
1. 数据来源
本文所用数据集来自阿里云天池:
阿里云天池 - Audience Expansion Datasethttps://tianchi.aliyun.com/dataset/50893
该数据集包含三张表,分别记录了支付宝两组营销策略的活动情况:
effect_tb.csv: 广告点击情况数据集
emb_tb_2.csv: 用户特征数据集
seed_cand_tb.csv: 用户类型数据集
本篇文章中主要使用广告点击情况数据集effect_tb.csv。原始数据有四列,用到的是第二列到第四列的数据,涉及字段如下:
user_id:支付宝用户ID
label:用户当天是否点击活动广告(0:未点击,1:点击)
dmp_id:营销策略编号(源数据文档未作说明,这里根据数据情况设定为1:对照组,2:营销策略一,3:营销策略二)
2.数据处理
首先导入所需要的数据与Python 库
import pandas as pd import numpy as np import matplotlib.pyplot as plt %matplotlib inline # 导入数据 data = pd.read_csv(r"audience_expansioneffect_tb.csv",header = None) data.columns = ["dt","user_id","label","dmp_id"] # 日志天数属性用不上,删除该列 data = data.drop(columns = "dt") data.head(3) 查看数据行数与独立用户数检查是否存在重复行:
#数据行数 data.shape # 去重后行数 data.nunique() 数据行数2645958与独立用户数2410683不统一,检查一下重复行并删除:
#筛选出重复的user_id data[data.duplicated(keep = False)].sort_values(by = ["user_id"]) # 删除重复的行 data = data.drop_duplicates() # 再次检查是否有重复的行 data[data.duplicated(keep = False)] 结果为空,已删除所有的重复的user_id
接着看看有没有空白值。
#检查是否有空值 data.info(null_counts = True) 通过结果得到数据集无空值,无需进行处理。
拉一个透视表,生成label和dmp_id两列对应的值的计数情况,看看有没有异常值
data.pivot_table(index = "dmp_id", columns = "label", values = "user_id", aggfunc = "count", margins = True) 从结果看也没有异常值,无需处理
3.样本量检验
在进行A/B测试前,需检查样本容量是否满足试验所需最小值。当然在实际的AB test中在确定实验方案时就定好了所需要的样本量,这里由于我们拿到的是已有的数据,所以简单做个验证
这里借助之前说到的样本量计算工具:
https://www.evanmiller.org/ab-testing/sample-size.html
首先需要设定点击率基准线以及最小提升比例,我们将对照组的点击率设为基准线,在工具中计算可以得到最小样本量
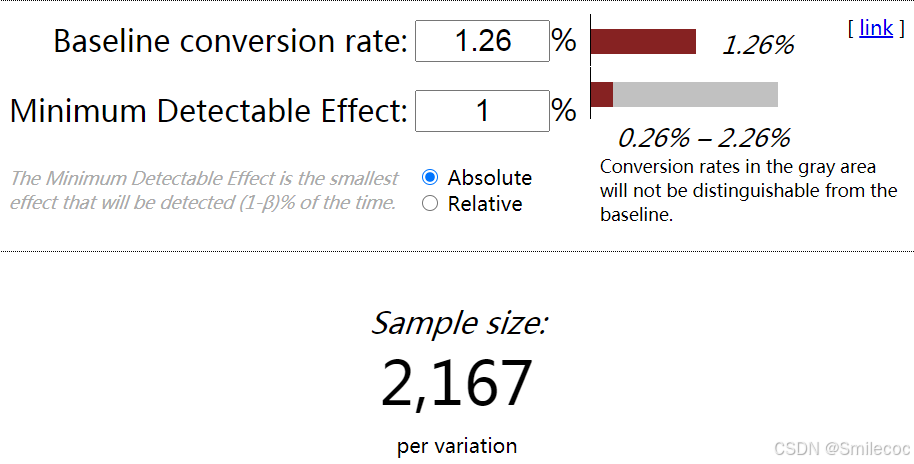
查看每个每个营销活动的样本数
#按照dmp_id分类计数 data["dmp_id"].value_counts() 两组营销活动的样本量分别为41.11万和31.62万,满足最小样本量需求。
3.假设检验
先计算几组试验的点击率情况
# 计算每组的点击率情况 print("对 照 组: " ,data[data["dmp_id"] == 1]["label"].mean()) print("营销策略一: " ,data[data["dmp_id"] == 2]["label"].mean()) print("营销策略二: " ,data[data["dmp_id"] == 3]["label"].mean()) #输出结果为: #对 照 组: 0.012551012429794775 #营销策略一: 0.015314747742072015 #营销策略二: 0.026191869198779274 可以看到策略一和策略二相较对照组在点击率上都有不同程度提升。
其中策略一提升0.2个百分点,策略二提升1.3个百分点,只有策略二满足了前面我们对点击率提升最小值的要求。
接下来需要进行假设检验,看策略二点击率的提升是否显著。
a. 原假设和备择假设
记对照组点击率为(p_1),策略二点击率为(p_2),则:
原假设 H0: (p_1 ≥ p_2)
备择假设 H1: (p_1< p_2)
b. 分布类型、检验类型和显著性水平
数据结果只有点击和不点击,样本服从二点分布,独立双样本,样本大小n>30,总体均值和标准差未知,所以采用Z检验。显著性水平α取0.05。
c. Z检验的统计量
1.单样本的比例Z检验
用于检验样本比例与总体比例是否有显著差异。其公式为:
其中:
(hat{p}) 是样本比例
(p) 是假设的总体比例
(n) 是样本量
2.独立双样本的比例Z检验
用于检验两个独立样本的比例是否有显著差异。其公式为:
其中:
(hat{p}_1 , hat{p}_2)分别是两个样本的比例
(p_1,p_2)分别是两个总体的比例
(n_1,n_2)分别是两个样本的样本量
当原假设为(H_0: p_1 = p_2)也就是总体比例相同时,我们可以使用公式:
其中(hat{p} = frac{x_1 + x_2}{n_1 + n_2})是总体的比例
https://www.stats.gov.cn/zs/tjll/csgj/202311/t20231127_1944929.html
首先根据公式手动计算一下检验统计量z:
# 样本数 n_old = len(data[data.dmp_id == 1]) # 对照组 n_new = len(data[data.dmp_id == 3]) # 策略二 # 点击数 c_old = len(data[data.dmp_id ==1][data.label == 1]) c_new = len(data[data.dmp_id ==3][data.label == 1]) # 计算点击率 r_old = c_old / n_old r_new = c_new / n_new # 总体点击率 r = (c_old + c_new) / (n_old + n_new) print("总体点击率:", r) # 计算检验统计量z z = (r_old - r_new) / np.sqrt(r * (1 - r)*(1/n_old + 1/n_new)) print("检验统计量z:", z) 计算得出检验统计量z为 -59.44168632985996
# 查α=0.05对应的z分位数 from scipy.stats import norm z_alpha = norm.ppf(0.05) z_alpha 当α=0.05是z检验统计量为-1.64, 检验统计量z = -59.44,该检验为左侧单尾检验,拒绝域为{z<z_alpha}。
所以我们可以得出结论:原假设不成立,策略二点击率的提升在统计上是显著的
当然也可以直接根据已有的Python公式计算:
import statsmodels.stats.proportion as sp z_score, p = sp.proportions_ztest([c_old, c_new],[n_old, n_new], alternative = "smaller") print("检验统计量z:",z_score,",p值:", p) 检验统计量z: -59.44168632985996 ,p值: 0.0
p值约等于0,p < α,与方法一结论相同,拒绝原假设。
参考文章:
https://zhuanlan.zhihu.com/p/68019926
https://www.heywhale.com/mw/project/5efee4a563975d002c98adba/content





