
目录
1. 是什么
- 使用双向链表+HashMap(数组+链表+红黑树)实现
- 相比于HashMap保存了顺序
- 迭代时输出的顺序是
- 按照插入节点的顺序来输出
- 也可以指定成按照访问的顺序输出(LRU)
- 迭代时输出的顺序是
2. 使用
- 按照插入节点的顺序来输出
public class LinkedHashMapTest { public static void main(String[] args) { LinkedHashMap<String,Object> map = new LinkedHashMap<>(); map.put("name","zsk"); map.put("age",24); map.put("height", 172L); Iterator<Map.Entry<String, Object>> iterator = map.entrySet().iterator(); while (iterator.hasNext()) { Map.Entry<String, Object> entry = iterator.next(); /*插入的顺序是怎样那么输出就是怎样 * name=zsk age=24 height=172 * */ System.out.println(entry); } //上面的输出跟这个一样 for (Map.Entry<String, Object> entry : map.entrySet()) { /*插入的顺序是怎样那么输出就是怎样 * name=zsk age=24 height=172 * */ System.out.println(entry); } System.out.println(map.containsKey("name"));//true System.out.println(map.get("name"));//zsk map.remove("name"); System.out.println(map.containsKey("name"));//false } } - 按照访问的顺序输出
public class LinkedHashMapTest { public static void main(String[] args) { LinkedHashMap<String, Object> map = new LinkedHashMap<>(2, 0.75F, true); map.put("1", "a"); map.put("2", "b"); map.put("3", "c"); Iterator<Map.Entry<String, Object>> iterator = map.entrySet().iterator(); while (iterator.hasNext()) { Map.Entry<String, Object> entry = iterator.next(); // 1=a // 2=b // 3=c System.out.println(entry); } //上面的输出跟这个一样 for (Map.Entry<String, Object> entry : map.entrySet()) { // 1=a // 2=b // 3=c System.out.println(entry); } System.out.println(map.get("1"));//访问了1,那么1所在的节点被移到链表末尾 for (Map.Entry<String, Object> entry : map.entrySet()) { //最近被访问的节点被放到链表末尾 // 2=b // 3=c // 1=a System.out.println(entry); } } } 3. 实现
3.1. uml
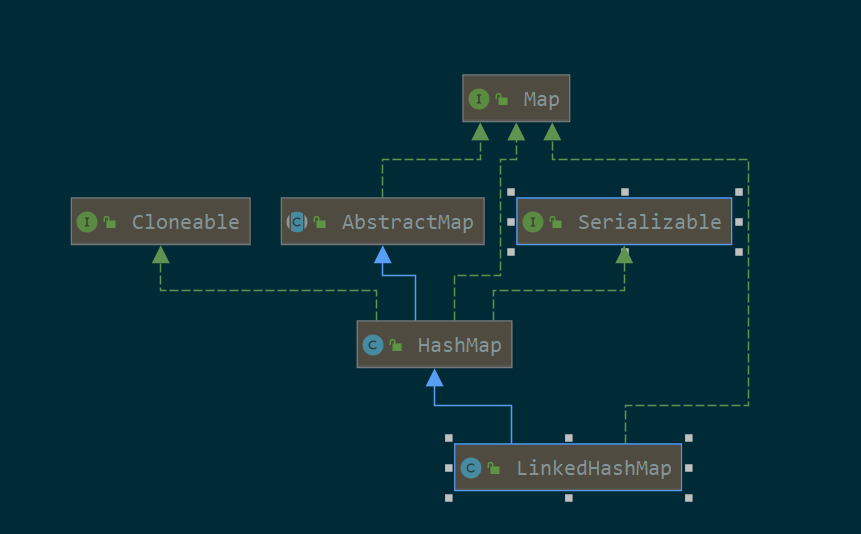
继承了HashMap,可克隆,可序列化
3.2. 构造方法
public class LinkedHashMap<K,V> extends HashMap<K,V>//继承HashMap implements Map<K,V> { //链表的节点。双向链表 static class Entry<K,V> extends HashMap.Node<K,V> { Entry<K,V> before, after; Entry(int hash, K key, V value, Node<K,V> next) { super(hash, key, value, next); } } //双向链表的头尾节点 transient LinkedHashMap.Entry<K,V> head; transient LinkedHashMap.Entry<K,V> tail; //true的话保持访问的顺序,false的话保持插入的顺序 final boolean accessOrder; public LinkedHashMap() { //调用HashMap的构造方法 super(); accessOrder = false; } } LinkedHashMap继承了HashMap,所以map的get、set、remove等方法都是调用的HashMap的方法,而且LinkedHashMap还增强了HashMap的Node,定义了自己的Entry,加入了双向链表
3.3. put
其实就是调用的HashMap的put方法把插入新的节点或者替换value,只不过多了一些其他操作
- HashMap.put
public V put(K key, V value) { return putVal(hash(key), key, value, false, true); } final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) { Node<K,V>[] tab; Node<K,V> p; int n, i; if ((tab = table) == null || (n = tab.length) == 0) n = (tab = resize()).length; if ((p = tab[i = (n - 1) & hash]) == null) //LinkedHashMap重写了newNode方法 tab[i] = newNode(hash, key, value, null); else { Node<K,V> e; K k; if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) e = p; else if (p instanceof TreeNode) e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); else { for (int binCount = 0; ; ++binCount) { if ((e = p.next) == null) { p.next = newNode(hash, key, value, null); if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st treeifyBin(tab, hash); break; } if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) break; p = e; } } //节点已经存在,只是更新value的情况 if (e != null) { // existing mapping for key V oldValue = e.value; if (!onlyIfAbsent || oldValue == null) e.value = value; //需要维护双向链表中的顺序 afterNodeAccess(e); return oldValue; } } ++modCount; if (++size > threshold) resize(); //removeEldest方法返回true的时候,需要删除头节点【最少访问的节点】 afterNodeInsertion(evict); return null; } 需要注意的以下几点:
- 12行:LinkedHashMap重写了newNode方法
- 35-42行:更新value之后要维护双向链表中的顺序
- 48行:不管是插入了新的节点还是更新了value,都需要根据情况(removeEldest方法是否返回true)删除链表头节点
3.3.1. 创建LinkedHashMap增强的节点--Entry【既是Node数组的节点又是双向链表的节点】
- LinkedHashMap.newNode
Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) { //创建的是LinkedHashMap增强的Entry LinkedHashMap.Entry<K,V> p = new LinkedHashMap.Entry<K,V>(hash, key, value, e); //插入到链表尾部 linkNodeLast(p); return p; } 3.3.1.1. 创建的时候就把节点插入到双向链表尾部
- linkNodeLast
private void linkNodeLast(LinkedHashMap.Entry<K,V> p) { LinkedHashMap.Entry<K,V> last = tail; tail = p; //把当前节点插入到链表的末尾的操作 if (last == null) head = p; else { p.before = last; last.after = p; } } 3.3.2. put的节点(不是新插入的而是更新value),需要维护双向链表的顺序【输出的顺序】
//节点已经存在,只是更新value的情况 if (e != null) { // existing mapping for key V oldValue = e.value; if (!onlyIfAbsent || oldValue == null) e.value = value; //需要维护双向链表中的顺序 afterNodeAccess(e); return oldValue; } 3.3.2.1. 把这个节点移动到双向链表尾部
- afterNodeAccess
void afterNodeAccess(Node<K,V> e) { // move node to last LinkedHashMap.Entry<K,V> last; //指定了访问顺序 并且 当前节点不是尾巴节点【即不是新插入的节点】 if (accessOrder && (last = tail) != e) { LinkedHashMap.Entry<K,V> p = (LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after; //以下的操作把当前节点移动到双向链表的末尾 p.after = null; if (b == null) head = a; else b.after = a; if (a != null) a.before = b; else last = b; if (last == null) head = p; else { p.before = last; last.after = p; } tail = p; ++modCount; } } 3.3.3. put的节点(不管是新插入的还是更新value)后判断是否需要删除头节点【最少访问的节点】
- afterNodeInsertion
void afterNodeInsertion(boolean evict) { // possibly remove eldest LinkedHashMap.Entry<K,V> first; //removeEldestEntry返回true的时候【场景:比如定义LRU算法超过一定容量删除最少访问的节点】 if (evict && (first = head) != null && removeEldestEntry(first)) { //删除头节点 K key = first.key; removeNode(hash(key), key, null, false, true); } } 3.4. get
其实就是调用HashMap的getNode方法获取节点,然后在调用LinkedHashMap的afterNodeAccess把访问的当前节点放到链表的末尾
- LinkedHashMap.get
public V get(Object key) { Node<K,V> e; //调用HashMap的getNode获取节点 if ((e = getNode(hash(key), key)) == null) return null; //如果设置按照访问顺序的话,那么 if (accessOrder) afterNodeAccess(e); return e.value; } - 7-8行:如果设置按照访问顺序的话,那么调用LinkedHashMap的afterNodeAccess把当前访问的节点移动到双向链表的末尾(最新的节点)
3.4.1. get节点后需要维护双向链表的顺序【输出的顺序】
//如果设置按照访问顺序的话,那么 if (accessOrder) afterNodeAccess(e); 3.4.1.1. 把访问的当前节点放到链表的末尾
- LinkedHashMap afterNodeAccess
同put操作一样,就是把访问的当前节点放到链表的末尾
void afterNodeAccess(Node<K,V> e) { // move node to last LinkedHashMap.Entry<K,V> last; if (accessOrder && (last = tail) != e) { //p代表当前节点,a代表后一个节点,b代表前一个节点 LinkedHashMap.Entry<K,V> p = (LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after; //前面节点的next指向后一个节点 p.after = null; if (b == null) head = a; else b.after = a; //后一个节点的prev指向前一个节点 if (a != null) a.before = b; else last = b; //当前节点的prev指向尾节点,尾节点的next指向当前节点 if (last == null) head = p; else { p.before = last; last.after = p; } //更新尾节点为当前节点 tail = p; ++modCount; } } 3.5. containsKey
就是调用HashMap的containsKey方法
public boolean containsKey(Object key) { //依然是HashMap.getNode,没什么特殊的地方 return getNode(hash(key), key) != null; } 3.6. containsValue
重写了HashMap的方法,效率更高
public boolean containsValue(Object value) { //遍历双向链表,效率O(N),不同于HashMap的O(N2) for (LinkedHashMap.Entry<K,V> e = head; e != null; e = e.after) { V v = e.value; if (v == value || (value != null && value.equals(v))) return true; } return false; } 3.7. remove
其实就是调用HashMap的remove方法删除节点,再调用LinkedHashMap的afterNodeRemoval把当前节点从双向链表中删除
- HashMap.remove
public V remove(Object key) { Node<K,V> e; return (e = removeNode(hash(key), key, null, false, true)) == null ? null : e.value; } final Node<K,V> removeNode(int hash, Object key, Object value, boolean matchValue, boolean movable) { Node<K,V>[] tab; Node<K,V> p; int n, index; if ((tab = table) != null && (n = tab.length) > 0 && (p = tab[index = (n - 1) & hash]) != null) { Node<K,V> node = null, e; K k; V v; if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) node = p; else if ((e = p.next) != null) { if (p instanceof TreeNode) node = ((TreeNode<K,V>)p).getTreeNode(hash, key); else { do { if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) { node = e; break; } p = e; } while ((e = e.next) != null); } } if (node != null && (!matchValue || (v = node.value) == value || (value != null && value.equals(v)))) { if (node instanceof TreeNode) ((TreeNode<K,V>)node).removeTreeNode(this, tab, movable); else if (node == p) tab[index] = node.next; else p.next = node.next; ++modCount; --size; //删除了节点后需要维护双向链表 afterNodeRemoval(node); return node; } } return null; } 3.7.1. remove节点后需要从双向链表删除该节点
- LinkedHashMap afterNodeRemoval
void afterNodeRemoval(Node<K,V> e) { // unlink //以下的操作把当前删除的节点从双向链表中删除 //p是当前被删除的节点,b是p的前一个节点,a是p的后一个节点 LinkedHashMap.Entry<K,V> p = (LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after; p.before = p.after = null; //修改前一个节点的next指针 if (b == null) head = a; else b.after = a; //修改后一个节点的prev指针 if (a == null) tail = b; else a.before = b; } 3.8. entrySet
3.8.1. 要研究的代码
Iterator<Map.Entry<String, Object>> iterator = map.entrySet().iterator(); - LinkedHashMap entrySet
public Set<Map.Entry<K,V>> entrySet() { Set<Map.Entry<K,V>> es; //这个entrySet属性什么时候set的? //返回LinkedEntrySet return (es = entrySet) == null ? (entrySet = new LinkedEntrySet()) : es; } 调用map.entrySet()返回的是LinkedEntrySet,如下
3.8.2. LinkedHashMap.entrySet()返回的是LinkedEntrySet
- LinkedEntrySet
final class LinkedEntrySet extends AbstractSet<Map.Entry<K,V>> { public final int size() { return size; } public final void clear() { LinkedHashMap.this.clear(); } public final Iterator<Map.Entry<K,V>> iterator() { //遍历器是LinkedEntryIterator return new LinkedEntryIterator(); } public final boolean contains(Object o) { if (!(o instanceof Map.Entry)) return false; Map.Entry<?,?> e = (Map.Entry<?,?>) o; Object key = e.getKey(); Node<K,V> candidate = getNode(hash(key), key); return candidate != null && candidate.equals(e); } public final boolean remove(Object o) { if (o instanceof Map.Entry) { Map.Entry<?,?> e = (Map.Entry<?,?>) o; Object key = e.getKey(); Object value = e.getValue(); return removeNode(hash(key), key, value, true, true) != null; } return false; } public final Spliterator<Map.Entry<K,V>> spliterator() { return Spliterators.spliterator(this, Spliterator.SIZED | Spliterator.ORDERED | Spliterator.DISTINCT); } public final void forEach(Consumer<? super Map.Entry<K,V>> action) { if (action == null) throw new NullPointerException(); int mc = modCount; for (LinkedHashMap.Entry<K,V> e = head; e != null; e = e.after) action.accept(e); if (modCount != mc) throw new ConcurrentModificationException(); } } 再调用LinkedEntrySet的iterator返回的是LinkedEntryIterator
3.8.3. LinkedHashMap.entrySet().iterator()返回的是LinkedEntryIterator
final class LinkedEntryIterator extends LinkedHashIterator//继承了LinkedHashIterator implements Iterator<Map.Entry<K,V>> { //重写了next方法,调用LinkedHashIterator的nextNode public final Map.Entry<K,V> next() { return nextNode(); } } 这个LinkedEntryIterator继承了LinkedHashIterator,如下
3.8.3.1. LinkedEntryIterator继承了LinkedHashIterator
- LinkedHashIterator
abstract class LinkedHashIterator { LinkedHashMap.Entry<K,V> next; LinkedHashMap.Entry<K,V> current; int expectedModCount; LinkedHashIterator() { //从链表头部开始遍历 next = head; expectedModCount = modCount; current = null; } public final boolean hasNext() { return next != null; } //next会调用这个方法 final LinkedHashMap.Entry<K,V> nextNode() { LinkedHashMap.Entry<K,V> e = next; if (modCount != expectedModCount) throw new ConcurrentModificationException(); if (e == null) throw new NoSuchElementException(); //链表中当前节点的下一个节点 current = e; next = e.after; return e; } public final void remove() { Node<K,V> p = current; if (p == null) throw new IllegalStateException(); if (modCount != expectedModCount) throw new ConcurrentModificationException(); current = null; K key = p.key; //HashMap的removeNode方法 removeNode(hash(key), key, null, false, false); expectedModCount = modCount; } } 可以看出迭代输出的时候是从头到尾输出的,也就是旧的先打印,然后在打印新的节点
4. 总结
在HashMap的基础上+双向链表实现的
迭代LinkedHashMap,就是从内部维护的双链表的表头开始循环输出。
而双链表节点的顺序在LinkedHashMap的get、put时都会更新。以满足按照插入顺序输出,还是访问顺序输出。




