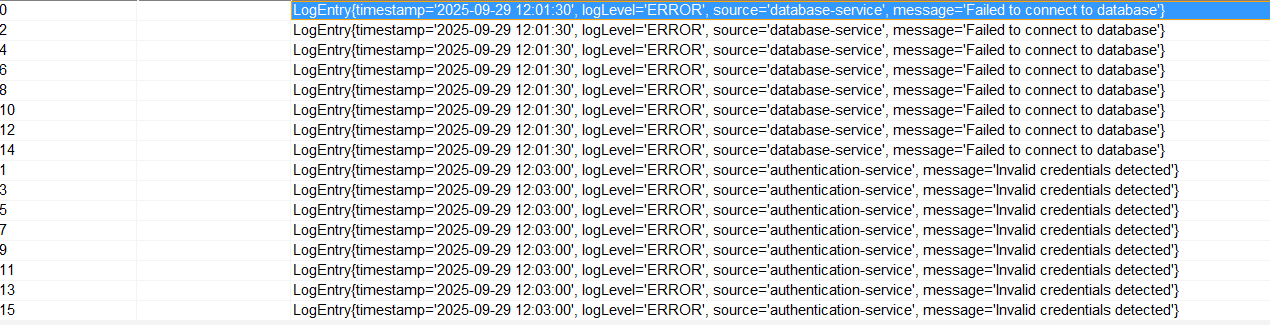
查看Kafka Sink中的数据:


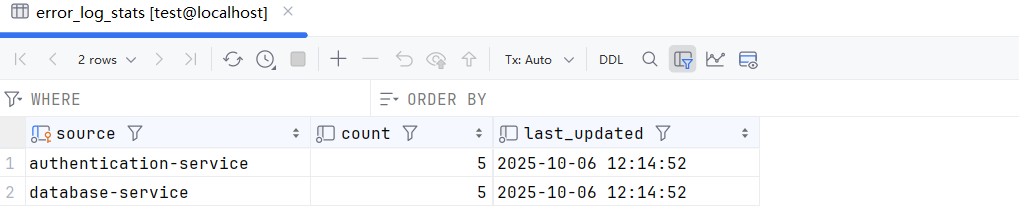
查看MySQL中的数据:
查看Elasticsearch中的数据:

八、性能优化与最佳实践
1. 并行度配置
合理设置Sink的并行度可以显著提高吞吐量:
// 为特定Sink设置并行度 stream.addSink(sink).setParallelism(4); // 或为整个作业设置默认并行度 env.setParallelism(4); 2. 批处理配置
对于支持批处理的Sink,合理配置批处理参数可以减少网络开销:
// JDBC批处理示例 JdbcExecutionOptions.builder() .withBatchSize(1000) // 每批次处理的记录数 .withBatchIntervalMs(200) // 批处理间隔 .withMaxRetries(3) // 最大重试次数 .build(); 3. 背压处理
当Sink无法处理上游数据时,会产生背压。Flink提供了背压监控和处理机制:
- 使用Flink Web UI监控背压情况
- 考虑使用缓冲机制或调整并行度
- 对于关键路径,实现自定义的背压处理逻辑
4. 资源管理
合理管理连接和资源是保证Sink稳定运行的关键:
- 使用连接池管理数据库连接
- 在RichSinkFunction的open()方法中初始化资源
- 在close()方法中正确释放资源
5. 错误处理策略
为Sink配置适当的错误处理策略:
// 重试策略配置 env.setRestartStrategy(RestartStrategies.fixedDelayRestart( 3, // 最大重试次数 Time.of(10, TimeUnit.SECONDS) // 重试间隔 )); 九、总结与展望
本文深入探讨了Flink数据输出(Sink)的核心概念、各种连接器的使用方法以及可靠性保证机制。我们学习了如何配置和使用内置Sink、文件系统Sink、Kafka Sink、Elasticsearch Sink和JDBC Sink,并通过自定义Sink扩展了Flink的输出能力。最后,我们构建了一个完整的实时数据处理流水线,将处理后的数据输出到多个目标系统。
在Flink的数据处理生态中,Sink是连接计算结果与外部世界的桥梁。通过选择合适的Sink连接器并配置正确的参数,我们可以构建高效、可靠的数据处理系统。




![洛谷 P11345 [KTSC 2023 R2] 基地简化 题解](http://www.itfaba.com/wp-content/themes/kemi/timthumb.php?src=http://www.itfaba.com/wp-content/themes/kemi/img/random/2.jpg&w=218&h=124&zc=1)
