
使用shuffle sharding增加容错性
最近在看kubernetes的API Priority and Fairness,它使用shuffle sharding来为请求选择处理队列,以此防止高吞吐量流挤占低吞吐量流,进而造成请求延迟的问题。
介绍
首先看下什么是shuffle sharding,下面内容来自aws的Workload isolation using shuffle-sharding。
首先来看如何使用一般分片方式来让系统具备可扩展性和弹性。
假设有一个8 workers节点的水平可扩展的系统或服务,下图红线表示达到这些节点的请求,worker可以是服务,队列或数据库等。


如果没有任何分片,则要求每个worker能够处理所有请求。这种方式高效且具备一定的冗余性。如果一个worker出现故障,则可以将它的任务分配到剩余的7个worker上。此时可能需要增加一定的系统容量。但如果突然出现大量请求,如DDoS攻击,可能会导致级联故障。下面两张图展示了故障是如何升级的。

首先会影响第一台worker,随后会级联到其他workers上,最终导致整个服务不可用。

为了防止故障转移,通常可以使用分片方式,如将workers分为4个分片,以效率换取影响度。下面两张图展示了如何使用分片来限制DDoS攻击。

本例中,每个分片包含2个workers,并按照资源(如域名)进行切片。此时的系统仍然具有冗余性,但由于每个分片只有2个workers,因此可能需要增加容量来避免故障。

通过这种方式降低了故障影响范围。这里有4个分片,如果一个分片故障,则只会影响该分片上的服务,其他分片则不受影响。影响范围为25%。使用shuffle sharding可以达到更好的效果。
shuffle sharding用到了虚拟分片(shuffle shard)的概念,这里将不会直接对workers进行分片,而是按照"用户"进行分片,目的是尽量将用户打散分布到不同的worker上。
下图展示的shuffle sharding布局中包含8个workers和8个客户,并给每个客户分配了2个workers。以彩虹和玫瑰表示的客户为例。
这里,我们给彩虹客户分配了第1个和第4个worker,这两个workers构成了该客户的shuffle shard,其他客户将使用不同的虚拟分片(含2个workers),如玫瑰客户分配了第1个和最后一个worker。

如果彩虹用户分配的worker 1和worker 4出现了问题(如恶意请求或请求泛红等),则此问题只会影响本虚拟分片,但不会影响到其他shuffle shard。事实上,最多只会有另外一个shuffle shard会受到影响(即另外一个服务都部署到了worker 1和worker 4)。如果请求方具有容错性,则可以继续使用剩余分片继续提供服务。

换句话说,当彩虹客户所在的节点因为出现问题或受到攻击而无法提供服务时,不会影响到其他节点。对于客户而言,虽然玫瑰客户和向日葵客户都和彩虹客户共享了worker,但并没有导致其服务中断,玫瑰客户仍然可以继续使用workers 8提供服务,而向日葵客户可以继续使用worker 6提供服务。
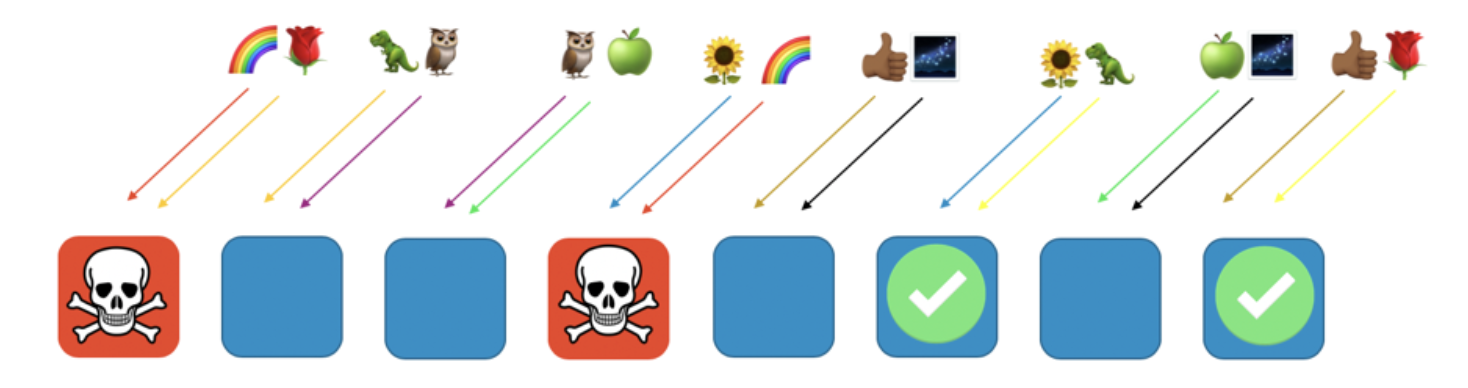
当出现上述问题时,虽然失去了四分之一的worker节点,但使用shuffle sharding可以大大降低影响范围。上述场景下,一共有28种两两worker的组合方式,即28种shuffle shards。当有上百甚至更多的客户时,我们可以给每个客户分配一个shuffle shards,以此可以将影响范围缩小到1/28,效果是一般分片方式的7倍。
kubernetes中的shuffle sharding
使用shuffle sharding为流分片队列
kubernetes的流控功能中使用了shuffle sharding,其代码实现如下:
func NewDealer(deckSize, handSize int) (*Dealer, error) { if deckSize <= 0 || handSize <= 0 { return nil, fmt.Errorf("deckSize %d or handSize %d is not positive", deckSize, handSize) } if handSize > deckSize { return nil, fmt.Errorf("handSize %d is greater than deckSize %d", handSize, deckSize) } if deckSize > 1<<26 { return nil, fmt.Errorf("deckSize %d is impractically large", deckSize) } if RequiredEntropyBits(deckSize, handSize) > MaxHashBits { return nil, fmt.Errorf("required entropy bits of deckSize %d and handSize %d is greater than %d", deckSize, handSize, MaxHashBits) } return &Dealer{ deckSize: deckSize, handSize: handSize, }, nil } func (d *Dealer) Deal(hashValue uint64, pick func(int)) { // 15 is the largest possible value of handSize var remainders [15]int //这个for循环用于生成[0,deckSize)范围内的随机数。 for i := 0; i < d.handSize; i++ { hashValueNext := hashValue / uint64(d.deckSize-i) remainders[i] = int(hashValue - uint64(d.deckSize-i)*hashValueNext) hashValue = hashValueNext } for i := 0; i < d.handSize; i++ { card := remainders[i] for j := i; j > 0; j-- { if card >= remainders[j-1] { card++ } } pick(card) } } func (d *Dealer) DealIntoHand(hashValue uint64, hand []int) []int { h := hand[:0] d.Deal(hashValue, func(card int) { h = append(h, card) }) return h } -
首先使用
func NewDealer(deckSize, handSize int)初始化一个实例,以kubernetes的APF功能为例,deckSize为队列数,handSize表示为一条流分配的队列数量 -
使用
func (d *Dealer) DealIntoHand(hashValue uint64, hand []int)可以返回为流选择的队列ID,hashValue可以看做是流的唯一标识,hand为存放结果的数组。hashValue的计算方式如下,fsName为flowschemas的名称,fDistinguisher可以是用户名或namespace名称:func hashFlowID(fsName, fDistinguisher string) uint64 { hash := sha256.New() var sep = [1]byte{0} hash.Write([]byte(fsName)) hash.Write(sep[:]) hash.Write([]byte(fDistinguisher)) var sum [32]byte hash.Sum(sum[:0]) return binary.LittleEndian.Uint64(sum[:8]) }
用法如下:
var backHand [8]int deal, _ := NewDealer(128, 9) fmt.Println(deal.DealIntoHand(8238791057607451177, backHand[:])) //输出:[41 119 0 49 67] 为请求分片队列
上面为流分配了队列,实现了流之间的队列均衡。此时可能为单条流分配了多个队列,下一步就是将单条流的请求均衡到分配到的各个队列中。核心代码如下:
func (qs *queueSet) shuffleShardLocked(hashValue uint64, descr1, descr2 interface{}) int { var backHand [8]int // Deal into a data structure, so that the order of visit below is not necessarily the order of the deal. // This removes bias in the case of flows with overlapping hands. //获取本条流的队列列表 hand := qs.dealer.DealIntoHand(hashValue, backHand[:]) handSize := len(hand) //qs.enqueues表示队列中的请求总数,这里第一次哈希取模算出队列的起始偏移量 offset := qs.enqueues % handSize qs.enqueues++ bestQueueIdx := -1 minQueueSeatSeconds := fqrequest.MaxSeatSeconds //这里用到了上面的偏移量,并考虑到了队列处理延迟,找到延迟最小的那个队列作为目标队列 for i := 0; i < handSize; i++ { queueIdx := hand[(offset+i)%handSize] queue := qs.queues[queueIdx] queueSum := queue.requests.QueueSum() // this is the total amount of work in seat-seconds for requests // waiting in this queue, we will select the queue with the minimum. thisQueueSeatSeconds := queueSum.TotalWorkSum klog.V(7).Infof("QS(%s): For request %#+v %#+v considering queue %d with sum: %#v and %d seats in use, nextDispatchR=%v", qs.qCfg.Name, descr1, descr2, queueIdx, queueSum, queue.seatsInUse, queue.nextDispatchR) if thisQueueSeatSeconds < minQueueSeatSeconds { minQueueSeatSeconds = thisQueueSeatSeconds bestQueueIdx = queueIdx } } ... return bestQueueIdx } 



