
本文首发于本人微信公众号,链接:
https://mp.weixin.qq.com/s/XSXjwPZBwZCE1uy8gRZqWg
摘要
本文为CUDA并行规约系列文章的下篇,本文介绍了5种并行规约算法的实现,并从硬件的角度对它们进行分析和优化,最终给出一个开箱即用的模板代码及其使用示例。
勘误
首先是一个勘误,在上篇中存在一个拼写错误,线程束的正确单词是Warp而不是Wrap,非常抱歉给读者朋友们造成了误解。
写在前面
这是本系列文章的下篇。上篇介绍了一些CUDA并行规约优化涉及到的GPU硬件知识,并给出了两种并不完美的实现。
本文将接着介绍剩下的五种实现,并给出一个开箱即用的CUDA并行规约模板。
算法具体实现(下篇)
V2: Sequential Addressing
先简单回顾一下,在上篇的最后,我们发现V1版本的实现存在Bank Conflict的问题,具体表现为,当(s=32)时,(T_0)会访问(A_0),(T_1)会访问(A_{32}),(T_2)会访问(A_{64}).....,造成一个Warp里所有线程都同时访问Bank 0,导致这些访问被串行化,严重影响性能。
造成这一问题的根本原因是:同一个Warp里的线程,它们访问的地址存在可变的Stride
Bank机制设计之初的预期就是一个Warp里32个线程访问连续的32个地址,而不是访问分散在各处的地址。
明确了这一点之后,优化方法就很明确了:我们只需要让每个线程都负责其threadIdx对应的内存地址的规约即可,比如(T_0)就只管(A_0),(T_1)就只管(A_1),这样就不会出现Bank Conflict了。
由于要防止Warp Divergence,所以第一轮循环只有前一半线程在工作,以(n=512)为例,第一轮循环只有(T_0)到(T_{255})在工作,那么很显然的,(T_0)就需要规约(A_0)和(A_{256}),(T_1)需要规约(A_1)和(A_{257}),以此类推。这个过程如下图所示:
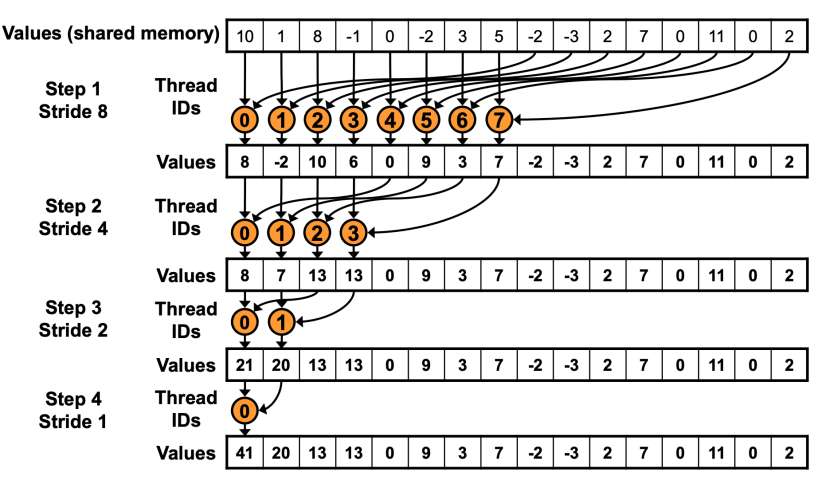
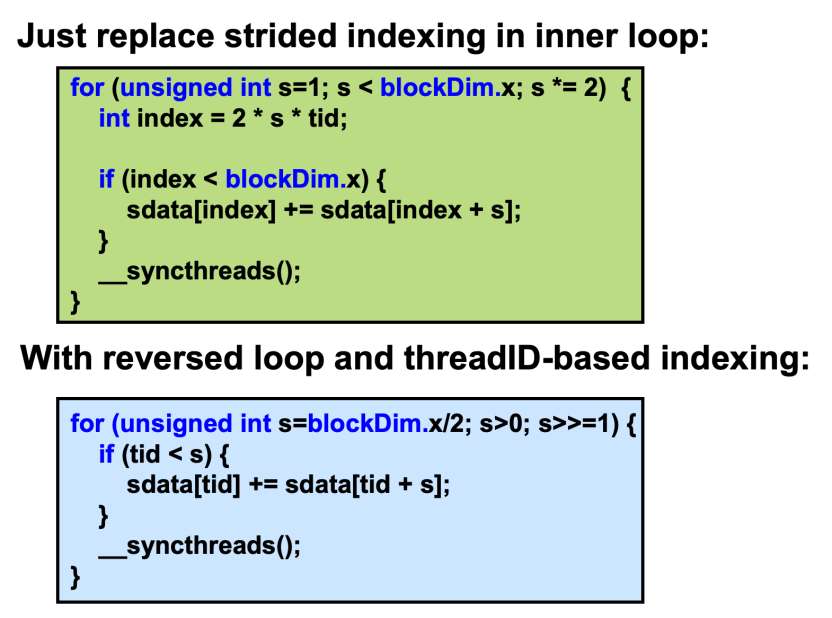
在代码实现上也不难,只需要做如下改变即可:
一个容易混淆的点
可能会有读者感到疑惑:总会有一次循环,(T_0)会访问(A_0)和(A_{32}),这怎么能算解决了Bank Conflict呢?
这里需要明确的一点是:Bank Conflict是发生在线程间的,而不是一个线程内的指令间的。
从指令执行的角度来分析,就以(A_0 = A_0 + A_{32})为例,这条语句会分4步完成,分别是:读取(A_0),读取(A_{32}),计算(A_0 + A_{32}),写入(A_0)。
对(T_0)而言,读取(A_0)和读取(A_{32})一定是先后发生的,不会并行,所以也就不存在Bank Conflict。
这里我们再从线程间执行的角度来看看,在(T_0)读取(A_0)时,(T_1)在读取(A_1),这不会发生冲突。但是如果是V1的实现,在(T_0)读取(A_0)时,(T_1)可能会同时在读取(A_{32}),这就导致了Bank Conflict。
优化效果
根据NVIDIA的数据,这一优化将性能提升了接近1倍,也是相当可观的。

V3: First Add During Load
V2版本已经把硬件上踩过的坑基本都填完了,接下来就是一些细节上的优化。其中有一个思路就是在把数据加载到共享内存的阶段做一些预处理。
比如,我们可以先把(A_0)和(A_1)规约了,然后存储到(A_0)中,把(A_2)和(A_3)规约了,存储到(A_1)中。这样就只需要启动一半的线程,以几乎一半的时间执行完所有的任务。
这一想法还可以进一步推广,如果在加载阶段就提前规约4个元素,那就可以把时间压缩到(frac{1}{4})。
这一思想就是所谓的算法级联,即结合并行执行和串行执行的策略。这部分更详细的会在后面V6版本里分析。
由于这里NVIDIA的实现和我们的问题定义有冲突,这里就不详细展开了,仅贴出NVIDIA的实现供参考。

实测的数据也验证了这一理论的正确性,时间确实缩短了接近一半。

V4: Unroll the Last Warp
V3版本计算出的有效带宽为17GB/s,远没有达到硬件的上限,所以有理由怀疑这里还存在指令执行上的瓶颈。
观察之后发现,这里的部分循环指令也许可以优化掉。在上篇中,我们提到过:在同一个Warp里,指令执行可以认为是同步的,所以我们可以在最后32个线程工作时去掉__syncthreads。
此外,既然都已经知道这里是最后32个线程在工作了,那循环也不必需要了,可以直接硬编码写(T_i = A_i + A_{i+32}),(T_i = A_i + A_{i+16}),......,最终的修改如下图所示

为什么不需要线程同步了?
因为这里可以保证进入warpReduce的线程是(T_0)到(T_{31}),即一个Warp内的线程。
根据之前的内容,(T_0)在执行函数第二行(A_0 += A_{16})时,(T_{16})是一定也在执行第二行,换言之,(T_{16})是一定执行完成了第一行的,这就保证了在执行取(A_{16})这个指令时,(A_{16})存储的一定是规约了(A_{16})和(A_{48})之后的值。
那么还有一个疑问:这里(T_{16})写入了新的(A_{16})的值是(A_{16} + A_{32}),这不就破坏了整个规约过程了吗?
事实上,这里(T_{16})写入了什么并不重要,这是基于两点事实:
首先,(T_{16})写入(A_{16})和(T_0)写入(A_0)一定是在同一个时钟周期内发生的,所以在一开始执行第二行时,(T_0)读取到的(A_{16})一定是没被破坏的(A_{16}),这确保了(T_0)执行的正确性;
其次,在执行完第一行之后,实际上只有(T_0)到(T_{15})真正起作用了,后面16个线程只要不乱写数据妨碍到前16个线程的工作,无论做什么都对结果没影响。
所以理论上讲,这里加个判断,只让(tid < 16)的线程执行,最终的结果都是正确的。这里没有这么做主要是为了防止Warp Divergence。
优化效果
实验数据表明,仅仅是对最后一个Warp做了循环展开,最终性能就优化了接近一倍。

V5: Completely Unrolled
既然只对最后一个Warp进行循环展开优化就这么明显,那能不能再激进一些,把所有循环都丢掉呢?
答案是Yes。
因为一个线程块内的线程数量上限是1024,并且我们要求线程数量是2的整数次幂,所以我们可以枚举所有可能的线程数量,然后仿照之前展开最后一个循环的方法,针对每种情况直接写出对应的展开后的代码。
如果只是在参数列表里加一个blockSize,那么在运行时还是会经过多个无意义的if-else,影响执行效率。这里可以借助C++的模板机制,进一步地提升执行性能。具体的修改如下图所示:
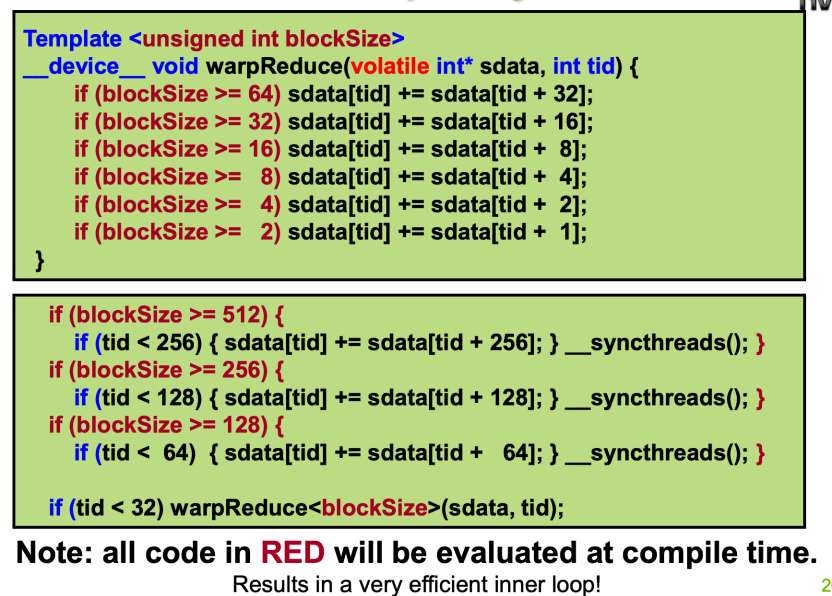
这里的blockSize是在调用时使用模板传递的,这里面的if会在编译时就进行优化。
编译器会使用Dead Code Elimination,根据blockSize删掉不可达的代码,所以最终编译出的二进制里面是不会有这些红色的if的,只有一串顺序执行的指令。
但是模板要求我们在编译阶段就确定blockSize,在实际实现时是比较困难的,这个该如何解决呢?答案是在调用时使用switch来枚举,简单粗暴,如下图所示:

优化效果

V6: Multiple Adds
理论分析
这里我们要从成本的角度来看待一下现有的方案。
和我们租用算力服务器一样,成本可以用使用时间 * GPU核心数量来衡量,这里GPU核心数量可以认为是线程数量,两者之间只有常数倍的差别。
我们假设这样一个场景来计算成本:
- 只有1个Batch,共有(N)个元素
- 启动(P)个线程来处理,在V5实现中,(P=N)
这里使用Brent定理:
其中(t(n))为算法的估计实际执行时间;(W(n))表示算法的总工作量,即一共执行多少次运算;(p)表示线程数量;(T(n))表示算法在最理想的情况下,算法执行的最短用时
很显然,这里(p=N);由于最少也需要执行(log N)步规约,所以(T(n)=log N);一通计算可以得到,(W(n)=O(N)),这里具体计算过程见NVIDIA的PPT,这里不再赘述。
带入公式可得,(t(n)=O(log N))
那么可以计算得到,V5版本算法的成本为(O(N log N))。
但是如果用一个线程串行处理所有数据,成本却只有(O(N)),也就是说,我们的并行算法的成本比纯串行处理还要高。那么怎么把这个成本降下来呢?
这里成本变高的本质是:线程数量过多,使得每个线程的工作量太少,导致了整体成本的增大。
那么相对应的,我们可以通过减少线程数量来实现降本增效。具体来说,我们可以使用V3中提到的方法,即在加载数据的阶段就提前做几次规约。
那么具体应该做多少次呢?这里NVIDIA的PPT里给出的数据是应该做(log N)次,如此优化之后,最终的成本能降到(O(N)),可以和串行执行持平。
这里把串行和并行搭配使用的策略就是算法级联。
实现方式
这里NVIDIA的实现和我们的问题定义相冲突,所以这里不再赘述了,后面在开箱即用的部分会解释我们是如何处理这一冲突的。
下图是V5到V6版本的变化以及V6的完整代码实现。


优化效果
这里贴出7个版本的优化效果数据表格:
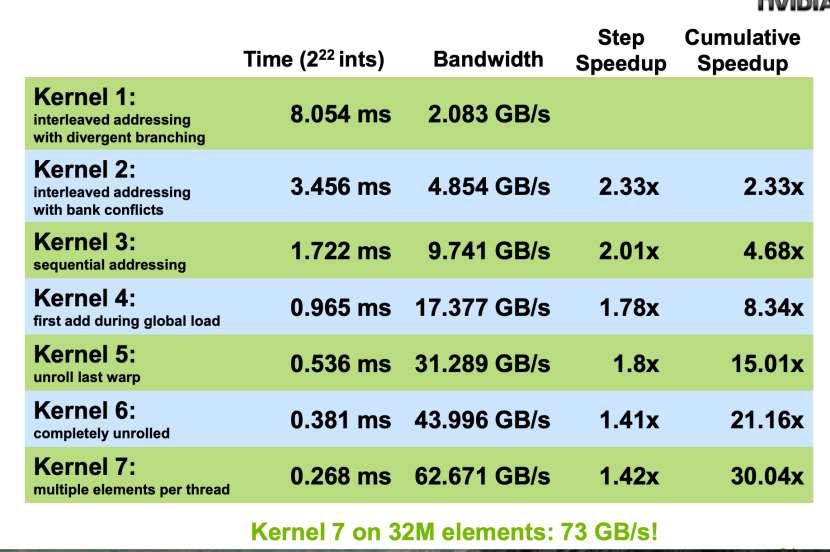
还能再优化吗?
NVIDIA官方的PPT到这里就结束了。我们可以思考一下:V6版本还能进一步优化吗?
也许还可以,比如用循环展开的技巧和最开始的while循环展开一下,这个就作为open issue供大家探讨了。
开箱即用的实现
数据要求
- 输入:(m times n)矩阵按行优先展开成的一个向量(x)
- 输出:(m)维向量(out)
- 要求线程块内线程的数量(
block_size) (leq 1024),并且为2的整数次幂 - 要求(n)一定要能整除
block_size
NVIDIA官方的实现里似乎没有batch的概念,感觉是想要把输入的所有数据都规约到一个值,因此在V3和V6里面会有跨Block规约的情况。
我们这里就不采用这个方案,而是把(n)分为了若干个fold,最终的线程数量就是 (frac{n}{text{fold_num}}),在一开始加载数据时就提前规约fold_num次。这个fold_num由调用方传递。
对于一个batch数量大于1024的情况,和数据数量不是2的整数次幂的情况,则需要调用CUDA的上层框架做处理了,这里暂时不考虑这些case。
代码实现
这一实现使用了C++的模板特性,支持调用者自行选择数据类型和规约函数。
template<typename T> using ReduceFunc = T(*)(T, T); template<typename T, ReduceFunc<T> reduce_func, size_t block_size> __device__ void reduceWarp(volatile T *shared_memory, size_t tid) { if (block_size >= 64) shared_memory[tid] = reduce_func(shared_memory[tid], shared_memory[tid + 32]); if (block_size >= 32) shared_memory[tid] = reduce_func(shared_memory[tid], shared_memory[tid + 16]); if (block_size >= 16) shared_memory[tid] = reduce_func(shared_memory[tid], shared_memory[tid + 8]); if (block_size >= 8) shared_memory[tid] = reduce_func(shared_memory[tid], shared_memory[tid + 4]); if (block_size >= 4) shared_memory[tid] = reduce_func(shared_memory[tid], shared_memory[tid + 2]); if (block_size >= 2) shared_memory[tid] = reduce_func(shared_memory[tid], shared_memory[tid + 1]); } /** * Grid(m, 1, 1) * Block(block_size, 1, 1) * @tparam T 需要Reduce的数据类型 * @tparam reduce_func Reduce函数 * @tparam block_size 一个block里的线程数量,要求一定是2的整数次幂,最多支持1024 * @param x 输入矩阵,按行优先展开 * @param out 输出向量 * @param n 一个batch里的元素数量,要求一定能整除block_size */ template<typename T, ReduceFunc<T> reduce_func, size_t block_size> __global__ void ReduceKernelTemplateFinal(const T *x, T *out, const size_t n) { assert(block_size <= 1024); assert((block_size & (block_size - 1)) == 0); // 确保n是2的整数次幂 assert((n & (block_size - 1)) == 0); // 确保n能够整除batch_size extern __shared__ T shared_memory[]; const size_t tid = threadIdx.x; const size_t fold_num = n >> __builtin_ctz(block_size); // 这里会直接在编译阶段就展开,更高效 size_t i = 1; size_t last_x_index = blockIdx.x * blockDim.x + tid; shared_memory[tid] = x[last_x_index]; while (i < fold_num) { const size_t current_x_index = last_x_index + block_size; shared_memory[tid] = reduce_func(shared_memory[tid], x[current_x_index]); last_x_index = current_x_index; i++; } __syncthreads(); // 完成加载阶段,开始规约 if (block_size >= 1024) { if (tid < 512) { shared_memory[tid] = reduce_func(shared_memory[tid], shared_memory[tid + 512]); __syncthreads(); } } if (block_size >= 512) { if (tid < 256) { shared_memory[tid] = reduce_func(shared_memory[tid], shared_memory[tid + 256]); __syncthreads(); } } if (block_size >= 256) { if (tid < 128) { shared_memory[tid] = reduce_func(shared_memory[tid], shared_memory[tid + 128]); __syncthreads(); } } if (block_size >= 128) { if (tid < 64) { shared_memory[tid] = reduce_func(shared_memory[tid], shared_memory[tid + 64]); __syncthreads(); } } if (tid < 32) { reduceWarp<T, reduce_func, block_size>(shared_memory, tid); } // 规约完成,写入结果 if (tid == 0) { out[blockIdx.x] = shared_memory[0]; } } template<typename T, ReduceFunc<T> reduce_func> void InvokeReduceFunc(const T *x, T *out, const size_t m, const size_t n, size_t fold) { if (n < fold) { fold = 1; } assert(n % fold == 0); size_t block_size = n / fold; dim3 grid(m, 1, 1); dim3 block(block_size, 1, 1); switch (block_size) { case 1024: ReduceKernelTemplateFinal<scalar_t, reduce_func, 1024><<<grid, block, sizeof(scalar_t) * block_size>>>(x, out, n); break; case 512: ReduceKernelTemplateFinal<scalar_t, reduce_func, 512><<<grid, block, sizeof(scalar_t) * block_size>>>(x, out, n); break; case 256: ReduceKernelTemplateFinal<scalar_t, reduce_func, 256><<<grid, block, sizeof(scalar_t) * block_size>>>(x, out, n); break; case 128: ReduceKernelTemplateFinal<scalar_t, reduce_func, 128><<<grid, block, sizeof(scalar_t) * block_size>>>(x, out, n); break; case 64: ReduceKernelTemplateFinal<scalar_t, reduce_func, 64><<<grid, block, sizeof(scalar_t) * block_size>>>(x, out, n); break; case 32: ReduceKernelTemplateFinal<scalar_t, reduce_func, 32><<<grid, block, sizeof(scalar_t) * block_size>>>(x, out, n); break; case 16: ReduceKernelTemplateFinal<scalar_t, reduce_func, 16><<<grid, block, sizeof(scalar_t) * block_size>>>(x, out, n); break; case 8: ReduceKernelTemplateFinal<scalar_t, reduce_func, 8><<<grid, block, sizeof(scalar_t) * block_size>>>(x, out, n); break; case 4: ReduceKernelTemplateFinal<scalar_t, reduce_func, 4><<<grid, block, sizeof(scalar_t) * block_size>>>(x, out, n); break; case 2: ReduceKernelTemplateFinal<scalar_t, reduce_func, 2><<<grid, block, sizeof(scalar_t) * block_size>>>(x, out, n); break; case 1: ReduceKernelTemplateFinal<scalar_t, reduce_func, 1><<<grid, block, sizeof(scalar_t) * block_size>>>(x, out, n); break; } } 使用示例
使用起来还是比较简单的,如下所示:
__device__ inline scalar_t sum_reduce_func(scalar_t x, scalar_t y) { return x + y; } void ReduceMax(const CudaArray& a, CudaArray* out, size_t reduce_size) { /** * Reduce by taking maximum over `reduce_size` contiguous blocks. Even though it is inefficient, * for simplicity you can perform each reduction in a single CUDA thread. * * Args: * a: compact array of size a.size = out.size * reduce_size to reduce over * out: compact array to write into * redice_size: size of the dimension to reduce over */ /// BEGIN SOLUTION const size_t fold = 4; const size_t m = a.size / reduce_size; const size_t n = reduce_size; InvokeReduceFunc<scalar_t, max_reduce_func>(a.ptr, out->ptr, m, n, fold); /// END SOLUTION } 结语
CUDA并行计算入门比较容易,但是要做好很难。NVIDIA官方给了一些如何做性能优化的建议,这里贴在下面供大家参考

非常感谢NVIDIA的知识开源,这38页PPT可以算得上一个比较好的并行计算优化的教材了。
以上就是本系列文章的全部内容,很感谢屏幕前的读者朋友能耐心看到现在,希望这些内容能帮到大家,如果大家对文章内容有疑问也欢迎在评论区探讨。




![洛谷 P11345 [KTSC 2023 R2] 基地简化 题解](http://www.itfaba.com/wp-content/themes/kemi/timthumb.php?src=http://www.itfaba.com/wp-content/themes/kemi/img/random/1.jpg&w=218&h=124&zc=1)
