
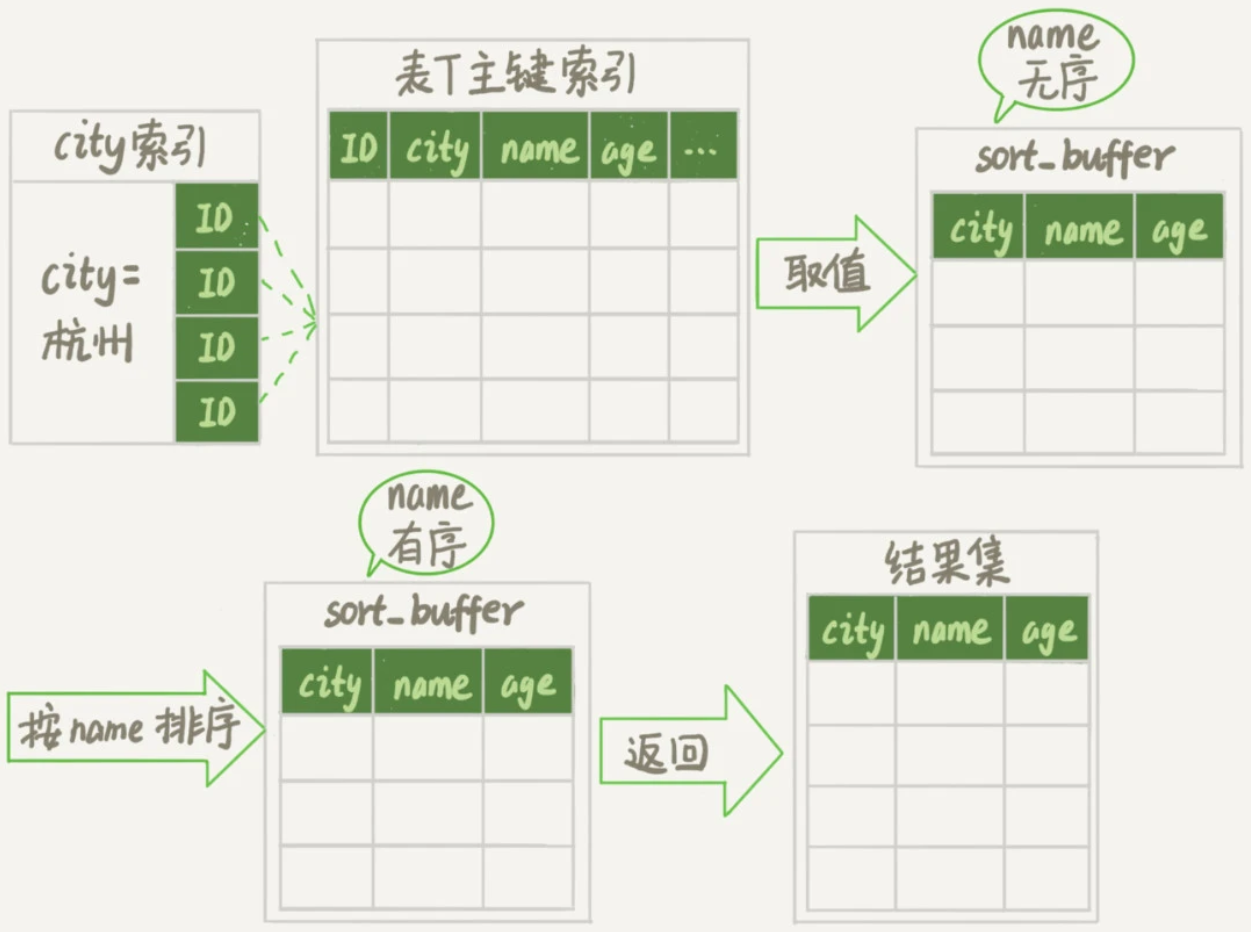
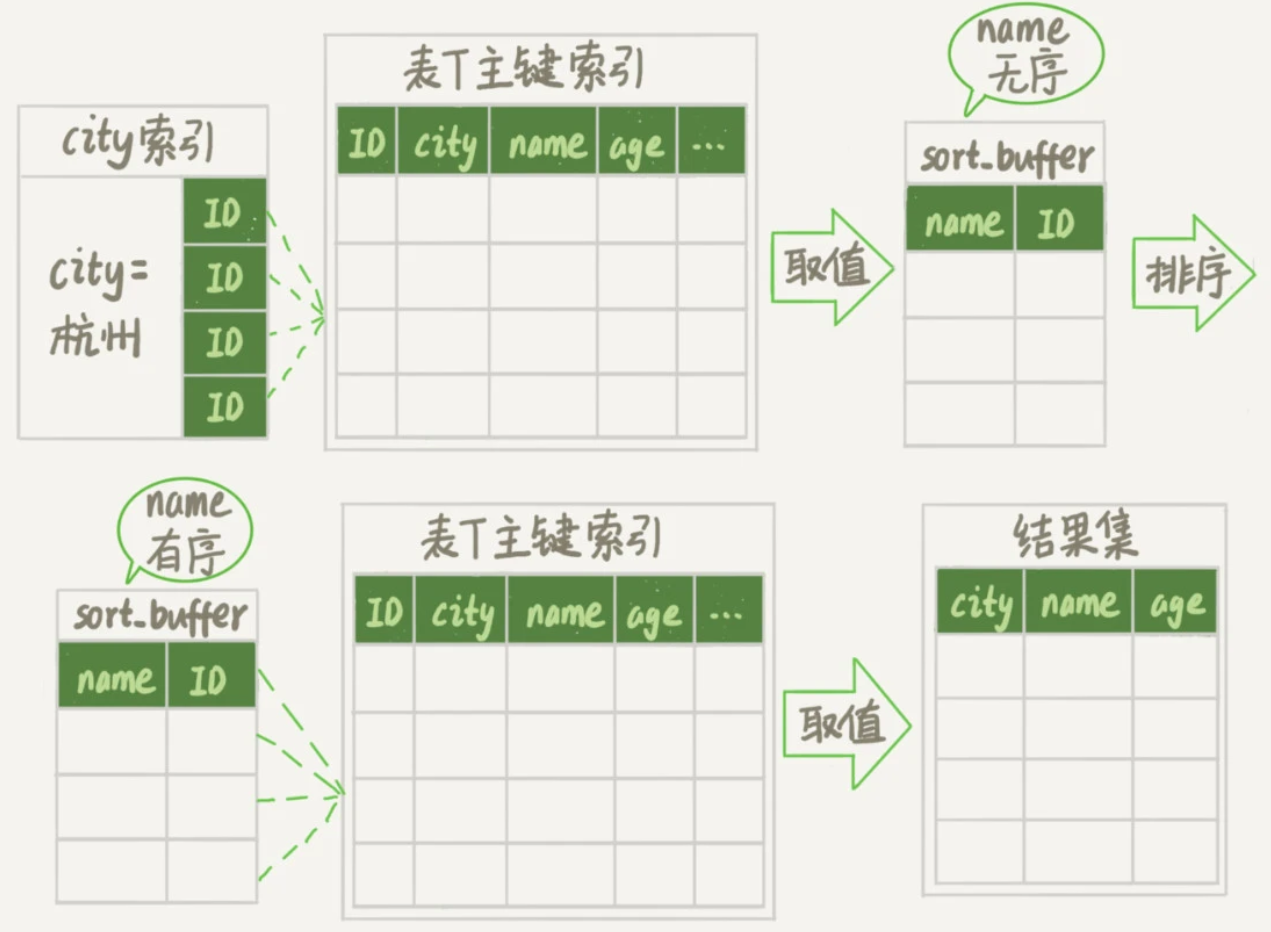
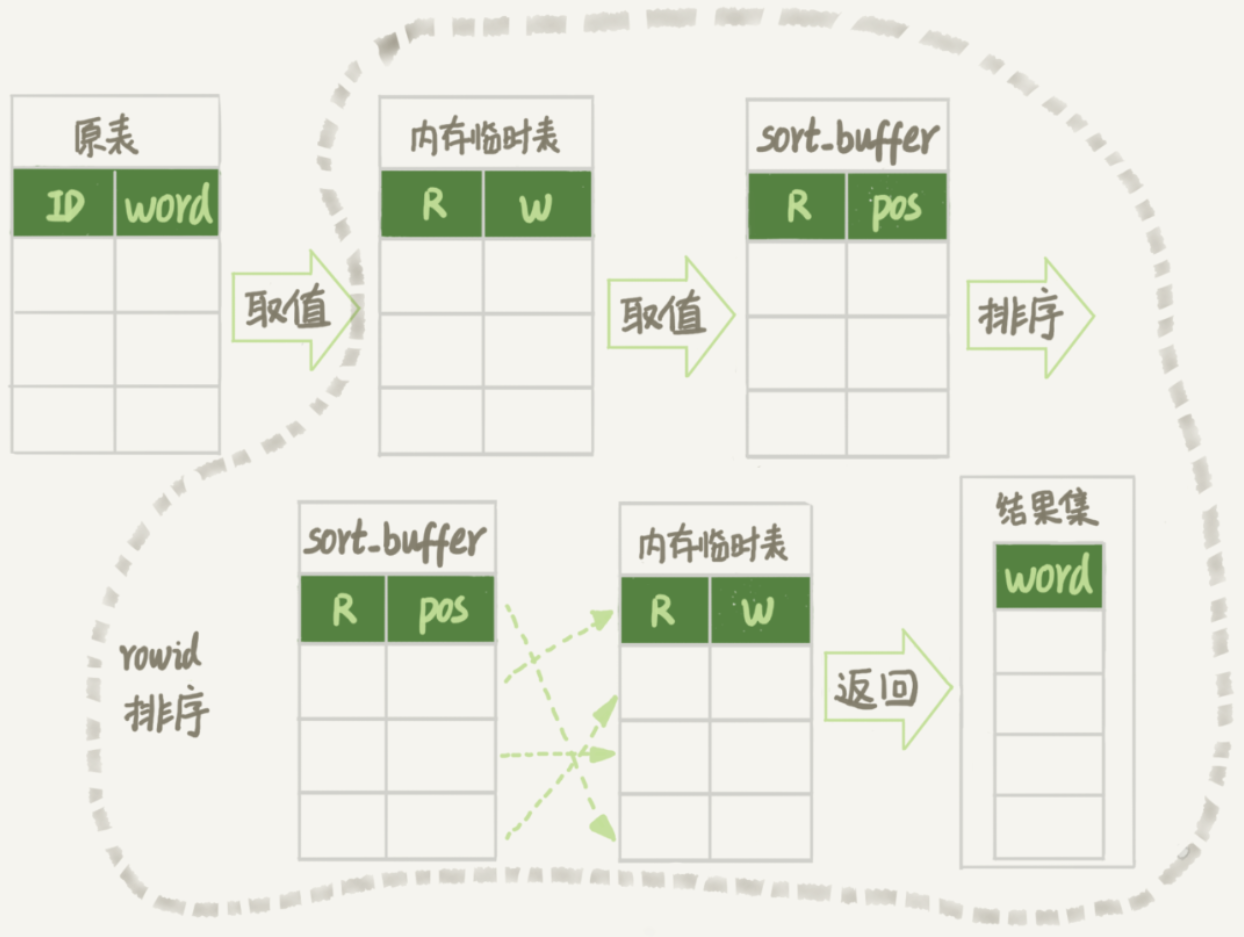
假设有一个场景,一个英语学习APP首页有一个随机显示单词的功能,用户每次访问首页的时候,都会随机滚动显示三个单词。
已知表里有10000条记录,来看看随机选择3个单词有什么方法,又存在什么问题。
建表语句:
mysql> CREATE TABLE `words` ( `id` int(11) NOT NULL AUTO_INCREMENT, `word` varchar(64) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB; 内存临时表
首先,可以使用order by rand()来实现:
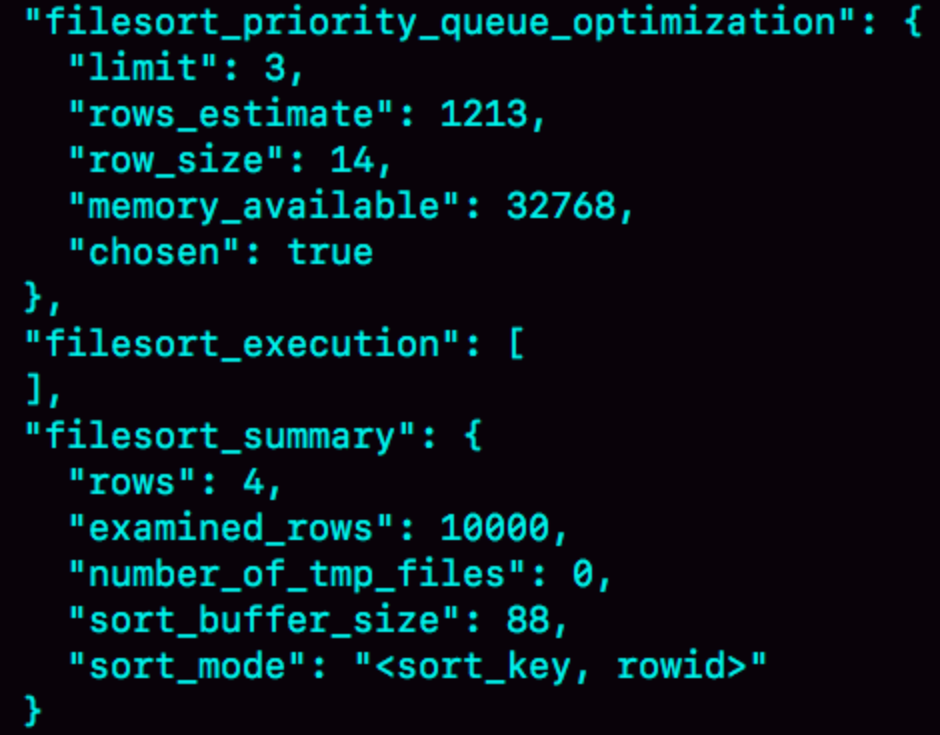
select word from words order by rand() limit 3; 该语句的执行情况:






![洛谷 P11345 [KTSC 2023 R2] 基地简化 题解](http://www.itfaba.com/wp-content/themes/kemi/timthumb.php?src=http://www.itfaba.com/wp-content/themes/kemi/img/random/2.jpg&w=218&h=124&zc=1)
