
1.算法仿真效果
matlab2022a仿真结果如下(完整代码运行后无水印):

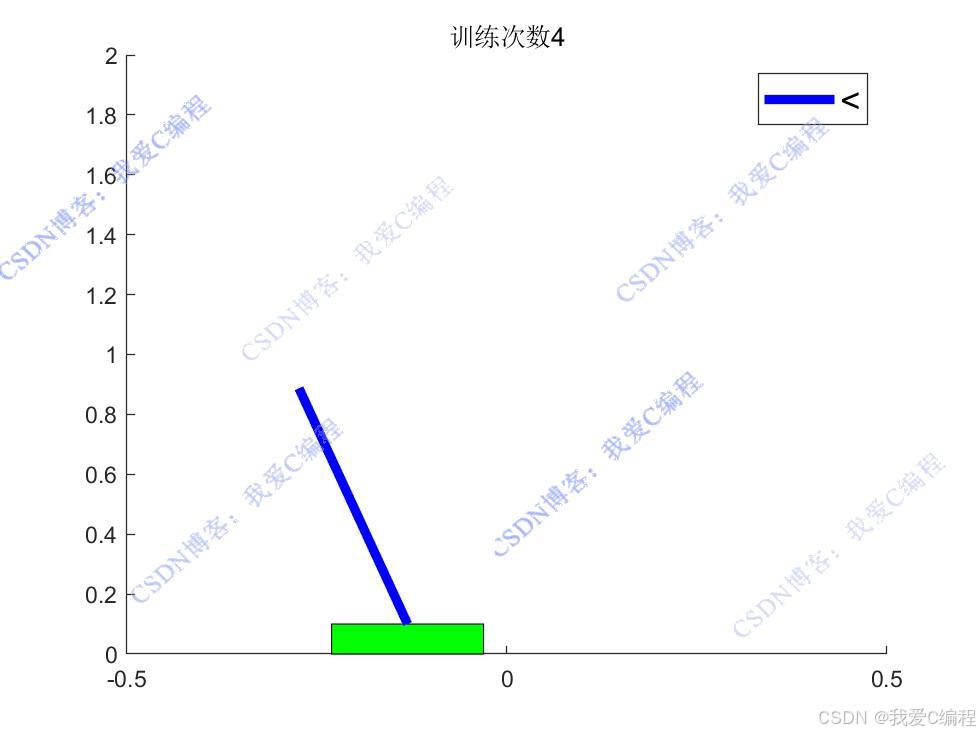
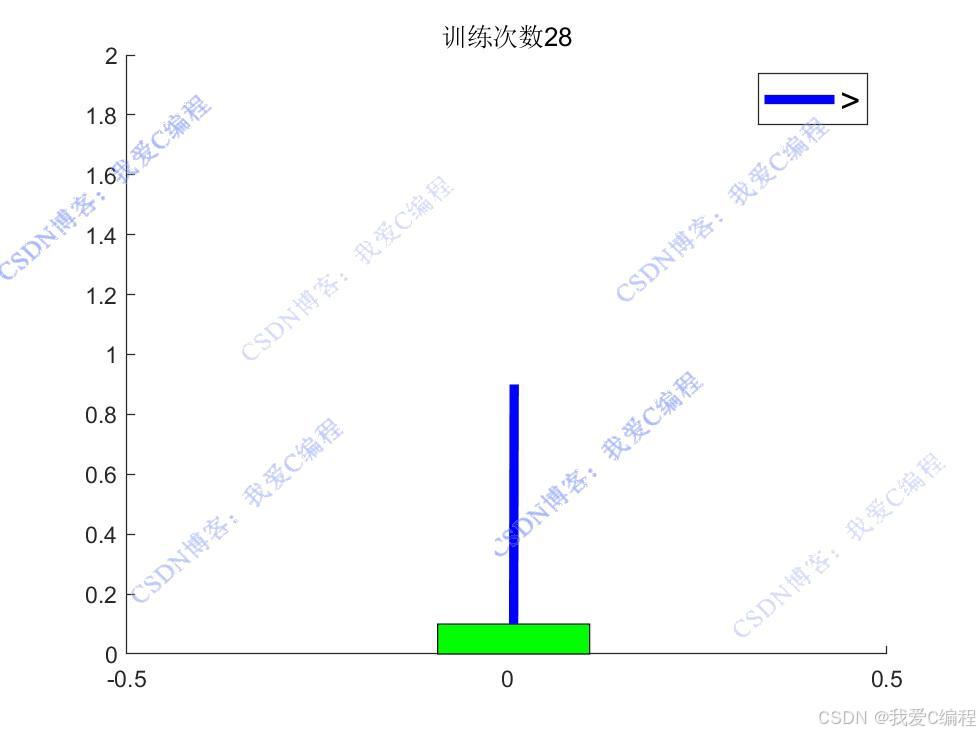

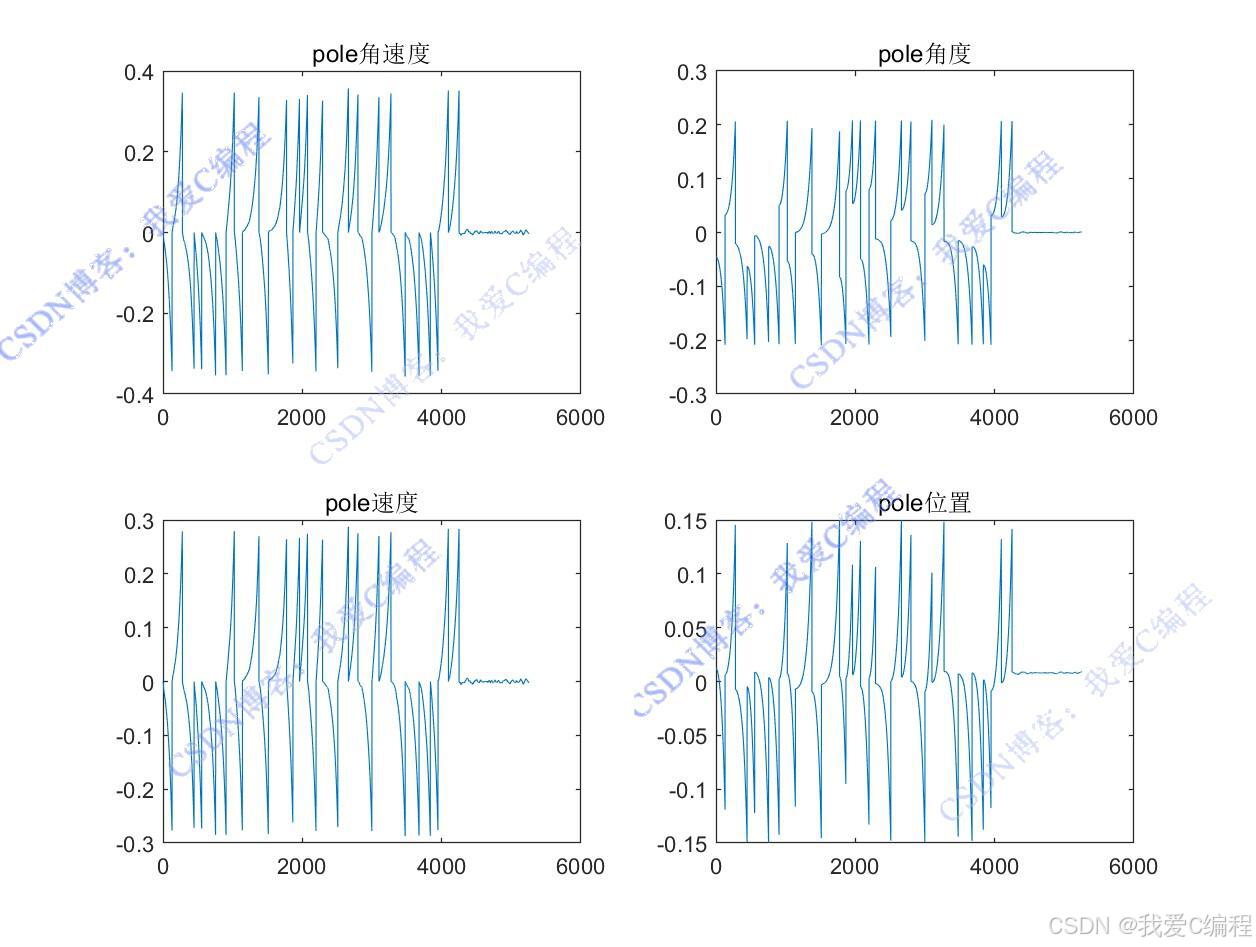
通过不断与环境交互并更新Q值函数,智能体能够逐渐学习到在不同状态下的最优动作,从而实现杆的平衡控制。
仿真操作步骤可参考程序配套的操作视频。
2.算法涉及理论知识概要
强化学习作为一种强大的机器学习范式,为解决这类复杂的控制问题提供了有效的途径。其中,Q-learning算法因其简单性和通用性,在Cart-Pole推车杆平衡控制系统中得到了广泛应用。本文将深入探讨基于Q-learning强化学习的Cart-Pole推车杆平衡控制系统的原理。
Cart-Pole物理模型
Cart-Pole系统由一个可在水平轨道上移动的推车和一根通过铰链连接在推车上的杆组成。假设推车的质量为

这些方程描述了系统状态随时间的变化规律,是理解和控制Cart-Pole系统的基础。
Cart-Pole推车杆平衡控制系统的目标是设计一个控制器,通过施加合适的力F,使杆在尽可能长的时间内保持垂直平衡状态(即 θ≈0),同时确保推车不超出轨道边界。在实际应用中,这一问题的解决方案可以推广到机器人平衡控制、火箭姿态调整等领域。
Q-learning强化学习
强化学习是一种通过智能体(Agent)与环境(Environment)进行交互,以最大化累积奖励(Reward)为目标的机器学习方法。在Cart-Pole系统中,智能体就是负责控制推车运动的控制器,环境则是Cart-Pole系统本身。
Q值函数的更新规则为:
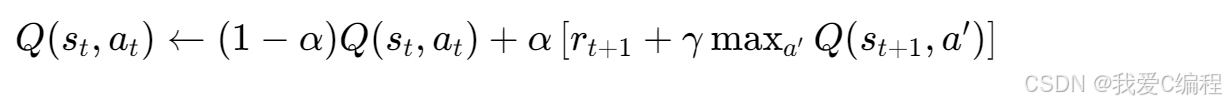
控制每次更新的步长。学习率越大,新的经验对Q值的影响越大;学习率越小,Q值的更新越依赖于之前的估计。
在训练完成后,使用训练好的Q表进行测试。在测试过程中,智能体采用贪心策略(即 ϵ=0)选择动作,观察Cart-Pole系统在不同初始状态下的平衡控制效果。可以通过计算系统保持平衡的平均时间、成功平衡的次数等指标来评估控制器的性能。
3.MATLAB核心程序
............................................................. % 绘制新的状态 figure(1); % 计算杆的两个端点的 x 坐标 X = [Pos_car, Pos_car+Lens*sin(Ang_car)]; % 计算杆的两个端点的 y 坐标 Y = [0.1, 0.1+Lens*cos(Ang_car)]; % 绘制小车,用绿色矩形表示 obj=rectangle('Position',[Pos_car-0.1,0,0.2,0.1],'facecolor','g'); hold on % 绘制杆,用蓝色粗线表示 obj2=plot(X,Y,'b','LineWidth',4); hold on % 设置坐标轴范围 axis([-0.5 0.5 0 2]); % 根据外力方向显示图例 if F > 0 legend('>','FontSize', 15); else legend('<','FontSize', 15); end % 更新图形窗口的标题,显示训练次数和最大成功次数 title(strcat('训练次数',num2str(iters))); hold off % 绘制平均 Q 值随训练次数的变化曲线 figure plot(Q_save); % 设置 x 轴标签 xlabel('训练次数'); % 设置 y 轴标签 ylabel('Q value收敛值'); % 绘制子图 figure % 绘制第一个子图,显示杆的角速度随训练次数的变化 subplot(221); plot(Vang_car_save); % 设置子图标题 title('pole角速度'); % 绘制第二个子图,显示杆的角度随训练次数的变化 subplot(222); plot(Ang_car_save); % 设置子图标题 title('pole角度'); % 绘制第三个子图,显示小车的速度随训练次数的变化 subplot(223); plot(V_car_save); % 设置子图标题 title('pole速度'); % 绘制第四个子图,显示小车的位置随训练次数的变化 subplot(224); plot(Pos_car_save); % 设置子图标题 title('pole位置'); 0Z_016m




![洛谷 P11345 [KTSC 2023 R2] 基地简化 题解](http://www.itfaba.com/wp-content/themes/kemi/timthumb.php?src=http://www.itfaba.com/wp-content/themes/kemi/img/random/1.jpg&w=218&h=124&zc=1)
