

什么是 Direct3D 12?
DirectX 12 引入了 Direct3D 的下一个版本,即 DirectX 的核心 3D 图形 API。
此版本的 Direct3D 比任何以前的版本更快、更高效。
Direct3D 12 可实现更丰富的场景、更多的对象、更复杂的效果,以及充分利用现代 GPU 硬件。
若要为 Windows 10 和 Windows 10 移动版编写 3D 游戏和应用,必须了解 Direct3D 12 技术的基础知识,以及如何准备在游戏和应用中使用它。
D3DApp初始化
Windows函数调用过程
调用者(caller) → 参数准备 → call指令 → 被调用者(callee)执行 → 返回 → 栈清理
栈的基本原理
想象栈就像一个临时工作台:
- 调用函数时:把参数"放"到工作台上
- 函数执行时:从工作台"拿"参数使用
- 函数结束后:需要把工作台"清理干净"
规则:
-
调用Windows API时:不用管清理,Windows会处理
-
写回调函数时:必须用__stdcall,并在返回时清理栈
-
调用C运行时函数时:编译器会自动帮"我"清理栈
-
写C++成员函数时:编译器自动处理,不用操心
-
"我"调用Windows → Windows清理
-
Windows调用"我" → "我"清理
-
"我"调用C运行时 → "我"清理(编译器帮忙)
-
"我"的C++方法 → "我"清理(编译器自动处理)
如果不清理会怎样?
void FunctionA(int x, int y) { // 使用x,y... } void FunctionB(int a, int b, int c) { // 使用a,b,c... } int main() { FunctionA(1, 2); // 栈上放了 [1, 2] // 如果不清理,栈上还有 [1, 2] FunctionB(3, 4, 5); // 栈变成 [3, 4, 5, 1, 2] ← 混乱! } 清理栈就是调整栈指针(ESP),让栈回到函数调用前的状态:
调用前:ESP指向位置X 调用时:push参数 → ESP移动到位置Y (Y < X) 清理后:ESP回到位置X // ✅ 正确:调用Windows API(不用管清理) MessageBox(NULL, "Text", "Title", MB_OK); // ✅ 正确:写回调函数(用CALLBACK宏) LRESULT CALLBACK MyCallback(HWND, UINT, WPARAM, LPARAM); // ✅ 正确:调用可变参数函数(编译器自动清理) printf("Values: %d %d", x, y); // ❌ 错误:回调函数不用__stdcall LRESULT MyBadCallback(HWND, UINT, WPARAM, LPARAM); // 会崩溃! 机制举例
__cdecl - "我请客,我收拾"
// "我"调用printf(Windows的C运行时库) printf("Count: %d %d", 10, 20); ; "我"调用printf后 push offset text ; 参数3 push value ; 参数2 push num ; 参数1 push offset format ; 参数0 call printf add esp, 16 ; ⭐"我"清理栈:4个参数×4字节 分工:
"我":放参数 + 清理栈
Windows/CRT:只用参数,不清理
__stdcall - "Windows服务,Windows收拾"
// "我"调用Windows API CreateWindow(className, title, style, x, y, width, height, ...); ; "我"调用CreateWindow后 push 0 ; 参数11 push hInstance ; 参数10 ; ... 更多参数 ... push className ; 参数1 call CreateWindowEx ; ⭐没有add esp! Windows会自己清理 分工:
"我":放参数
Windows:用参数 + 清理栈
__stdcall回调 - "Windows调用,我收拾"
// Windows调用"我"的回调 LRESULT CALLBACK MyWindowProc(HWND, UINT, WPARAM, LPARAM); ; Windows调用"我"的WndProc _WndProc@16: ; "我"的处理逻辑... ret 16 ; ⭐"我"清理16字节参数 分工:
Windows:放参数
"我":用参数 + 清理栈
__fastcall - "快速服务,Windows收拾"
// 假设是Windows的某个性能API int __fastcall FastAPI(int a, int b, int c); 分工:
"我":前两个参数放寄存器,其余放栈
Windows:用参数 + 清理栈上的参数
- 性能优化:寄存器比内存快
- Windows负责清理,保持API一致性
__thiscall - "对象方法,我收拾"
// "我"的C++类 class MyClass { public: void Method(int param); // 自动__thiscall }; 分工:
"我":this放寄存器,参数放栈
"我":用参数 + 清理栈
- C++对象模型,"我"完全控制自己的类
- 编译器自动处理,对"我"透明
创建一个Windows窗口

LRESULT CALLBACK MainWndProc(HWND hwnd, UINT msg, WPARAM wParam, LPARAM lParam) { // Forward hwnd on because we can get messages (e.g., WM_CREATE) // before CreateWindow returns, and thus before mhMainWnd is valid. //转发消息给 D3DApp::GetApp()->MsgProc() return D3DApp::GetApp()->MsgProc(hwnd, msg, wParam, lParam); } bool D3DApp::InitMainWindow() { // 设置窗口类属性 WNDCLASS wc; // 窗口尺寸变化时重绘 ,CS_HREDRAW 宽度改变时重绘 ,CS_VREDRAW 高度改变时重绘 wc.style = CS_HREDRAW | CS_VREDRAW; // 建立消息处理回调机制,所有发送到此窗口的消息都由该函数处理 , 在代码中,MainWndProc 转发消息给 D3DApp::GetApp()->MsgProc() wc.lpfnWndProc = MainWndProc; // 应用程序实例句柄 wc.hInstance = mhAppInst; // 额外的类内存 ,用于存储自定义数据,这里设为0表示不需要 wc.cbClsExtra = 0; // 额外的窗口内存字节数 ,用于存储自定义数据,这里设为0表示不需要 wc.cbWndExtra = 0; // 加载系统预定义的应用程序图标 wc.hIcon = LoadIcon(0, IDI_APPLICATION); // 加载系统预定义的箭头光标 wc.hCursor = LoadCursor(0, IDC_ARROW); // 窗口背景画刷 NULL_BRUSH 表示不绘制背景,适合DirectX应用(因为DirectX会完全覆盖客户区). 避免GDI与DirectX绘制冲突 wc.hbrBackground = (HBRUSH)GetStockObject(NULL_BRUSH); // 设为0表示此窗口类没有菜单 wc.lpszMenuName = 0; // 窗口类名称,用于在系统中唯一标识此窗口类 wc.lpszClassName = L"MainWnd"; //将定义好的窗口类注册到操作系统中. Windows机制:系统内部维护一个窗口类表;注册成功后,该类可用于创建多个窗口实例;失败通常是因为类名重复或参数无效. if( !RegisterClass(&wc) ) { MessageBox(0, L"RegisterClass Failed.", 0, 0); return false; } // Compute window rectangle dimensions based on requested client area dimensions. /* 窗口尺寸计算: 客户区 (Client Area):应用程序实际可绘制内容的区域(mClientWidth × mClientHeight) 窗口矩形 (Window Rect):包含标题栏、边框、菜单等的完整窗口 AdjustWindowRect 根据窗口样式自动计算转换关系 . ┌─────────────────────────┐ │ 标题栏 (非客户区) │ ├────────────┬────────────┤ │ │ │ │ │ │ │ 客户区 │ 滚动条 │ │ │ (非客户区) │ │ │ │ └────────────┴────────────┘ 原始客户区: (0,0) 到 (800,600) AdjustWindowRect 调整后: 可能变成 (-8,-31) 到 (808,631) 最终窗口尺寸: 816 × 662 像素 */ RECT R = { 0, 0, mClientWidth, mClientHeight }; AdjustWindowRect(&R, WS_OVERLAPPEDWINDOW, false); int width = R.right - R.left; int height = R.bottom - R.top; /* 窗口创建: L"MainWnd":窗口类名,必须与注册的类名一致 | WS_OVERLAPPEDWINDOW:窗口样式,包含标题栏、系统菜单、最小化/最大化按钮、可调整边框 CW_USEDEFAULT, CW_USEDEFAULT:窗口初始位置,让系统自动选择 Windows创建机制:系统分配内部窗口数据结构 | 发送 WM_CREATE 等初始化消息 | 返回唯一的窗口句柄 mhMainWnd */ mhMainWnd = CreateWindow(L"MainWnd", mMainWndCaption.c_str(), WS_OVERLAPPEDWINDOW, CW_USEDEFAULT, CW_USEDEFAULT, width, height, 0, 0, mhAppInst, 0); if( !mhMainWnd ) { MessageBox(0, L"CreateWindow Failed.", 0, 0); return false; } //改变窗口可视状态为显示 ShowWindow(mhMainWnd, SW_SHOW); //强制发送 WM_PAINT 消息,立即重绘窗口 UpdateWindow(mhMainWnd); return true; } 
MainWndProc 相关API
https://learn.microsoft.com/zh-cn/windows/win32/winmsg/window-notifications
https://learn.microsoft.com/zh-cn/windows/win32/api/_winmsg/
PeekMessage: 检查线程消息队列中是否有消息,如果有消息 将消息复制到提供的msg结构中,PM_REMOVE标志表示从队列中移除该消息
LRESULT D3DApp::MsgProc(HWND hwnd, UINT msg, WPARAM wParam, LPARAM lParam) { switch(msg) { if(PeekMessage( &msg, 0, 0, 0, PM_REMOVE )) { //... } // 各种消息处理 case // ... } return DefWindowProc(hwnd, msg, wParam, lParam); } 窗口消息
WM_ACTIVATE- 窗口激活状态变化
case WM_ACTIVATE: //LOWORD(wParam):低16位表示激活状态 //WA_INACTIVE:窗口变为非活动状态 //失活时暂停,激活时恢复,智能暂停机制提升系统整体性能 if( LOWORD(wParam) == WA_INACTIVE ) { mAppPaused = true; mTimer.Stop(); } else { mAppPaused = false; mTimer.Start(); } return 0; WM_SIZE- 窗口尺寸变化
LOWORD 和 HIWORD 是 Windows API 中的宏定义,用于从一个 32 位值中提取低 16 位和高 16 位部分。
case WM_SIZE: mClientWidth = LOWORD(lParam); // 新宽度 mClientHeight = HIWORD(lParam); // 新高度 • 低 16 位 (LOWORD) 存储新宽度(以像素为单位)
• 高 16 位 (HIWORD) 存储新高度(以像素为单位)
SIZE_MINIMIZED最小化情况,完全暂停应用程序,不进行任何渲染
SIZE_MAXIMIZED最大化情况,立即调整D3D资源适应新尺寸
SIZE_RESTORED恢复情况(最复杂)
else if( wParam == SIZE_RESTORED ) { // 从最小化恢复 if( mMinimized ) { mAppPaused = false; mMinimized = false; OnResize(); } // 从最大化恢复 else if( mMaximized ) { mAppPaused = false; mMaximized = false; OnResize(); } // 用户正在拖拽调整大小 //拖拽时不立即调整,避免频繁资源重建 else if( mResizing ) { // 故意不调用OnResize() - 性能优化 } // 程序化尺寸改变 else { OnResize(); } } WM_ENTERSIZEMOVE / WM_EXITSIZEMOVE - 调整大小过程管理
WM_ENTERSIZEMOVE:开始拖拽,设置标志位暂停调整
WM_EXITSIZEMOVE:结束拖拽,清除标志位并执行最终调整
case WM_ENTERSIZEMOVE: mAppPaused = true; mResizing = true; mTimer.Stop(); return 0; case WM_EXITSIZEMOVE: mAppPaused = false; mResizing = false; mTimer.Start(); OnResize(); // 拖拽结束后一次性调整 return 0; WM_DESTROY - 窗口销毁
发送 WM_QUIT 到消息队列,导致 Run() 中的主循环退出
PostQuitMessage(0) → 系统消息队列 → 线程消息队列 → PeekMessage() → msg变量
Windows消息系统架构
系统消息队列 (全局)
↓
线程消息队列 (每个线程独立)
↓
PeekMessage/GetMessage (应用程序检索)
case WM_DESTROY: PostQuitMessage(0); return 0; int D3DApp::Run() { MSG msg = {0}; mTimer.Reset(); while(msg.message != WM_QUIT) { if(PeekMessage( &msg, 0, 0, 0, PM_REMOVE )) { TranslateMessage( &msg ); DispatchMessage( &msg ); } return (int)msg.wParam; } WM_MENUCHAR- 菜单字符处理
处理 Alt+Enter 等组合键,避免系统蜂鸣声
MNC_CLOSE表示关闭菜单而不发出蜂鸣
case WM_MENUCHAR: return MAKELRESULT(0, MNC_CLOSE); WM_GETMINMAXINFO- 窗口尺寸限制
设置窗口最小尺寸为 200×200,防止窗口过小导致渲染问题
case WM_GETMINMAXINFO: ((MINMAXINFO*)lParam)->ptMinTrackSize.x = 200; ((MINMAXINFO*)lParam)->ptMinTrackSize.y = 200; return 0; 鼠标消息处理
GET_X_LPARAM(lParam):从 lParam 提取 X 坐标
GET_Y_LPARAM(lParam):从 lParam 提取 Y 坐标
wParam:按键状态(Ctrl、Shift 等)
设计模式:使用虚函数提供扩展点,派生类可重写鼠标处理
case WM_LBUTTONDOWN: case WM_MBUTTONDOWN: case WM_RBUTTONDOWN: OnMouseDown(wParam, GET_X_LPARAM(lParam), GET_Y_LPARAM(lParam)); return 0; // 类似的鼠标抬起和移动处理 WM_KEYUP- 键盘按键处理
ESC键:优雅退出应用程序
F2键:运行时切换4倍多重采样抗锯齿状态
case WM_KEYUP: if(wParam == VK_ESCAPE) { PostQuitMessage(0); // ESC键退出 } else if((int)wParam == VK_F2) Set4xMsaaState(!m4xMsaaState); // F2切换抗锯齿 return 0; 初始化Direct3D
COM
COM(Component Object Model)是 Microsoft 的组件对象模型,它是 Windows 生态系统的基石
COM 的核心思想是二进制级别的兼容性:
- 不同编译器生成的 COM 组件可以互操作
- 不同语言(C++、C#、VB、Delphi)可以互相调用
- 进程内(DLL)和进程外(EXE)组件统一模型
IUnknown
// IUnknown 是每个 COM 接口都必须继承的基接口 class IUnknown { public: virtual HRESULT QueryInterface(REFIID riid, void** ppvObject) = 0; // 当新的代码段获得接口指针时,必须调用 AddRef() 来增加引用计数。 virtual ULONG AddRef() = 0; // 当不再需要接口指针时调用,减少引用计数。当计数为 0 时,对象自我销毁。 virtual ULONG Release() = 0; }; QueryInterface - 接口查询
// 检查对象是否支持特定接口,如果支持则返回该接口指针 virtual HRESULT QueryInterface(REFIID riid, void** ppvObject) = 0; // 假设我们有一个 IUnknown 指针 IUnknown* pUnknown = ...; // 查询 ID3D12Device 接口 ID3D12Device* pDevice = nullptr; HRESULT hr = pUnknown->QueryInterface(IID_ID3D12Device, (void**)&pDevice); if (SUCCEEDED(hr)) { // 可以使用 ID3D12Device 接口 pDevice->CreateCommandQueue(...); pDevice->Release(); // 使用完后释放 } COM 对象生命周期管理
引用计数规则
class ReferenceCountingExample { public: void CorrectReferenceCounting() { // 场景1:创建新对象 IUnknown* pObj = CreateNewObject(); // 引用计数 = 1 // 场景2:复制指针 IUnknown* pCopy = pObj; pCopy->AddRef(); // 现在引用计数 = 2 // 场景3:使用完副本 pCopy->Release(); // 引用计数 = 1 // 场景4:使用完原始指针 pObj->Release(); // 引用计数 = 0 → 对象销毁 } void CommonMistakes() { // 错误:忘记 AddRef IUnknown* pOriginal = CreateNewObject(); // 计数 = 1 IUnknown* pCopy = pOriginal; // 计数还是 1! pOriginal->Release(); // 计数 = 0 → 对象销毁! // pCopy 现在指向已销毁的对象! // 错误:忘记 Release - 内存泄漏! IUnknown* pObj = CreateNewObject(); // 计数 = 1 // 使用对象... // 忘记调用 pObj->Release() - 对象永远不会销毁! } }; COM接口定义
接口标识符 (IID)
每个 COM 接口都有一个全局唯一标识符 (GUID):
// IID 定义示例 // {接口名称}-{唯一标识符} DEFINE_GUID(IID_IMyInterface, 0x12345678, 0x1234, 0x1234, 0x12, 0x34, 0x12, 0x34, 0x56, 0x78, 0x9a, 0xbc); COM 在 DirectX 12 中的应用
DirectX COM 接口使用
class D3D12COMUsage { public: void TypicalD3D12Usage() { // 1. 创建 DXGI 工厂 IDXGIFactory4* pFactory = nullptr; CreateDXGIFactory1(IID_PPV_ARGS(&pFactory)); // 2. 创建设备 ID3D12Device* pDevice = nullptr; D3D12CreateDevice(nullptr, D3D_FEATURE_LEVEL_11_0, IID_PPV_ARGS(&pDevice)); // 3. 创建命令队列 ID3D12CommandQueue* pCommandQueue = nullptr; D3D12_COMMAND_QUEUE_DESC queueDesc = {}; pDevice->CreateCommandQueue(&queueDesc, IID_PPV_ARGS(&pCommandQueue)); // 使用对象... // 4. 按创建顺序的逆序释放 pCommandQueue->Release(); pDevice->Release(); pFactory->Release(); } }; 现代 C++ COM 编程
在现代 DirectX 12 编程中,虽然我们使用 ComPtr 等智能指针来简化 COM 编程,但理解底层的 COM 机制对于调试和理解系统行为仍然至关重要。
// 使用 ComPtr 简化 COM 编程 void ModernCOMProgramming() { // 自动管理引用计数 ComPtr<IDXGIFactory4> factory; ComPtr<ID3D12Device> device; ComPtr<ID3D12CommandQueue> commandQueue; // 创建对象(自动管理引用计数) CreateDXGIFactory1(IID_PPV_ARGS(&factory)); D3D12CreateDevice(nullptr, D3D_FEATURE_LEVEL_11_0, IID_PPV_ARGS(&device)); D3D12_COMMAND_QUEUE_DESC queueDesc = {}; device->CreateCommandQueue(&queueDesc, IID_PPV_ARGS(&commandQueue)); // 不需要手动调用 Release() - ComPtr 自动处理! // 接口查询也很简单 ComPtr<IDXGIDevice> dxgiDevice; device.As(&dxgiDevice); // 自动 QueryInterface } ComPtr
ComPtr 是 Microsoft::WRL (Windows Runtime C++ Template Library) 中的智能指针模板类,专门用于管理 COM 对象的生命周期。
详情:https://learn.microsoft.com/zh-cn/cpp/cppcx/wrl/comptr-class?view=msvc-170
核心功能:
- 自动引用计数管理
- 异常安全的资源清理
- 简化 COM 接口指针操作
#include <wrl.h> using namespace Microsoft::WRL; // 基本用法 ComPtr<ID3D12Device> device; // 传统方式 - 容易出错 ID3D12Device* pDevice = nullptr; ID3D12CommandQueue* pQueue = nullptr; HRESULT hr = D3D12CreateDevice(nullptr, D3D_FEATURE_LEVEL_11_0, IID_PPV_ARGS(&pDevice)); if (SUCCEEDED(hr)) { // 创建命令队列 hr = pDevice->CreateCommandQueue(..., IID_PPV_ARGS(&pQueue)); } // 必须手动释放 - 容易忘记! if (pQueue) pQueue->Release(); if (pDevice) pDevice->Release(); // 容易漏掉! // ComPtr 方式 - 自动管理生命周期 ComPtr<ID3D12Device> device; ComPtr<ID3D12CommandQueue> queue; ThrowIfFailed(D3D12CreateDevice(nullptr, D3D_FEATURE_LEVEL_11_0, IID_PPV_ARGS(&device))); ThrowIfFailed(device->CreateCommandQueue(..., IID_PPV_ARGS(&queue))); // 不需要手动 Release() - 自动处理! ComPtr内部维护一个指针
template <typename T> class ComPtr { public: using InterfaceType = T ; protected: InterfaceType *ptr_; public: T* Get() const throw() { return ptr_; } T** GetAddressOf() throw() { return &ptr_; } InterfaceType* operator->() const throw() { return ptr_; } } 异常检测
ThrowIfFailed宏
#define FAILED(hr) (((HRESULT)(hr)) < 0) #define ThrowIfFailed(x) { HRESULT hr__ = (x); std::wstring wfn = AnsiToWString(__FILE__); if(FAILED(hr__)) { throw DxException(hr__, L#x, wfn, __LINE__); } } DxException(hr__, // 1. HRESULT 错误代码 L#x, // 2. 失败的函数调用表达式 wfn, // 3. 文件名 __LINE__); // 4. 行号 FILE:预定义宏,展开为当前源文件的完整路径(ANSI 字符串)
DxException
class DxException { public: DxException() = default; DxException(HRESULT hr, const std::wstring& functionName, const std::wstring& filename, int lineNumber); std::wstring ToString()const; HRESULT ErrorCode = S_OK; std::wstring FunctionName; std::wstring Filename; int LineNumber = -1; }; DxException::DxException(HRESULT hr, const std::wstring& functionName, const std::wstring& filename, int lineNumber) : ErrorCode(hr),FunctionName(functionName),Filename(filename),LineNumber(lineNumber) {} 在WinMain中使用:
int WINAPI WinMain(HINSTANCE hInstance, HINSTANCE prevInstance, PSTR cmdLine, int showCmd) { try { InitDirect3DApp theApp(hInstance); if(!theApp.Initialize()) return 0; return theApp.Run(); } catch(DxException& e) { MessageBox(nullptr, e.ToString().c_str(), L"HR Failed", MB_OK); return 0; } } Debug
ComPtr<ID3D12Debug> debugController; ThrowIfFailed(D3D12GetDebugInterface(IID_PPV_ARGS(&debugController))); debugController->EnableDebugLayer(); ID3D12Debug 是一个接口,专门用于启用和控制 Direct3D 12 的调试功能
它不是渲染管线的一部分,而是开发时的辅助工具
主要功能:
- 错误检查:验证参数是否正确,捕获非法调用
- 资源追踪:检测资源泄漏和错误使用
- 状态验证:确保资源状态转换正确
- 性能分析:识别性能瓶颈
- 详细输出:在 Visual Studio 输出窗口显示详细信息
DXGIFactory
工厂模式:用于创建其他图形相关对象的"工厂"
DXGI:DirectX Graphics Infrastructure
ThrowIfFailed(CreateDXGIFactory1(IID_PPV_ARGS(&mdxgiFactory))); 应用程序 ↓ 使用 IDXGIFactory4 (图形工厂) ├── 创建交换链 (IDXGISwapChain) ├── 枚举适配器 (显卡) └── 查询显示模式 ID3D12Device
该设备是一个虚拟适配器,使用它来创建命令列表、管道状态对象、根签名、命令分配器、命令队列、围栏、资源、描述符和描述符堆。
计算机可能具有多个 GPU,因此可以使用 DXGI 工厂枚举设备,并查找第一个功能级别 11(与 direct3d 12 兼容)的设备
找到要使用的适配器索引后,通过调用 D3D12CreateDevice() 创建设备。
IID_PPV_ARGS
#define IID_PPV_ARGS(ppType) __uuidof(**(ppType)), IID_PPV_ARGS_Helper(ppType) __uuidof 运算符:Microsoft 特有的编译器扩展,在编译时获取 COM 接口的 GUID/IID,不需要运行时查询
&device // 类型: ComPtr<ID3D12Device>* *(&device) // 类型: ComPtr<ID3D12Device>& **(&device) // 类型: ID3D12Device* __uuidof(**(&device)) → __uuidof(ID3D12Device*) → 编译时得到 ID3D12Device 的 IID IID_PPV_ARGS_Helper 函数的参数是ComPtrRef 而不是ComPtr.
ComPtrRef 包装ComPtr的引用,用于安全地传递 COM 接口指针
返回值:void** COM 方法通常需要 void** 参数来接收接口指针
//COM 方法通常需要 void** 参数来接收接口指针, 例如: HRESULT QueryInterface(REFIID riid, void** ppvObject); HRESULT D3D12CreateDevice(..., REFIID riid, void** ppDevice); // Overloaded global function to provide to IID_PPV_ARGS that support Details::ComPtrRef template<typename T> void** IID_PPV_ARGS_Helper(_Inout_ ::Microsoft::WRL::Details::ComPtrRef<T> pp) throw() { static_assert(__is_base_of(IUnknown, typename T::InterfaceType), "T has to derive from IUnknown"); return pp; } - 确保模板参数 T 的接口类型继承自 IUnknown
- 所有 COM 接口都必须继承自 IUnknown
- 编译时失败,避免运行时错误
// 错误用法:非 COM 接口 ComPtr<std::string> badPtr; // 编译错误! D3D12CreateDevice(..., IID_PPV_ARGS(&badPtr)); // static_assert 失败:std::string 不继承自 IUnknown // 使用示例: // 原始 COM 调用(繁琐且容易出错) ID3D12Device* rawDevice = nullptr; HRESULT hr = D3D12CreateDevice( nullptr, D3D_FEATURE_LEVEL_11_0, IID_ID3D12Device, reinterpret_cast<void**>(&rawDevice) // 需要显式转换 ); // 使用宏(类型安全且简洁) ComPtr<ID3D12Device> device; HRESULT hr = D3D12CreateDevice( nullptr, D3D_FEATURE_LEVEL_11_0, IID_PPV_ARGS(&device) // 自动处理所有细节 ); Device
HRESULT WINAPI D3D12CreateDevice(_In_opt_ IUnknown* pAdapter, D3D_FEATURE_LEVEL MinimumFeatureLevel, _In_ REFIID riid, // Expected: ID3D12Device _COM_Outptr_opt_ void** ppDevice ); // 尝试硬件设备 HRESULT hardwareResult = D3D12CreateDevice(nullptr, D3D_FEATURE_LEVEL_11_0, IID_PPV_ARGS(&md3dDevice)); ID3D12Device (设备对象 - 最重要的对象) ├── 创建命令队列和列表 ├── 创建资源(纹理、缓冲区) ├── 创建管线状态对象 ├── 创建描述符堆 └── 查询设备能力 SAL
详情:https://learn.microsoft.com/zh-cn/cpp/code-quality/understanding-sal?view=msvc-170
HRESULT WINAPI D3D12CreateDevice( _In_opt_ IUnknown* pAdapter, D3D_FEATURE_LEVEL MinimumFeatureLevel, _In_ REFIID riid, // Expected: ID3D12Device _COM_Outptr_opt_ void** ppDevice ); 这个函数签名中有一些奇怪的宏,_In_opt_ _In_ _COM_Outptr_opt_
// e.g. void SetPoint( _In_ const POINT* pPT ); #define _In_ _SAL2_Source_(_In_, (), _Pre1_impl_(__notnull_impl_notref) _Pre_valid_impl_ _Deref_pre1_impl_(__readaccess_impl_notref)) #define _In_opt_ _SAL2_Source_(_In_opt_, (), _Pre1_impl_(__maybenull_impl_notref) _Pre_valid_impl_ _Deref_pre_readonly_) #define _COM_Outptr_opt_ __allowed(on_parameter) SAL 是 Microsoft 源代码注释语言,注释是在头文件 <sal.h> 中定义的。
通过使用源代码注释,可以在代码中明确表明你的意图。 这些注释还能使自动化静态分析工具更准确地分析代码,明显减少假正和假负情况。
void * memcpy( void *dest, const void *src, size_t count ); 你能判断出此函数的作用吗? 实现或调用函数时,必须维护某些属性以确保程序正确性。
只看本示例中的这类声明无法判断它们是什么。
如果没有 SAL 注释,就只能依赖于文档或代码注释。

HRESULT WINAPI D3D12CreateDevice( _In_opt_ IUnknown* pAdapter, D3D_FEATURE_LEVEL MinimumFeatureLevel, _In_ REFIID riid, // Expected: ID3D12Device _COM_Outptr_opt_ void** ppDevice ); ComPtr<ID3D12Device> device; // 根据注解,我们知道: // - 第一个参数可以传 nullptr(使用默认显卡) // - 第二个参数必须传有效的功能级别 // - 第三个参数必须传有效的 IID // - 第四个参数可以传 nullptr(如果我们不想要设备对象) HRESULT hr = D3D12CreateDevice( nullptr, // _In_opt_ → 可选,传 nullptr 使用默认 D3D_FEATURE_LEVEL_11_0, // 必须的有效枚举值 IID_PPV_ARGS(&device) // _In_ + _COM_Outptr_opt_ → 必须有效的 IID,输出设备 ); 理解这些注解可以帮助你:
- 正确使用 API 函数
- 编写更安全的代码
- 更好地理解 Microsoft 的 API 设计哲学
GPU命令
命令列表 (Command List) - 录制器
ComPtr<ID3D12GraphicsCommandList> mCommandList;
命令列表由 ID3D12CommandList 接口表示,并由设备接口使用 CreateCommandList() 方法创建。
使用命令列表来分配要在 GPU 上执行的命令。命令可能包括设置管道状态、设置资源、转换资源状态( 资源屏障 )、设置顶点/索引缓冲区、绘制、清除渲染目标、设置渲染目标视图、执行捆绑包 (命令组)等。
命令列表与命令分配器相关联,命令分配器将命令存储在 GPU 上。
当第一次创建命令列表时,需要使用标志指定D3D12_COMMAND_LIST_TYPE它是什么类型的命令列表,并提供与该列表关联的命令分配器。有 4 种类型的命令列表;直接、捆绑、计算和复制。
直接命令列表是 GPU 可以执行的命令列表。直接命令列表需要与直接命令分配器(使用D3D12_COMMAND_LIST_TYPE_DIRECT标志创建的命令分配器)相关联。
当完成命令列表的填充后,必须调用 close() 方法将命令列表设置为未记录状态。调用 close 后,可以使用命令队列来执行命令列表。
就像电影导演的剧本 📝
- 包含要执行的具体指令序列
- 可以预先录制,反复使用
- 录制完成后关闭,不能再修改
命令队列 (Command Queue) - 执行管道
ComPtr<ID3D12CommandQueue> mCommandQueue;
就像电影放映机 🎬
- 接收并顺序执行命令列表
- 管理 GPU 的执行顺序
- 提供执行状态反馈
为什么需要两个结构?
1.录制与执行的分离
// 传统方式(DX11):立即模式 device->Draw(); // 立即执行,无法优化 // DX12 方式:延迟执行 commandList->Draw(); // 只是录制命令 // ... 可以继续录制更多命令 commandList->Close(); // 完成录制 commandQueue->ExecuteCommandLists(1, &commandList); // 批量提交执行 2.多线程命令录制
// 线程1:录制渲染命令 void Thread1_Render() { commandList1->Reset(); commandList1->SetPipelineState(pso1); commandList1->Draw(...); commandList1->Close(); } // 线程2:录制计算命令 void Thread2_Compute() { commandList2->Reset(); commandList2->SetPipelineState(pso2); commandList2->Dispatch(...); commandList2->Close(); } // 主线程:批量提交 void MainThread_Submit() { ID3D12CommandList* lists[] = {commandList1.Get(), commandList2.Get()}; commandQueue->ExecuteCommandLists(2, lists); // 一次提交所有 } CPU 端: ┌─────────────────┐ ┌─────────────────┐ ┌─────────────────┐ │ 命令列表 A │ │ 命令列表 B │ │ 命令列表 C │ │ (线程1录制) │ │ (线程2录制) │ │ (线程3录制) │ │ • SetPipeline │ │ • SetPipeline │ │ • SetPipeline │ │ • SetRootSig │ │ • SetRootSig │ │ • SetRootSig │ │ • Draw Mesh │ │ • Draw Mesh │ │ • Draw Mesh │ └─────────────────┘ └─────────────────┘ └─────────────────┘ ↓ ↓ ↓ ┌─────────────────────────────────────────────────────────────┐ │ 命令队列 (Command Queue) │ │ ┌─────┐ ┌─────┐ ┌─────┐ ┌─────┐ ┌─────┐ ┌─────┐ │ │ │ A │→│ B │→│ C │→│ D │→│ E │→│ F │→ ... │ │ └─────┘ └─────┘ └─────┘ └─────┘ └─────┘ └─────┘ │ └─────────────────────────────────────────────────────────────┘ ↓ GPU 端: ┌─────────────────────────────────────────────────────────────┐ │ GPU 执行引擎 │ │ 从队列取出命令 → 解码 → 执行 → 更新状态 │ └─────────────────────────────────────────────────────────────┘ 命令列表 vs 命令队列的设计原因:
- 关注点分离:命令列表关注"录制什么",命令队列关注"何时执行"
- 并行化:多个线程可以同时录制不同的命令列表
- 重用性:静态场景的命令列表可以录制一次,重复提交
- 批处理:减少 CPU 到 GPU 的提交开销
- 内存管理:命令分配器提供高效的内存重用
协作机制:
- CPU 多线程录制 → 批量提交到命令队列 → GPU 顺序执行
- 通过围栏实现 CPU-GPU 同步
- 环形缓冲区模式实现多帧流水线
- 这种设计让开发者能够精细控制 GPU 工作负载,充分发挥现代硬件的并行处理能力.
ID3D12Fence
简单来说 围栏的运行机制是:
CPU向GPU的命令列表中提交更改围栏值的命令X,当GPU执行到这个X命令时,X命令被执行,而X命令执行的内容就是更改围栏值.
其工作原理是,首先使用命令填充命令列表,执行命令队列,向命令列表发出信号,将围栏值设置为指定值,然后检查围栏值是否是我们告诉命令列表将其设置为的值。
如果是,我们知道命令列表已完成其命令列表,可以重置命令列表和队列,并重新填充命令列表。
如果围栏值仍然不是我们发出的信号,我们就会创建一个围栏事件并等待 GPU 发出该事件的信号。
围栏由 ID3D12Fence 接口表示,而围栏事件是句柄 HANDLE。 Device使用 ID3D12Device::CreateFence()方法创建围栏,使用 CreateEvent()方法创建围栏事件。
流程:
- CPU提交Signal命令到GPU命令队列
- GPU按顺序执行命令队列中的命令
- 当GPU执行到Signal命令时,实际设置围栏值
- CPU通过等待机制来同步GPU的执行进度
CPU 时间轴: GPU 时间轴: [录制命令列表A] [空闲] [录制命令列表B] [执行命令列表A] ← 开始执行 [提交A+B到队列] [执行命令列表B] ← 继续执行 [录制命令列表C] [执行完成,设置围栏] [等待GPU完成] ←───── 同步点 ────→ [设置围栏值] [继续工作] [空闲] 创建围栏:
ThrowIfFailed(md3dDevice->CreateFence(0, D3D12_FENCE_FLAG_NONE, IID_PPV_ARGS(&mFence))); ID3D12Fence 是 Direct3D 12 中用于 CPU-GPU 同步 的核心对象。它通过一个单调递增的 64 位整数值来跟踪 GPU 的执行进度。
为什么需要围栏:
- Direct3D 12 中,CPU 和 GPU 是异步执行的
- CPU 提交命令后立即返回,GPU 在后台执行
- 需要机制来知道 GPU 何时完成工作
围栏的工作原理:
围栏值:
UINT64 mCurrentFence = 0; // 单调递增的围栏值
- 每个围栏值代表 GPU 执行流水线中的一个检查点
- CPU 和 GPU 都可以读取和设置围栏值
- 通过比较围栏值来判断 GPU 执行进度
信号机制:
// CPU 告诉 GPU:"当你执行到这里时,设置围栏值为 X" mCommandQueue->Signal(mFence.Get(), mCurrentFence); CPU 时间轴: [提交命令] ---- [等待完成] ---- [继续工作] ↓ ↓ GPU 时间轴: [执行命令] --------- [完成,设置围栏值] 等待机制:
// CPU 等待 GPU:"等到围栏值达到 X 时再继续" if(mFence->GetCompletedValue() < mCurrentFence) { // 设置事件,当围栏值达到指定值时触发 mFence->SetEventOnCompletion(mCurrentFence, eventHandle); WaitForSingleObject(eventHandle, INFINITE); } 描述符系统
描述符是一种结构,它告诉着色器在何处查找资源,以及如何解释资源中的数据。
可以为同一资源创建多个描述符,因为管道的不同阶段可能以不同的方式使用它。
例如,创建一个 Texture2D 资源。
创建一个渲染目标视图 (RTV),以便可以将该资源用作管道的输出缓冲区(将资源绑定到输出合并(OM) 阶段作为 RTV)。
可以为同一资源创建一个无序访问视图(UAV),可以将其用作着色器资源并使用几何体进行纹理处理,
例如,如果场景中的某个地方有摄像机,将摄像机看到的场景渲染到资源(RTV)上,然后将该资源(UAV)渲染到屏幕上)。
描述符:
- 可以理解为 GPU 资源的"视图"或"指针"
- GPU 不能直接访问资源,需要通过描述符
各种描述符:
- RTV (Render Target View):渲染目标视图
- DSV (Depth Stencil View):深度模板视图
- CBV/SRV/UAV (Constant/Shader/Unordered Access View):着色器资源视图
描述符只能放置在描述符堆中。没有其他方法可以在内存中存储描述符(除了某些根描述符,它们只能是 CBV,以及原始或结构 UAV 或 SRV 缓冲区。像 Texture2D SRV 这样的复杂类型不能用作根描述符)。
描述符堆
mRtvDescriptorSize = md3dDevice->GetDescriptorHandleIncrementSize(D3D12_DESCRIPTOR_HEAP_TYPE_RTV); 描述符堆可以看作一个数组: [ RTV0 ][ RTV1 ][ RTV2 ]... 每个描述符的大小可能不同,需要知道偏移量 mRtvDescriptorSize = 每个RTV描述符的字节数 描述符表
描述符表是描述符堆中的描述符数组。描述符表的所有内容都是描述符堆的偏移量和长度。
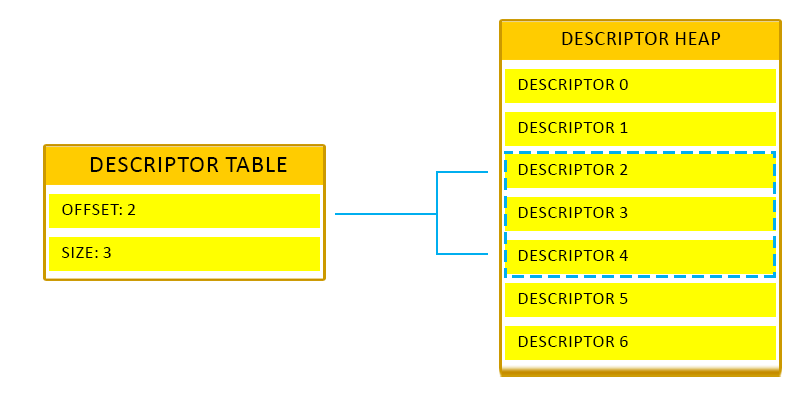
根签名
GPU 就像一家高级餐厅
- 着色器程序 = 厨房里的厨师团队
- 顶点着色器厨师:处理食材准备
- 像素着色器厨师:负责最终装盘
- 计算着色器厨师:做复杂的计算料理
//---// - 资源 = 厨房里的各种食材和工具
- 常量缓冲区 = 标准配方卡片
- 纹理 = 各种酱料和装饰
- 采样器 = 测量工具和计时器
- UAV = 临时工作台
根签名就是"餐厅菜单系统"
没有菜单系统的混乱厨房
// 问题场景:厨师们不知道有什么食材可用 厨师A: "我需要黄油!" // 但不知道黄油在哪里 厨师B: "盐用完了!" // 不知道盐的库存 厨师C: "这个配方需要什么调料?" // 没有标准操作流程 // 结果:厨房混乱,上菜慢,容易出错 有菜单系统的有序厨房
// 根签名定义了标准的"菜单系统": D3D12_ROOT_SIGNATURE_DESC menuSystem = { // 菜单项目1:常量缓冲区(标准配方) { D3D12_ROOT_PARAMETER_TYPE_CBV, // 类型:常量缓冲区 0, // 寄存器位置:0号位置 0, // 着色器可见性:所有厨师 D3D12_ROOT_DESCRIPTOR_FLAG_NONE }, // 菜单项目2:纹理(酱料) { D3D12_ROOT_PARAMETER_TYPE_SRV, // 类型:着色器资源视图 0, // 寄存器位置:t0 0, // 着色器可见性:所有厨师 D3D12_ROOT_DESCRIPTOR_FLAG_NONE } // ... 更多菜单项目 }; 根签名的三个核心组件
1.根常量 - 快速调料台
就像厨师手边的小调料盒,放最常用的盐、胡椒、糖,随手就能拿到。
// 就像餐厅里的快速调料台 // 特点:小量、快速访问、直接使用 CD3DX12_ROOT_PARAMETER rootConstants; rootConstants.InitAsConstants(4, 0); // 4个32位常量,放在0号位置 // 使用场景: // - 变换矩阵的一部分 // - 颜色调节参数 // - 时间参数 2.根描述符 - 固定食材架
就像墙上固定的食材架,放常用的面粉、大米、食用油,位置固定,容易找到。
// 就像厨房里的固定食材架 // 特点:中等数量、直接指向资源 CD3DX12_ROOT_PARAMETER cbvParam; cbvParam.InitAsConstantBufferView(0); // 常量缓冲区视图 CD3DX12_ROOT_PARAMETER srvParam; srvParam.InitAsShaderResourceView(0); // 着色器资源视图 // 使用场景: // - 模型的世界矩阵 // - 主纹理 // - 关键参数缓冲区 3.描述符表 - 食材仓库目录
就像食材仓库的目录卡,告诉各种食材在仓库的具体位置,需要时按目录去取。
// 就像食材仓库的目录系统 // 特点:大量资源、灵活管理、间接访问 CD3DX12_DESCRIPTOR_RANGE range; range.Init(D3D12_DESCRIPTOR_RANGE_TYPE_SRV, 10, 0); // 10个纹理 CD3DX12_ROOT_PARAMETER tableParam; tableParam.InitAsDescriptorTable(1, &range); // 描述符表 // 使用场景: // - 材质纹理数组 // - 骨骼动画矩阵数组 // - 大量光照数据 作用:
- 提高"上菜速度"
// 没有根签名:每次都要重新解释资源布局 // 就像每次点餐都要重新解释菜单,效率低下 // 有根签名:固定的资源访问模式 // 就像标准菜单,厨师熟悉流程,上菜快 2.避免"点错菜"
// 根签名确保: // - 资源类型正确(不会把纹理当矩阵用) // - 寄存器位置正确(不会用错食材) // - 访问权限正确(每个厨师只能访问授权食材) 3.支持"多种菜系"
// 不同的根签名对应不同的菜系 ComPtr<ID3D12RootSignature> mOpaqueRootSignature; // 不透明物体菜系 ComPtr<ID3D12RootSignature> mTransparentRootSignature; // 透明物体菜系 ComPtr<ID3D12RootSignature> mPostProcessRootSignature; // 后期处理菜系 // 切换菜系就像换菜单 mCommandList->SetGraphicsRootSignature(mOpaqueRootSignature.Get()); // 渲染不透明物体... mCommandList->SetGraphicsRootSignature(mTransparentRootSignature.Get()); // 渲染透明物体... "菜单"设计原则
// 好的菜单设计:快速调料台放最前面 CD3DX12_ROOT_PARAMETER optimizedMenu[3]; optimizedMenu[0].InitAsConstants(4, 0); // 根常量:最快访问 optimizedMenu[1].InitAsConstantBufferView(0); // 根描述符:中等速度 optimizedMenu[2].InitAsDescriptorTable(1, &range); // 描述符表:较慢但灵活 // 不好的菜单设计:把慢的放前面会影响整体性能 避免"菜单过大"
// 根签名有大小限制(通常64 DWORD) // 就像餐厅菜单不能无限大,要考虑顾客的阅读能力 // 优化策略: // - 合并相关参数 // - 使用描述符表管理大量资源 // - 避免不必要的根参数 完整的"餐厅菜单"创建过程
void CreateRestaurantMenu() { // 1. 定义菜单项目(根参数) CD3DX12_ROOT_PARAMETER menuItems[3]; // 快速调料台:4个常量 menuItems[0].InitAsConstants(4, 0); // 固定食材架:世界矩阵 menuItems[1].InitAsConstantBufferView(0); // 食材仓库目录:10个纹理 CD3DX12_DESCRIPTOR_RANGE textureRange; textureRange.Init(D3D12_DESCRIPTOR_RANGE_TYPE_SRV, 10, 0); menuItems[2].InitAsDescriptorTable(1, &textureRange); // 2. 创建菜单系统(根签名) CD3DX12_ROOT_SIGNATURE_DESC menuDesc; menuDesc.Init(3, menuItems, 0, nullptr, D3D12_ROOT_SIGNATURE_FLAG_ALLOW_INPUT_ASSEMBLER_INPUT_LAYOUT); // 3. 制作菜单(序列化和创建) ComPtr<ID3DBlob> signature; ComPtr<ID3DBlob> error; D3D12SerializeRootSignature(&menuDesc, D3D_ROOT_SIGNATURE_VERSION_1, &signature, &error); md3dDevice->CreateRootSignature(0, signature->GetBufferPointer(), signature->GetBufferSize(), IID_PPV_ARGS(&mRootSignature)); } 在实际"烹饪"中的使用
设置厨房工作环境
void SetupKitchenForCooking() { // 告诉所有厨师使用这个菜单系统 mCommandList->SetGraphicsRootSignature(mRootSignature.Get()); // 配置快速调料台 mCommandList->SetGraphicsRoot32BitConstants(0, 4, &colorConstants, 0); // 放置固定食材架 mCommandList->SetGraphicsRootConstantBufferView(1, worldMatrixBuffer->GetGPUVirtualAddress()); // 连接食材仓库目录 mCommandList->SetGraphicsRootDescriptorTable(2, textureDescriptorHeap->GetGPUDescriptorHandleForHeapStart()); } 厨师干活👨🍳
// 着色器厨师按照菜单系统工作 cbuffer WorldConstants : register(b0) // 固定食材架:世界矩阵 { float4x4 gWorld; }; Texture2D gTextures[10] : register(t0); // 食材仓库:10个纹理 SamplerState gSampler : register(s0); float4 main(VertexOut pin) : SV_TARGET { // 使用快速调料台的常量 float4 baseColor = float4(gColorConstants); // 从根常量读取 // 使用固定食材架的矩阵 float3 worldPos = mul(float4(pin.PosL, 1.0f), gWorld).xyz; // 使用食材仓库的纹理 float4 texColor = gTextures[0].Sample(gSampler, pin.Tex); return baseColor * texColor; } register()
在高级餐厅的厨房里,每个储物柜都有唯一的编号,这样厨师们就能快速找到需要的食材和工具:
- b 系列储物柜 = 常量缓冲区柜子(Buffer Cabinets)
- t 系列储物柜 = 纹理食材柜子(Texture Cabinets)
- s 系列储物柜 = 采样器工具柜子(Sampler Cabinets)
- u 系列储物柜 = UAV工作台柜子(Unordered Access Cabinets)
| 寄存器类型 | HLSL语法 | 用途 | 特点 |
|---|---|---|---|
| b寄存器 | register(b0) | 常量缓冲区 | 只读,快速访问,适合矩阵和参数 |
| t寄存器 | register(t0) | 纹理资源 | 只读,支持滤波,适合贴图和缓冲区 |
| s寄存器 | register(s0) | 采样器状态 | 配置纹理采样方式 |
| u寄存器 | register(u0) | UAV资源 | 可读写,适合计算着色器输出 |
// 资源类型 变量名 : register(类型序号); Texture2D myTexture : register(t0); // 纹理放在 t0 柜子 SamplerState mySampler : register(s0); // 采样器放在 s0 柜子 cbuffer MyConstants : register(b0) // 常量缓冲区放在 b0 柜子 { float4 data; }; b 寄存器 - 常量缓冲区柜子 (b = Buffer)
- 只读数据,渲染过程中不变
- 适合存放变换矩阵、材质参数、光照信息
- 访问速度快,有专用缓存
// 就像存放标准配方的文件柜 cbuffer WorldConstants : register(b0) // b0 柜子:世界变换矩阵 { float4x4 gWorld; // 世界矩阵 float4x4 gView; // 视图矩阵 float4x4 gProj; // 投影矩阵 }; cbuffer MaterialConstants : register(b1) // b1 柜子:材质参数 { float4 gDiffuseAlbedo; // 漫反射颜色 float3 gFresnelR0; // 菲涅尔参数 float gRoughness; // 粗糙度 }; t 寄存器 - 纹理资源柜子 (t = Texture)
- 存储图像数据(颜色、法线、高度等)
- 支持各种维度(1D、2D、3D、立方体)
- 可以通过采样器进行滤波访问
// 就像存放各种食材的冷藏柜 Texture2D gDiffuseMap : register(t0); // t0 柜子:漫反射贴图 Texture2D gNormalMap : register(t1); // t1 柜子:法线贴图 Texture2D gRoughnessMap : register(t2); // t2 柜子:粗糙度贴图 TextureCube gSkyCube : register(t3); // t3 柜子:天空盒立方体贴图 // 纹理数组 - 就像多层的食材架 Texture2D gMaterialTextures[50] : register(t4); // t4-t53:材质纹理数组 s 寄存器 - 采样器工具柜子 (s = Sampler)
// 就像存放测量和加工工具的工具箱 SamplerState gSamPointWrap : register(s0); // s0 工具箱:点过滤+包裹寻址 SamplerState gSamPointClamp : register(s1); // s1 工具箱:点过滤+钳制寻址 SamplerState gSamLinearWrap : register(s2); // s2 工具箱:线性过滤+包裹寻址 SamplerState gSamAnisotropicWrap : register(s3); // s3 工具箱:各向异性过滤+包裹寻址 // 使用不同的采样器处理同一纹理 float4 color1 = gDiffuseMap.Sample(gSamPointWrap, uv); // 像素风 float4 color2 = gDiffuseMap.Sample(gSamLinearWrap, uv); // 平滑 float4 color3 = gDiffuseMap.Sample(gSamAnisotropicWrap, uv); // 高质量 u 寄存器 - UAV工作台柜子 (u = Unordered Access View)
- 可读写资源(计算着色器中常用)
- 无序访问(没有固定的访问顺序)
- 适合粒子系统、后期处理、通用计算
// 就像可读写的临时工作台 RWTexture2D<float4> gOutputTexture : register(u0); // u0 工作台:输出纹理 RWStructuredBuffer<float> gComputeBuffer : register(u1); // u1 工作台:计算缓冲区 内存布局
register(s0)、register(t0)....这些s0 t0并不是真正的内存地址,而是 GPU 着色器中的虚拟寄存器编号。
描述符 = 资源的"名片"
描述符就像图书馆的目录卡片,卡片本身不是书,但告诉你书在哪里、什么类型、如何阅读。
// 描述符不是资源本身,而是资源的"描述卡片" struct D3D12_SHADER_RESOURCE_VIEW_DESC { DXGI_FORMAT Format; // 资源格式 D3D12_SRV_DIMENSION ViewDimension; // 资源维度(1D/2D/3D等) UINT Shader4ComponentMapping; // 分量映射 // ... 其他描述信息 }; 阶段1:创建物理资源
// 1. 创建真实的纹理资源(在GPU内存中) ComPtr<ID3D12Resource> textureResource; D3D12_RESOURCE_DESC texDesc = CD3DX12_RESOURCE_DESC::Tex2D( DXGI_FORMAT_R8G8B8A8_UNORM, 1024, 1024, 1, 1 ); md3dDevice->CreateCommittedResource( &CD3DX12_HEAP_PROPERTIES(D3D12_HEAP_TYPE_DEFAULT), D3D12_HEAP_FLAG_NONE, &texDesc, D3D12_RESOURCE_STATE_COPY_DEST, // 初始状态 nullptr, IID_PPV_ARGS(&textureResource) ); 阶段2:创建描述符("名片")
// 2. 创建着色器资源视图描述符 D3D12_SHADER_RESOURCE_VIEW_DESC srvDesc = {}; srvDesc.Format = DXGI_FORMAT_R8G8B8A8_UNORM; srvDesc.ViewDimension = D3D12_SRV_DIMENSION_TEXTURE2D; srvDesc.Shader4ComponentMapping = D3D12_DEFAULT_SHADER_4_COMPONENT_MAPPING; srvDesc.Texture2D.MipLevels = 1; // 在描述符堆中创建实际的描述符 D3D12_CPU_DESCRIPTOR_HANDLE srvHandle = mCbvSrvUavHeap->GetCPUDescriptorHandleForHeapStart(); srvHandle.ptr += mCbvSrvUavDescriptorSize * 0; // 第一个描述符位置 md3dDevice->CreateShaderResourceView( textureResource.Get(), // 真实的纹理资源 &srvDesc, // 描述信息 srvHandle // 描述符堆中的位置 ); 阶段3:建立寄存器绑定
// 3. 通过根签名将寄存器与描述符堆关联 void BindTextureToRegister() { // 定义描述符表范围:从堆起始位置开始的10个描述符 CD3DX12_DESCRIPTOR_RANGE srvRange; srvRange.Init( D3D12_DESCRIPTOR_RANGE_TYPE_SRV, // 类型:着色器资源视图 10, // 数量:10个描述符 0 // 基础寄存器:t0 ); // 创建根参数 CD3DX12_ROOT_PARAMETER rootParam; rootParam.InitAsDescriptorTable(1, &srvRange); // 一个描述符表 // 创建根签名 CD3DX12_ROOT_SIGNATURE_DESC rootSigDesc; rootSigDesc.Init(1, &rootParam, 0, nullptr, D3D12_ROOT_SIGNATURE_FLAG_ALLOW_INPUT_ASSEMBLER_INPUT_LAYOUT); // ... 序列化和创建根签名 } 阶段4:运行时绑定
// 4. 渲染时设置绑定 void Render() { // 设置描述符堆 ID3D12DescriptorHeap* heaps[] = { mCbvSrvUavHeap.Get() }; mCommandList->SetDescriptorHeaps(_countof(heaps), heaps); // 将描述符表绑定到根参数槽位0 mCommandList->SetGraphicsRootDescriptorTable( 0, // 根参数索引(对应HLSL中的t0起始位置) mCbvSrvUavHeap->GetGPUDescriptorHandleForHeapStart() // 描述符堆起始位置 ); } 描述符堆的内存结构
描述符堆内存布局: ┌─────────────┬─────────────┬─────────────┬─────────────┐ │ 描述符槽0 │ 描述符槽1 │ 描述符槽2 │ 描述符槽3 │ │ (t0) │ (t1) │ (t2) │ (t3) │ ├─────────────┼─────────────┼─────────────┼─────────────┤ │ 纹理A的SRV │ 纹理B的SRV │ 纹理C的SRV │ 纹理D的SRV │ │ → 指向纹理A │ → 指向纹理B │ → 指向纹理C │ → 指向纹理D │ └─────────────┴─────────────┴─────────────┴─────────────┘ ↑ ↑ ↑ ↑ GPU通过描述符 GPU通过描述符 GPU通过描述符 GPU通过描述符 找到纹理A 找到纹理B 找到纹理C 找到纹理D 寄存器绑定的映射关系
// HLSL 中的声明 Texture2D gTextures[10] : register(t0); // 实际的内存映射: // t0 → 描述符堆槽位0 → 纹理资源A // t1 → 描述符堆槽位1 → 纹理资源B // t2 → 描述符堆槽位2 → 纹理资源C // ... // t9 → 描述符堆槽位9 → 纹理资源J 描述符
// 着色器资源视图描述符的典型内容 struct SRV_Descriptor { D3D12_GPU_VIRTUAL_ADDRESS ResourceLocation; // 资源在GPU内存中的地址 UINT SizeInBytes; // 资源大小 DXGI_FORMAT Format; // 数据格式 D3D12_SRV_DIMENSION Dimension; // 资源维度 UINT FirstArraySlice; // 第一个数组切片 UINT ArraySize; // 数组大小 UINT MostDetailedMip; // 最详细的mip级别 UINT MipLevels; // mip级别数量 // ... 其他元数据 }; HLSL代码 → 虚拟寄存器 → 根签名映射 → 描述符堆 → 真实GPU资源 着色器寄存器 (t0-t9) ↓ 通过根签名映射 描述符堆槽位 (0-9) ↓ 通过描述符指向 GPU内存中的真实纹理资源 应用层: HLSL代码 + 寄存器声明 ↓ 框架层: 根签名 + 描述符堆配置 ↓ 驱动层: 描述符创建 + 资源绑定 ↓ 硬件层: GPU寄存器 + 内存访问 MSAA 质量检查
- 多重采样抗锯齿 (MultiSample Anti-Aliasing)
- 通过在像素边缘进行多次采样来平滑锯齿
- SampleCount = 4 表示每个像素采样4次
质量级别的重要性:
- 不同硬件支持不同的 MSAA 质量
- 质量级别影响抗锯齿效果和性能
- 必须查询设备支持的质量级别数量
//描述给定格式和样本计数的多采样图像质量级别 D3D12_FEATURE_DATA_MULTISAMPLE_QUALITY_LEVELS msQualityLevels; // 设置要查询的纹理格式为 mBackBufferFormat , (后台缓冲区的像素格式) msQualityLevels.Format = mBackBufferFormat; msQualityLevels.SampleCount = 4; msQualityLevels.Flags = D3D12_MULTISAMPLE_QUALITY_LEVELS_FLAG_NONE; msQualityLevels.NumQualityLevels = 0; ThrowIfFailed(md3dDevice->CheckFeatureSupport( D3D12_FEATURE_MULTISAMPLE_QUALITY_LEVELS, //描述要查询支持的功能 &msQualityLevels, //指向对应于 Feature 参数值的数据结构的指针 sizeof(msQualityLevels))); //参数指向的结构的大小 IDXGIAdapter
IDXGIAdapter 是 DirectX Graphics Infrastructure (DXGI) 中的核心接口,用于表示系统中的图形适配器(显卡)。
图形适配器:
- 物理显卡(独立显卡、集成显卡)
- 软件渲染器(如 WARP)
- 虚拟图形设备
#include <dxgi.h> using Microsoft::WRL::ComPtr; // 典型的适配器类型: // - NVIDIA GeForce RTX 3080 // - AMD Radeon RX 6800 XT // - Intel UHD Graphics // - Microsoft Basic Render Driver (WARP) IDXGIAdapter 接口层次:
IUnknown ↓ IDXGIObject ↓ IDXGIAdapter (DXGI 1.0) ↓ IDXGIAdapter1 (DXGI 1.1) ↓ IDXGIAdapter2 (DXGI 1.2) ↓ IDXGIAdapter3 (DXGI 1.3) ↓ IDXGIAdapter4 (DXGI 1.4) 核心方法
获取适配器信息
class AdapterInfoExample { public: void GetAdapterInfo() { ComPtr<IDXGIFactory> factory; ComPtr<IDXGIAdapter> adapter; CreateDXGIFactory(IID_PPV_ARGS(&factory)); // 枚举第一个适配器 if (SUCCEEDED(factory->EnumAdapters(0, &adapter))) { DXGI_ADAPTER_DESC desc; adapter->GetDesc(&desc); // 输出适配器信息 wprintf(L"Adapter: %sn", desc.Description); wprintf(L"VendorId: 0x%04Xn", desc.VendorId); wprintf(L"DeviceId: 0x%04Xn", desc.DeviceId); wprintf(L"Video Memory: %llu MBn", desc.DedicatedVideoMemory / (1024 * 1024)); wprintf(L"System Memory: %llu MBn", desc.DedicatedSystemMemory / (1024 * 1024)); wprintf(L"Shared Memory: %llu MBn", desc.SharedSystemMemory / (1024 * 1024)); } } }; 枚举输出(显示器)
void EnumerateOutputs(IDXGIAdapter* adapter) { ComPtr<IDXGIOutput> output; for (UINT i = 0; adapter->EnumOutputs(i, &output) != DXGI_ERROR_NOT_FOUND; ++i) { DXGI_OUTPUT_DESC outputDesc; output->GetDesc(&outputDesc); wprintf(L"Output %d: %sn", i, outputDesc.DeviceName); wprintf(L"Desktop Coordinates: (%d, %d) to (%d, %d)n", outputDesc.DesktopCoordinates.left, outputDesc.DesktopCoordinates.top, outputDesc.DesktopCoordinates.right, outputDesc.DesktopCoordinates.bottom); // 枚举显示模式 EnumerateDisplayModes(output.Get()); } } 检查设备支持
void CheckDeviceSupport(IDXGIAdapter* adapter) { // 检查 Direct3D 12 支持 if (SUCCEEDED(D3D12CreateDevice(adapter, D3D_FEATURE_LEVEL_11_0, _uuidof(ID3D12Device), nullptr))) { printf("Adapter supports D3D12 Feature Level 11.0n"); } // 检查格式支持 DXGI_FORMAT format = DXGI_FORMAT_R8G8B8A8_UNORM; UINT support; adapter->CheckInterfaceSupport(__uuidof(ID3D12Device), nullptr); // 已弃用,但历史用法 } 创建命令对象
D3DApp::CreateCommandObjects()
void D3DApp::CreateCommandObjects() { D3D12_COMMAND_QUEUE_DESC queueDesc = {}; queueDesc.Type = D3D12_COMMAND_LIST_TYPE_DIRECT; queueDesc.Flags = D3D12_COMMAND_QUEUE_FLAG_NONE; ThrowIfFailed(md3dDevice->CreateCommandQueue(&queueDesc, IID_PPV_ARGS(&mCommandQueue))); ThrowIfFailed(md3dDevice->CreateCommandAllocator( D3D12_COMMAND_LIST_TYPE_DIRECT, IID_PPV_ARGS(mDirectCmdListAlloc.GetAddressOf()))); ThrowIfFailed(md3dDevice->CreateCommandList( 0, D3D12_COMMAND_LIST_TYPE_DIRECT, mDirectCmdListAlloc.Get(), // Associated command allocator nullptr, // Initial PipelineStateObject IID_PPV_ARGS(mCommandList.GetAddressOf()))); // Start off in a closed state. This is because the first time we refer // to the command list we will Reset it, and it needs to be closed before // calling Reset. mCommandList->Close(); } 创建命令队列 (Command Queue)
D3D12_COMMAND_QUEUE_DESC 描述命令队列的结构体
详情:D3D12_COMMAND_QUEUE_DESC
typedef struct D3D12_COMMAND_QUEUE_DESC { D3D12_COMMAND_LIST_TYPE Type; INT Priority; D3D12_COMMAND_QUEUE_FLAGS Flags; UINT NodeMask; } D3D12_COMMAND_QUEUE_DESC; D3D12_COMMAND_QUEUE_DESC queueDesc = {}; queueDesc.Type = D3D12_COMMAND_LIST_TYPE_DIRECT; queueDesc.Flags = D3D12_COMMAND_QUEUE_FLAG_NONE; ThrowIfFailed(md3dDevice->CreateCommandQueue(&queueDesc, IID_PPV_ARGS(&mCommandQueue))); 命令队列的作用:
- GPU 命令的执行管道:所有提交的命令列表都在这里排队等待 GPU 执行
- 执行顺序管理:保证命令按提交顺序执行
- 硬件接口:直接与 GPU 命令处理器通信
参数解析:
- Type = D3D12_COMMAND_LIST_TYPE_DIRECT:直接命令队列,支持所有图形操作
- Flags = D3D12_COMMAND_QUEUE_FLAG_NONE:无特殊标志
创建命令分配器 (Command Allocator)
ThrowIfFailed(md3dDevice->CreateCommandAllocator( D3D12_COMMAND_LIST_TYPE_DIRECT, IID_PPV_ARGS(mDirectCmdListAlloc.GetAddressOf()))); 命令分配器的作用:
- 内存管理器:为命令列表提供存储命令的内存池
- 内存重用:通过重置来重用内存,避免频繁分配
- 生命周期管理:管理命令内存的分配和释放
创建命令列表 (Command List)
ThrowIfFailed(md3dDevice->CreateCommandList( 0, // node mask (单GPU为0) D3D12_COMMAND_LIST_TYPE_DIRECT, mDirectCmdListAlloc.Get(), // 关联的命令分配器 nullptr, // 初始管线状态对象 IID_PPV_ARGS(mCommandList.GetAddressOf()))); 命令列表的作用:
- 命令录制器:录制具体的 GPU 命令序列
- 批量提交:将多个命令打包成一次提交
- 多线程支持:可以在不同线程同时录制多个命令列表
关闭命令列表
mCommandList->Close();
为什么需要关闭:
- 命令列表有打开和关闭两种状态
- 只有关闭的命令列表才能提交执行
- 重置命令列表前必须处于关闭状态
架构关系图:
命令分配器 (Command Allocator) ↓ 提供内存 命令列表 (Command List) → 录制命令 ↓ 提交执行 命令队列 (Command Queue) → GPU 执行 内存管理机制
命令分配器的内存布局
命令分配器内存块: ┌─────────────────────────────────────────┐ │ 命令1 │ 命令2 │ 命令3 │ ... │ 命令N │ 空闲 │ └─────────────────────────────────────────┘ 重置时: ┌─────────────────────────────────────────┐ │ 全部标记为可用,可以重新录制命令 │ └─────────────────────────────────────────┘ // 没有命令分配器的情况(效率低下): void InefficientRendering() { for (each frame) { // 每次都需要分配新内存 AllocateNewCommandMemory(); RecordCommands(); SubmitCommands(); FreeCommandMemory(); // 频繁分配释放 } } // 使用命令分配器(高效): void EfficientRendering() { for (each frame) { // 重用已有内存 mCommandAllocator->Reset(); // 标记内存可重用 RecordCommands(); SubmitCommands(); // 不释放内存,下次重置后重用 } } 不同类型的命令队列
void CreateDifferentCommandQueues() { // 1. 直接命令队列(图形+计算+复制) D3D12_COMMAND_QUEUE_DESC directQueueDesc = {}; directQueueDesc.Type = D3D12_COMMAND_LIST_TYPE_DIRECT; // 2. 计算命令队列(仅计算命令) D3D12_COMMAND_QUEUE_DESC computeQueueDesc = {}; computeQueueDesc.Type = D3D12_COMMAND_LIST_TYPE_COMPUTE; // 3. 复制命令队列(仅复制命令) D3D12_COMMAND_QUEUE_DESC copyQueueDesc = {}; copyQueueDesc.Type = D3D12_COMMAND_LIST_TYPE_COPY; // 创建不同的命令队列 ComPtr<ID3D12CommandQueue> directQueue, computeQueue, copyQueue; md3dDevice->CreateCommandQueue(&directQueueDesc, IID_PPV_ARGS(&directQueue)); md3dDevice->CreateCommandQueue(&computeQueueDesc, IID_PPV_ARGS(&computeQueue)); md3dDevice->CreateCommandQueue(©QueueDesc, IID_PPV_ARGS(©Queue)); } 创建交换链
void D3DApp::CreateSwapChain() { // Release the previous swapchain we will be recreating. mSwapChain.Reset(); DXGI_SWAP_CHAIN_DESC sd; sd.BufferDesc.Width = mClientWidth; sd.BufferDesc.Height = mClientHeight; sd.BufferDesc.RefreshRate.Numerator = 60; sd.BufferDesc.RefreshRate.Denominator = 1; sd.BufferDesc.Format = mBackBufferFormat; sd.BufferDesc.ScanlineOrdering = DXGI_MODE_SCANLINE_ORDER_UNSPECIFIED; sd.BufferDesc.Scaling = DXGI_MODE_SCALING_UNSPECIFIED; sd.SampleDesc.Count = m4xMsaaState ? 4 : 1; sd.SampleDesc.Quality = m4xMsaaState ? (m4xMsaaQuality - 1) : 0; sd.BufferUsage = DXGI_USAGE_RENDER_TARGET_OUTPUT; sd.BufferCount = SwapChainBufferCount; sd.OutputWindow = mhMainWnd; sd.Windowed = true; sd.SwapEffect = DXGI_SWAP_EFFECT_FLIP_DISCARD; sd.Flags = DXGI_SWAP_CHAIN_FLAG_ALLOW_MODE_SWITCH; // Note: Swap chain uses queue to perform flush. ThrowIfFailed(mdxgiFactory->CreateSwapChain( mCommandQueue.Get(), &sd, mSwapChain.GetAddressOf())); } 交换链的作用:
- 管理前后台缓冲区,实现无撕裂渲染
- 连接 Direct3D 渲染输出与 Windows 窗口系统
- 提供垂直同步和显示刷新率控制
关键配置参数
缓冲区配置
- 尺寸:匹配客户端区域 (mClientWidth × mClientHeight)
- 数量:双缓冲 (SwapChainBufferCount = 2)
- 格式:mBackBufferFormat (通常为 DXGI_FORMAT_R8G8B8A8_UNORM)
显示特性
- 刷新率:60Hz (Numerator=60, Denominator=1)
- 多重采样:根据 m4xMsaaState 启用 4x MSAA
- 窗口模式:窗口化 (Windowed = true)
现代交换效果
sd.SwapEffect = DXGI_SWAP_EFFECT_FLIP_DISCARD;
FLIP模式:高效页面翻转而非内存拷贝
DISCARD:丢弃后台缓冲区内容,提升性能
双缓冲渲染流程
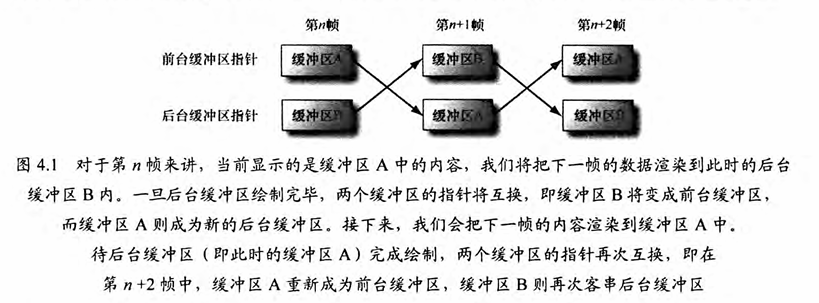
与命令队列的关联
mdxgiFactory->CreateSwapChain(mCommandQueue.Get(), &sd, ...);
- 交换链需要命令队列来同步 GPU 工作
- Present 操作通过命令队列提交到 GPU
创建描述符堆
void D3DApp::CreateRtvAndDsvDescriptorHeaps() { D3D12_DESCRIPTOR_HEAP_DESC rtvHeapDesc; rtvHeapDesc.NumDescriptors = SwapChainBufferCount; rtvHeapDesc.Type = D3D12_DESCRIPTOR_HEAP_TYPE_RTV; rtvHeapDesc.Flags = D3D12_DESCRIPTOR_HEAP_FLAG_NONE; rtvHeapDesc.NodeMask = 0; ThrowIfFailed(md3dDevice->CreateDescriptorHeap( &rtvHeapDesc, IID_PPV_ARGS(mRtvHeap.GetAddressOf()))); D3D12_DESCRIPTOR_HEAP_DESC dsvHeapDesc; dsvHeapDesc.NumDescriptors = 1; dsvHeapDesc.Type = D3D12_DESCRIPTOR_HEAP_TYPE_DSV; dsvHeapDesc.Flags = D3D12_DESCRIPTOR_HEAP_FLAG_NONE; dsvHeapDesc.NodeMask = 0; ThrowIfFailed(md3dDevice->CreateDescriptorHeap( &dsvHeapDesc, IID_PPV_ARGS(mDsvHeap.GetAddressOf()))); } 描述符堆的作用:
- 集中管理 GPU 资源视图的描述符
- 提供高效的描述符分配和索引机制
- 作为渲染管线和资源之间的桥梁
渲染目标视图堆 (RTV Heap)
- 容量:SwapChainBufferCount 个描述符(通常为2,双缓冲)
- 类型:D3D12_DESCRIPTOR_HEAP_TYPE_RTV
- 用途:存储交换链后台缓冲区的渲染目标视图
深度模板视图堆 (DSV Heap)
- 容量:1个描述符
- 类型:D3D12_DESCRIPTOR_HEAP_TYPE_DSV
- 用途:存储深度/模板缓冲区的视图
配置参数说明
D3D12_DESCRIPTOR_HEAP_DESC desc; desc.NumDescriptors = count; // 堆容量 desc.Type = heapType; // 堆类型 desc.Flags = D3D12_DESCRIPTOR_HEAP_FLAG_NONE; // 非着色器可见 desc.NodeMask = 0; // 单GPU适配器 描述符系统架构
描述符堆 (Descriptor Heap) ├── 描述符槽 0 → 渲染目标视图 0 ├── 描述符槽 1 → 渲染目标视图 1 └── 描述符槽 2 → 深度模板视图 与渲染流程的配合
- RTV堆:绑定到输出合并阶段,指定渲染目标
- DSV堆:用于深度测试和模板测试
- 描述符在渲染时通过句柄引用
设计意义
- 性能优化:预分配描述符,避免运行时开销
- 资源管理:集中管理视图生命周期
- 管线状态:为后续渲染操作建立必要的视图基础设施
OnResize()
FlushCommandQueue CPU-GPU 同步机制
实现 CPU 与 GPU 的完全同步,确保所有已提交的 GPU 命令执行完成。
CPU 时间轴: [工作] → [Signal(101)] → [等待] ---------------→ [继续工作] GPU 时间轴: [命令...] → [执行Signal(101)] → [设置围栏值=101] → [更多命令] ↑ ↑ ↑ GPU开始 GPU设置围栏值 CPU被唤醒 Signal命令 void D3DApp::FlushCommandQueue() { // 1. 递增围栏值 - 创建新的同步点 mCurrentFence++; // 例如:从 100 → 101 // 2. 向命令队列插入信号命令 mCommandQueue->Signal(mFence.Get(), mCurrentFence); // 这会在GPU命令队列中插入一个特殊命令: // "当GPU执行到这里时,请设置围栏值为101" // 3. 检查当前GPU进度 if(mFence->GetCompletedValue() < mCurrentFence) { // 4. 创建同步事件 HANDLE eventHandle = CreateEventEx(nullptr, false, false, EVENT_ALL_ACCESS); // 5. 注册事件回调 mFence->SetEventOnCompletion(mCurrentFence, eventHandle); // 告诉GPU驱动:"当围栏值达到101时,请触发这个事件" // 6. CPU线程等待 WaitForSingleObject(eventHandle, INFINITE); // CPU线程在此挂起,直到GPU执行到Signal命令并设置围栏值为101 // 7. 清理事件对象 CloseHandle(eventHandle); } } OnResize - 窗口大小变更处理
void D3DApp::OnResize() { // 阶段1: 安全准备 // 阶段2: 资源释放 // 阶段3: 交换链调整 // 阶段4: 渲染目标重建 // 阶段5: 深度缓冲区重建 // 阶段6: 状态转换执行 // 阶段7: 管线状态更新 } 阶段1: 安全准备
// 验证核心组件状态 assert(md3dDevice); // D3D12设备必须有效 assert(mSwapChain); // 交换链必须存在 assert(mDirectCmdListAlloc); // 命令分配器必须就绪 // 刷新命令队列 - 关键同步点! FlushCommandQueue(); // 目的:确保GPU不再使用即将释放的资源 // 防止GPU访问已释放资源导致的崩溃或图形错误 阶段2: 资源释放
// 重置命令列表,开始录制新命令 mCommandList->Reset(mDirectCmdListAlloc.Get(), nullptr); // 释放交换链缓冲区资源 for (int i = 0; i < SwapChainBufferCount; ++i) mSwapChainBuffer[i].Reset(); // 释放COM对象,减少引用计数 // 释放深度模板缓冲区 mDepthStencilBuffer.Reset(); 阶段3: 交换链调整
// 调整交换链缓冲区尺寸和格式 mSwapChain->ResizeBuffers( SwapChainBufferCount, // 保持双缓冲 mClientWidth, // 新的窗口宽度 mClientHeight, // 新的窗口高度 mBackBufferFormat, // 像素格式不变 DXGI_SWAP_CHAIN_FLAG_ALLOW_MODE_SWITCH ); mCurrBackBuffer = 0; // 重置当前后缓冲区索引 阶段4: 渲染目标重建
// 获取RTV描述符堆的起始句柄 CD3DX12_CPU_DESCRIPTOR_HANDLE rtvHeapHandle( mRtvHeap->GetCPUDescriptorHandleForHeapStart() ); for (UINT i = 0; i < SwapChainBufferCount; i++) { // 获取交换链缓冲区资源 ThrowIfFailed(mSwapChain->GetBuffer(i, IID_PPV_ARGS(&mSwapChainBuffer[i]))); // 创建渲染目标视图 md3dDevice->CreateRenderTargetView( mSwapChainBuffer[i].Get(), // 目标资源 nullptr, // 使用资源默认描述 rtvHeapHandle // 描述符堆中的位置 ); // 移动到下一个描述符槽 rtvHeapHandle.Offset(1, mRtvDescriptorSize); } 阶段5: 深度缓冲区重建
// 配置深度模板缓冲区描述 D3D12_RESOURCE_DESC depthStencilDesc; depthStencilDesc.Dimension = D3D12_RESOURCE_DIMENSION_TEXTURE2D; // 2D纹理 depthStencilDesc.Alignment = 0; // 自动对齐 depthStencilDesc.Width = mClientWidth; // 匹配窗口宽度 depthStencilDesc.Height = mClientHeight; // 匹配窗口高度 depthStencilDesc.DepthOrArraySize = 1; // 单纹理/无数组 depthStencilDesc.MipLevels = 1; // 无mipmap depthStencilDesc.Format = mDepthStencilFormat; // 深度模板格式 depthStencilDesc.SampleDesc.Count = m4xMsaaState ? 4 : 1; // MSAA采样数 depthStencilDesc.SampleDesc.Quality = m4xMsaaState ? (m4xMsaaQuality - 1) : 0; depthStencilDesc.Layout = D3D12_TEXTURE_LAYOUT_UNKNOWN; // 驱动优化布局 depthStencilDesc.Flags = D3D12_RESOURCE_FLAG_ALLOW_DEPTH_STENCIL; // 深度模板用途 // 配置清除值(优化深度缓冲区初始化) D3D12_CLEAR_VALUE optClear; optClear.Format = mDepthStencilFormat; optClear.DepthStencil.Depth = 1.0f; // 深度值初始化为1.0(远平面) optClear.DepthStencil.Stencil = 0; // 模板值初始化为0 // 创建深度模板资源 ThrowIfFailed(md3dDevice->CreateCommittedResource( &CD3DX12_HEAP_PROPERTIES(D3D12_HEAP_TYPE_DEFAULT), // GPU专用内存 D3D12_HEAP_FLAG_NONE, // 无特殊堆标志 &depthStencilDesc, // 资源描述 D3D12_RESOURCE_STATE_COMMON, // 初始状态:通用 &optClear, // 优化清除值 IID_PPV_ARGS(mDepthStencilBuffer.GetAddressOf()) )); // 创建深度模板视图 md3dDevice->CreateDepthStencilView( mDepthStencilBuffer.Get(), // 深度缓冲区资源 nullptr, // 使用默认视图描述 DepthStencilView() // DSV描述符堆中的位置 ); 阶段6: 状态转换执行
// 资源屏障:深度缓冲区状态转换 mCommandList->ResourceBarrier(1, &CD3DX12_RESOURCE_BARRIER::Transition( mDepthStencilBuffer.Get(), D3D12_RESOURCE_STATE_COMMON, // 从:通用状态 D3D12_RESOURCE_STATE_DEPTH_WRITE // 到:深度写入状态 ) ); // 提交并执行所有调整命令 ThrowIfFailed(mCommandList->Close()); // 结束命令录制 ID3D12CommandList* cmdsLists[] = { mCommandList.Get() }; mCommandQueue->ExecuteCommandLists(_countof(cmdsLists), cmdsLists); // 等待调整操作完成 FlushCommandQueue(); 阶段7: 管线状态更新
// 更新视口 - 匹配新的客户端区域 mScreenViewport.TopLeftX = 0; mScreenViewport.TopLeftY = 0; mScreenViewport.Width = static_cast<float>(mClientWidth); mScreenViewport.Height = static_cast<float>(mClientHeight); mScreenViewport.MinDepth = 0.0f; // 标准化深度范围 mScreenViewport.MaxDepth = 1.0f; // 更新裁剪矩形 - 防止渲染到窗口外 mScissorRect = { 0, 0, mClientWidth, mClientHeight }; 关键机制
双重同步
- 前置同步:确保GPU完成对旧资源的所有操作
- 后置同步:确保新资源完全就绪后再使用
// 第一次刷新:防止GPU访问即将释放的资源 FlushCommandQueue(); // 在资源释放前 // 第二次刷新:确保调整操作完成后再继续 FlushCommandQueue(); // 在资源创建后 资源状态管理
// 深度缓冲区的状态转换链: D3D12_RESOURCE_STATE_COMMON //应用程序应仅为了跨不同图形引擎类型访问资源而转换为此状态。 → D3D12_RESOURCE_STATE_COMMON → (渲染时使用) //与其他状态互斥的状态。启用了深度写入且该资源在可写的深度模板视图时 应该使用这个状态 → D3D12_RESOURCE_STATE_DEPTH_WRITE 资源屏障
资源屏障是 DirectX 12 中用于管理 GPU 资源状态同步的核心机制。它确保了资源在不同使用场景下的正确访问顺序和内存一致性。
资源屏障是 GPU 命令流水线中的同步点,用于:
- 管理资源的状态转换
- 确保正确的内存访问顺序
- 防止资源访问冲突
- 优化缓存行为
// 资源屏障的基本结构 struct D3D12_RESOURCE_BARRIER { D3D12_RESOURCE_BARRIER_TYPE Type; // 屏障类型 D3D12_RESOURCE_BARRIER_FLAGS Flags; // 屏障标志 union { D3D12_RESOURCE_TRANSITION_BARRIER Transition; // 状态转换屏障 D3D12_RESOURCE_UAV_BARRIER UAV; // UAV屏障 D3D12_RESOURCE_ALIASING_BARRIER Aliasing; // 别名屏障 }; }; 资源屏障的底层机制
GPU 流水线同步
GPU 命令流水线: [几何阶段] → [光栅化] → [像素着色] → [输出合并] ↑ ↑ ↑ ↑ 资源屏障确保每个阶段访问资源时的正确状态 缓存一致性管理
// 没有资源屏障的问题: // - 写后读危险:GPU可能读取旧数据 // - 读后写危险:写入可能覆盖正在读取的数据 // - 缓存不一致:不同GPU单元看到不同的资源状态 // 资源屏障的作用: // 1. 刷新相关缓存 // 2. 等待先前操作完成 // 3. 更新资源状态标识 // 4. 确保后续操作看到正确的数据 内存访问优化
// 资源屏障让驱动可以优化: // - 内存布局(压缩、平铺) // - 缓存策略(写回、写通) // - 访问模式(只读、只写、读写) ResourceBarrier 是 ID3D12GraphicsCommandList 接口的核心方法,用于在命令列表中插入资源屏障,管理 GPU 资源的状态转换和同步。
// ID3D12GraphicsCommandList 接口中的方法 virtual void STDMETHODCALLTYPE ResourceBarrier( UINT NumBarriers, // 屏障数量 const D3D12_RESOURCE_BARRIER *pBarriers // 屏障数组指针 ) = 0; NumBarriers - 屏障数量
- 指定要插入的屏障数量
- 可以是单个屏障或多个屏障的批量处理
- 批量处理更高效,减少 API 调用开销
pBarriers - 屏障数组
- 指向 D3D12_RESOURCE_BARRIER 结构体数组的指针
- 每个结构体描述一个具体的屏障操作
幼稚园理解:
// 场景:同时进行多项工作 CPU: "GPU,请先用这把刷子涂墙(渲染目标)" CPU: "GPU,请再用这把刷子当尺子测量(深度测试)" // 问题:GPU 可能会: // 1. 涂墙还没干就开始测量 → 数据污染 // 2. 测量时发现刷子上有涂料 → 错误结果 // 3. 两个工人同时用一把刷子 → 资源冲突 // 正确的协调: CPU: "交通警察请注意!" CPU: "这把刷子要从'涂料工具'状态变成'测量工具'状态" // 交通警察(资源屏障)的工作: // 1. 拦住所有想用这把刷子的人 // 2. 等待当前使用刷子的人完成工作 // 3. 清理刷子(缓存一致性) // 4. 挂上新的标识牌:"现在是测量工具" // 5. 放行后续的测量工作 mCommandList->ResourceBarrier(1, &CD3DX12_RESOURCE_BARRIER::Transition( mDepthStencilBuffer.Get(), D3D12_RESOURCE_STATE_COMMON, // 之前:通用工具 D3D12_RESOURCE_STATE_DEPTH_WRITE // 之后:深度测量工具 ) ); 在示例中的具体作用
//确保深度缓冲区从通用的初始状态正确转换为深度写入状态,为后续的深度测试操作做好准备。 mCommandList->ResourceBarrier(1, &CD3DX12_RESOURCE_BARRIER::Transition( mDepthStencilBuffer.Get(), D3D12_RESOURCE_STATE_COMMON, // 转换前状态. D3D12_RESOURCE_STATE_DEPTH_WRITE // 转换后状态. ) ); - 屏障数量:1 - 只插入一个屏障
- 屏障类型:状态转换屏障 (D3D12_RESOURCE_BARRIER_TYPE_TRANSITION)
- 目标资源:mDepthStencilBuffer - 深度模板缓冲区
- 状态转换:从 COMMON(通用状态)到 DEPTH_WRITE(深度写入状态)
核心作用
状态管理
// 通知GPU资源用途的变化 // 之前:资源处于通用状态,适合拷贝操作 // 之后:资源将用于深度测试和写入操作 同步保证
// 确保: // - 所有先前的操作(如果有)在转换前完成 // - 后续操作看到正确的资源状态 // - 避免资源访问冲突 性能优化
// 让GPU驱动能够: // - 优化内存访问模式 // - 设置正确的缓存策略 // - 预取适当的数据 底层执行机制
GPU 命令处理流程
命令列表录制: [其他命令] → [ResourceBarrier] → [后续渲染命令] ↓ GPU 执行时: [执行屏障前命令] → [状态转换操作] → [执行屏障后命令] 屏障执行的具体步骤
void GPUBarrierExecution() { // 1. 等待所有先前的GPU操作完成 WaitForPreviousOperations(); // 2. 执行状态转换操作 PerformStateTransition(); // 3. 更新内部资源状态跟踪 UpdateResourceStateTracking(); // 4. 允许后续操作继续执行 ResumePipelineExecution(); } 使用举例
单个屏障使用
// 最常见的使用方式 - 单个资源状态转换 mCommandList->ResourceBarrier(1, &CD3DX12_RESOURCE_BARRIER::Transition(resource, stateBefore, stateAfter) ); 批量屏障处理
// 更高效的方式 - 批量处理多个屏障 D3D12_RESOURCE_BARRIER barriers[3] = { CD3DX12_RESOURCE_BARRIER::Transition(rtv, PRESENT, RENDER_TARGET), CD3DX12_RESOURCE_BARRIER::Transition(depth, COMMON, DEPTH_WRITE), CD3DX12_RESOURCE_BARRIER::Transition(texture, COPY_DEST, SHADER_RESOURCE) }; mCommandList->ResourceBarrier(3, barriers); // 一次调用处理所有屏障 不同类型屏障组合
// 混合不同类型的屏障 D3D12_RESOURCE_BARRIER barriers[2] = { CD3DX12_RESOURCE_BARRIER::Transition(texture, stateA, stateB), CD3DX12_RESOURCE_BARRIER::UAV(computeOutput) // UAV屏障 }; mCommandList->ResourceBarrier(2, barriers); 在渲染流水线中的典型位置
帧开始时的屏障
void BeginFrame() { // 后台缓冲区:呈现 → 渲染目标 mCommandList->ResourceBarrier(1, &CD3DX12_RESOURCE_BARRIER::Transition( mBackBuffer.Get(), D3D12_RESOURCE_STATE_PRESENT, D3D12_RESOURCE_STATE_RENDER_TARGET ) ); } 渲染过程中的屏障
void RenderDepthPrePass() { // 深度缓冲区:通用 → 深度写入 mCommandList->ResourceBarrier(1, &CD3DX12_RESOURCE_BARRIER::Transition( mDepthBuffer.Get(), D3D12_RESOURCE_STATE_COMMON, D3D12_RESOURCE_STATE_DEPTH_WRITE ) ); // 执行深度预渲染... // 深度缓冲区:深度写入 → 深度读取(用于主渲染) mCommandList->ResourceBarrier(1, &CD3DX12_RESOURCE_BARRIER::Transition( mDepthBuffer.Get(), D3D12_RESOURCE_STATE_DEPTH_WRITE, D3D12_RESOURCE_STATE_DEPTH_READ ) ); } 帧结束时的屏障
void EndFrame() { // 后台缓冲区:渲染目标 → 呈现 mCommandList->ResourceBarrier(1, &CD3DX12_RESOURCE_BARRIER::Transition( mBackBuffer.Get(), D3D12_RESOURCE_STATE_RENDER_TARGET, D3D12_RESOURCE_STATE_PRESENT ) ); } 常见错误
void CommonMistakes() { // 错误1:忘记插入必要的屏障 // mCommandList->Draw(...); // 直接使用错误状态的资源 // 错误2:错误的状态转换序列 // 从 COPY_SOURCE 直接转到 RENDER_TARGET(可能需要中间状态) // 错误3:屏障顺序错误 // 应该在设置渲染目标之前转换状态 } 正确方法:✅️
void CorrectUsage() { // 1. 在资源使用前插入屏障 mCommandList->ResourceBarrier(1, &CD3DX12_RESOURCE_BARRIER::Transition(resource, oldState, newState) ); // 2. 使用资源 mCommandList->Draw(...); // 3. 如果需要,恢复资源状态 mCommandList->ResourceBarrier(1, &CD3DX12_RESOURCE_BARRIER::Transition(resource, newState, oldState) ); } 总结
ResourceBarrier 函数是 DirectX 12 显式资源管理的核心,
- 管理状态转换:通知 GPU 资源用途的变化
- 确保同步:防止资源访问冲突和数据竞争
- 优化性能:让驱动能够优化内存访问模式
- 支持批量操作:可以一次处理多个屏障以提高效率
流程总结
创建窗口 → 初始化DX基础设施 → 创建GPU资源 → 建立渲染管线 → 数据传输渲染
时间点 T0: [创建窗口] → 系统内存分配 时间点 T1: [创建设备] → 驱动层初始化 时间点 T2: [命令系统] → GPU命令通道建立 时间点 T3: [交换链] → 显存分配后台缓冲区 时间点 T4: [描述符堆] → 资源视图系统建立 时间点 T5: [深度缓冲区] → 深度测试资源就绪 时间点 T6: [管线状态] → 着色器和状态配置 时间点 T7: [资源上传] → CPU→GPU数据传输 时间点 T8: [首次渲染] → 完整渲染管线运作 ┌─────────────────┐ ┌──────────────────┐ ┌─────────────────┐ │ CPU 操作 │ │ 命令提交 │ │ GPU 操作 │ ├─────────────────┤ ├──────────────────┤ ├─────────────────┤ │ 1. 创建设备 │───▶│ 设备接口建立 │───▶│ GPU硬件初始化 │ │ 2. 创建命令对象 │ │ 命令通道建立 │ │ 命令处理就绪 │ │ 3. 创建资源 │───▶│ 资源描述符传递 │───▶│ 显存分配 │ │ 4. 记录命令 │───▶│ 命令列表提交 │───▶│ 命令执行 │ │ 5. 信号围栏 │───▶│ 同步信号设置 │───▶│ 执行完成通知 │ │ 6. 等待GPU完成 │◀───│ 围栏值检查 │◀───│ 围栏值更新 │ └─────────────────┘ └──────────────────┘ └─────────────────┘ 内存状态
//初始化前: 系统内存: [应用程序代码] [窗口管理数据] 显存: [空闲状态] //初始化后: 系统内存: [应用程序代码] [窗口管理数据] [D3D12设备对象] [命令队列] [命令分配器] [命令列表] [描述符堆管理数据] [围栏同步对象] 显存: [交换链缓冲区0] [交换链缓冲区1] ← 双缓冲 [深度模板缓冲区] [描述符堆] → 指向显存中的资源视图 资源关系
┌─────────────────────────────────────────────────────────────┐ │ 系统内存 (CPU) │ ├─────────────────────────────────────────────────────────────┤ │ D3DApp对象 │ │ ├─ 设备(md3dDevice) ───────────────────────┐ │ │ ├─ 命令队列(mCommandQueue) │ │ │ ├─ 命令列表(mCommandList) │ │ │ ├─ 描述符堆(mRtvHeap, mDsvHeap) │ │ │ └─ 围栏(mFence) ───────────────────────────┼───────────────┐│ └─────────────────────────────────────────────┼───────────────┘│ │ │ ┌─────────────────────────────────────────────┼───────────────┼─┐ │ 显存 (GPU) │ │ │ ├─────────────────────────────────────────────┼───────────────┼─┤ │ 交换链缓冲区资源 │ │ │ │ ├─ 后台缓冲区0 │ │ │ │ ├─ 后台缓冲区1 │ │ │ │ 深度模板缓冲区资源 │ │ │ │ 描述符堆内容 │ │ │ │ ├─ RTV描述符 → 指向交换链缓冲区 │ │ │ │ └─ DSV描述符 → 指向深度模板缓冲区 │ │ │ │ 命令缓冲区 ◀───────────────┘ │ │ 围栏值存储 ◀─────────────────┘ └─────────────────────────────────────────────────────────────┘ 关键数据流
命令提交流程: CPU记录命令 → 命令列表关闭 → 提交到命令队列 → GPU执行 资源创建流程: CPU描述资源 → 创建设备资源 → GPU显存分配 → 创建视图描述符 同步机制: CPU设置围栏值 → GPU完成任务后更新围栏值 → CPU检查围栏值实现同步 双缓冲交换: 前台缓冲区显示 → 后台缓冲区渲染 → Present交换 → 循环继续 阶段1:Windows窗口创建
内存变化:
- 系统分配窗口类内存 (WNDCLASS)
- 创建窗口对象,分配消息队列内存
- 建立设备上下文 (DC) 相关数据结构
RegisterClass(&wc); // 注册窗口类 CreateWindow(...); // 创建窗口对象 ShowWindow(mhMainWnd, SW_SHOW); // 显示窗口 阶段2:DirectX基础设施初始化
2.1 DXGI工厂和设备创建
CreateDXGIFactory1(IID_PPV_ARGS(&mdxgiFactory)); // 创建DXGI工厂 D3D12CreateDevice(...); // 创建设备对象 内存变化:
- 系统内存:创建工厂和设备对象的管理结构
- GPU驱动:初始化设备上下文和硬件抽象层
2.2 命令系统创建
CreateCommandQueue(...); // 命令队列 CreateCommandAllocator(...); // 命令分配器 CreateCommandList(...); // 命令列表 CreateFence(...); // 同步围栏 内存变化:
- 系统内存:命令队列和列表的管理数据结构
- GPU内存:命令分配器预分配命令存储空间
- 共享内存:围栏对象和事件同步机制
阶段3:交换链和渲染目标创建
3.1 交换链创建
CreateSwapChain(mCommandQueue.Get(), ...); // 创建交换链 显存变化:
- 分配双缓冲或三缓冲的后台缓冲区纹理
- 每个缓冲区大小:宽度 × 高度 × 像素格式大小
- 示例:800×600×RGBA8 = 800×600×4 ≈ 1.83MB × 2 ≈ 3.66MB
3.2 描述符堆创建
CreateRtvAndDsvDescriptorHeaps(); // RTV和DSV描述符堆 内存变化:
- 系统内存:描述符堆管理结构
- GPU内存:描述符堆存储空间(每个描述符固定大小)
- RTV堆:2个描述符槽位 × 描述符大小
- DSV堆:1个描述符槽位 × 描述符大小
阶段4:深度缓冲区和视图创建
CreateCommittedResource(...); // 深度模板缓冲区 CreateDepthStencilView(...); // 深度模板视图 显存变化:
- 分配深度模板缓冲区:宽度 × 高度 × 深度格式大小
- 示例:800×600×D24S8 = 800×600×4 ≈ 1.83MB
- 考虑MSAA:如果启用4x MSAA,内存占用×4
阶段5:视口和裁剪矩形配置
mScreenViewport = { ... }; // 视口配置 mScissorRect = { ... }; // 裁剪矩形 内存变化:
- 系统内存:存储视口和裁剪矩形参数
- GPU状态:更新管线状态寄存器
CPU向GPU数据传输流程
数据传输机制
- 资源上传模式
// 创建上传堆资源 CreateCommittedResource( &CD3DX12_HEAP_PROPERTIES(D3D12_HEAP_TYPE_UPLOAD), // 上传堆 ..., IID_PPV_ARGS(&mUploadBuffer)) ); // CPU映射内存并写入数据 UINT8* pData = nullptr; mUploadBuffer->Map(0, nullptr, reinterpret_cast<void**>(&pData)); memcpy(pData, sourceData, dataSize); mUploadBuffer->Unmap(0, nullptr); // GPU从上传堆拷贝到默认堆 mCommandList->CopyResource(mDefaultBuffer.Get(), mUploadBuffer.Get()); 内存变化:
- 系统内存:应用程序准备源数据
- 上传堆:CPU可写的GPU内存区域,存储临时数据
- 默认堆:GPU专用的优化内存,存储最终资源
- 动态常量缓冲区更新
// 每帧更新常量缓冲区 memcpy(mMappedConstantBuffer, &constants, sizeof(Constants)); // 绑定到渲染管线 mCommandList->SetGraphicsRootConstantBufferView(0, mConstantBuffer->GetGPUVirtualAddress()); - 纹理数据上传
// 计算纹理上传所需内存 UINT64 uploadBufferSize = GetRequiredIntermediateSize(texture.Get(), 0, 1); // 填充上传堆 D3D12_SUBRESOURCE_DATA textureData = {}; textureData.pData = pixelData; textureData.RowPitch = imageBytesPerRow; textureData.SlicePitch = imageBytesPerRow * textureDesc.Height; // 安排拷贝命令 UpdateSubresources(mCommandList.Get(), texture.Get(), uploadBuffer.Get(), 0, 0, 1, &textureData); 运行时内存流动
应用程序数据 ↓ CPU处理 系统内存 (准备数据) ↓ 内存拷贝 上传堆 (CPU→GPU传输区) ↓ GPU拷贝命令 默认堆 (GPU专用内存) ↓ GPU渲染操作 渲染目标 (显存中的纹理) ↓ Present交换 显示输出 CPU-GPU同步点
// 1. 围栏同步 mCurrentFence++; mCommandQueue->Signal(mFence.Get(), mCurrentFence); // 2. 资源屏障同步 mCommandList->ResourceBarrier(1, &CD3DX12_RESOURCE_BARRIER::Transition(resource, oldState, newState)); // 3. 刷新命令队列 FlushCommandQueue(); 画一个背景
void InitDirect3DApp::Draw(const GameTimer& gt) { // 1. 重置命令分配器 ThrowIfFailed(mDirectCmdListAlloc->Reset()); // 2. 重置命令列表 ThrowIfFailed(mCommandList->Reset(mDirectCmdListAlloc.Get(), nullptr)); // 3. 资源屏障:从呈现状态转换到渲染目标状态 mCommandList->ResourceBarrier(1, &CD3DX12_RESOURCE_BARRIER::Transition(CurrentBackBuffer(), D3D12_RESOURCE_STATE_PRESENT, D3D12_RESOURCE_STATE_RENDER_TARGET)); // 4. 设置视口和裁剪矩形 mCommandList->RSSetViewports(1, &mScreenViewport); mCommandList->RSSetScissorRects(1, &mScissorRect); // 5. 清除渲染目标和深度模板缓冲区 mCommandList->ClearRenderTargetView(CurrentBackBufferView(), Colors::LightSteelBlue, 0, nullptr); mCommandList->ClearDepthStencilView(DepthStencilView(), D3D12_CLEAR_FLAG_DEPTH | D3D12_CLEAR_FLAG_STENCIL, 1.0f, 0, 0, nullptr); // 6. 设置渲染目标 mCommandList->OMSetRenderTargets(1, &CurrentBackBufferView(), true, &DepthStencilView()); // 7. 资源屏障:从渲染目标状态转换回呈现状态 mCommandList->ResourceBarrier(1, &CD3DX12_RESOURCE_BARRIER::Transition(CurrentBackBuffer(), D3D12_RESOURCE_STATE_RENDER_TARGET, D3D12_RESOURCE_STATE_PRESENT)); // 8. 关闭命令列表 ThrowIfFailed(mCommandList->Close()); // 9. 执行命令列表 ID3D12CommandList* cmdsLists[] = { mCommandList.Get() }; mCommandQueue->ExecuteCommandLists(_countof(cmdsLists), cmdsLists); // 10. 呈现交换链 ThrowIfFailed(mSwapChain->Present(0, 0)); mCurrBackBuffer = (mCurrBackBuffer + 1) % SwapChainBufferCount; // 11. 刷新命令队列 FlushCommandQueue(); } - 准备阶段: 重置命令对象,转换资源状态
- 渲染阶段: 设置管线状态,执行清除和绘制命令
- 完成阶段: 恢复资源状态,提交命令,呈现结果
- 同步阶段: 等待GPU完成,确保资源安全
步骤1-2: 重置命令分配器和命令列表
ThrowIfFailed(mDirectCmdListAlloc->Reset()); ThrowIfFailed(mCommandList->Reset(mDirectCmdListAlloc.Get(), nullptr)); DX12机制:
- 命令分配器 (Command Allocator): 管理GPU命令内存的分配
- 命令列表 (Command List): 记录渲染命令的容器
为什么要这样做:
- 内存重用: 避免每帧都创建新的命令内存,提高性能
- 状态重置: 命令列表在提交后必须重置才能重新使用
- 同步要求: 必须确保GPU已完成之前的命令执行后才能重置
步骤3: 资源屏障 - 状态转换
mCommandList->ResourceBarrier(1, &CD3DX12_RESOURCE_BARRIER::Transition( CurrentBackBuffer(), D3D12_RESOURCE_STATE_PRESENT, // 之前状态 D3D12_RESOURCE_STATE_RENDER_TARGET // 之后状态 )); DX12机制:
- 资源屏障 (Resource Barrier): 同步GPU对不同资源状态的访问
- 状态管理: DX12要求显式管理资源状态转换
为什么要这样做:
之前: PRESENT状态 → 资源可用于显示 转换: 告诉GPU"我要开始渲染了" 之后: RENDER_TARGET状态 → 资源可作为渲染目标写入 步骤4: 设置视口和裁剪矩形
mCommandList->RSSetViewports(1, &mScreenViewport); mCommandList->RSSetScissorRects(1, &mScissorRect); DX12机制:
- 光栅化状态: 控制几何体如何转换为像素
- 命令列表状态: 这些设置是命令列表状态的一部分
为什么要这样做:
- 视口变换: 定义NDC坐标到屏幕坐标的映射
- 裁剪优化: 限制渲染区域,提高性能
- 重置需求: 命令列表重置后会丢失这些状态,需要重新设置
步骤5: 清除渲染目标
ClearRenderTargetView
ClearDepthStencilView
GetCPUDescriptorHandleForHeapStart
mCommandList->ClearRenderTargetView( CurrentBackBufferView(), Colors::LightSteelBlue, // 填充一个颜色 0, nullptr ); mCommandList->ClearDepthStencilView( DepthStencilView(), D3D12_CLEAR_FLAG_DEPTH | D3D12_CLEAR_FLAG_STENCIL, // 清除标志 1.0f, 0, 0, nullptr // 深度值1.0,模板值0 ); D3D12_CPU_DESCRIPTOR_HANDLE D3DApp::CurrentBackBufferView()const { return CD3DX12_CPU_DESCRIPTOR_HANDLE( mRtvHeap->GetCPUDescriptorHandleForHeapStart(), // 堆起始位置 mCurrBackBuffer, // 当前缓冲区索引 mRtvDescriptorSize); // 描述符大小 } D3D12_CPU_DESCRIPTOR_HANDLE D3DApp::DepthStencilView()const { return mDsvHeap->GetCPUDescriptorHandleForHeapStart(); // 直接返回堆起始位置 } 渲染目标视图 (Render Target View)
定义像素着色器输出的目标位置
像素着色器 → RTV → 后台缓冲区 → 屏幕显示
- 绑定阶段: OMSetRenderTargets() 将RTV绑定到输出合并阶段
- 写入阶段: 像素着色器计算的颜色值写入RTV指向的资源
- 显示阶段: 包含渲染结果的缓冲区通过交换链呈现到屏幕
[命令列表记录] ↓ ClearRenderTargetView(RTV) // 清除颜色缓冲区 ↓ OMSetRenderTargets(RTV, DSV) // 绑定输出目标 ↓ [绘制调用] ↓ 像素着色器输出颜色 → RTV → 后台缓冲区 ↓ Present() → 显示到屏幕 深度模板视图 (Depth Stencil View)
管理深度测试和模板测试
[命令列表记录] ↓ ClearDepthStencilView(DSV) // 清除深度/模板 ↓ OMSetRenderTargets(RTV, DSV) // 绑定深度测试目标 ↓ [绘制调用] ↓ 光栅化生成深度值 → 深度测试(使用DSV) → 决定像素可见性 ↓ 模板测试(使用DSV) → 特殊效果处理 几何体 → 深度测试(使用DSV) → 通过 → 像素着色器 → 输出合并 ↓ 深度值比较 ↓ 保留/丢弃像素 深度测试流程:
- 光栅化: 确定像素位置和深度值
- 深度比较: 将当前像素深度与DSV中存储的深度比较
- 决策: 根据比较函数(通常D3D12_COMPARISON_FUNC_LESS)决定是否写入
模板测试流程:
- 模板比较: 比较当前模板值与参考值
- 模板操作: 根据比较结果执行特定操作(保持、替换、递增等)
视图与资源的关系
// 视图不是资源本身,而是资源的"视角"或"接口" 资源 (Resource) = 实际的内存/显存块 视图 (View) = 如何解释和使用这个资源 // 同一个资源可以有多个不同的视图 纹理资源 → [作为渲染目标视图] [作为着色器资源视图] [作为深度模板视图] 为什么需要视图机制?
1.资源复用
// 同一个纹理可以有不同的用途 CreateRenderTargetView(texture); // 作为渲染目标 CreateShaderResourceView(texture); // 作为纹理采样 // 不需要创建多个资源副本 2.类型安全
// 编译器防止错误使用 mCommandList->ClearRenderTargetView(rtvHandle, ...); // 正确 mCommandList->ClearRenderTargetView(dsvHandle, ...); // 编译错误?不,运行时错误 3.抽象层次
// 应用程序不直接操作资源内存 // 通过视图接口进行标准化操作 ClearRenderTargetView(rtv, color); // 统一清除接口 // 而不是直接操作显存 DX12机制:
- 清除操作: 直接写入渲染目标和深度模板缓冲区
- GPU命令: 清除操作作为GPU命令记录,不是CPU操作
为什么要这样做:
- 避免残留: 清除上一帧的内容,防止视觉伪影
- 深度初始化: 将深度缓冲区重置为最远值(1.0)
- 模板重置: 将模板缓冲区重置为初始值(0)
步骤6: 设置输出合并阶段
mCommandList->OMSetRenderTargets( 1, // 渲染目标数量 &CurrentBackBufferView(), // 渲染目标视图 true, // 渲染目标视图是连续的 &DepthStencilView() // 深度模板视图 ); DX12机制:
- 输出合并 (Output Merger): 管线的最后阶段,处理像素输出
- 绑定操作: 将资源绑定到管线阶段
为什么要这样做:
- 目标指定: 告诉GPU将像素着色器输出写入哪里
- 深度测试: 启用深度测试使用的深度模板缓冲区
步骤7: 资源屏障 - 状态恢复
mCommandList->ResourceBarrier(1, &CD3DX12_RESOURCE_BARRIER::Transition( CurrentBackBuffer(), D3D12_RESOURCE_STATE_RENDER_TARGET, // 之前状态 D3D12_RESOURCE_STATE_PRESENT // 之后状态 )); 为什么要这样做:
之前: RENDER_TARGET状态 → 刚完成渲染写入 转换: 告诉GPU"渲染完成,准备显示" 之后: PRESENT状态 → 资源可被交换链呈现 步骤8-9: 命令列表提交
ThrowIfFailed(mCommandList->Close()); ID3D12CommandList* cmdsLists[] = { mCommandList.Get() }; mCommandQueue->ExecuteCommandLists(_countof(cmdsLists), cmdsLists); DX12机制:
- 命令列表关闭: 命令列表必须关闭后才能执行
- 命令队列: GPU命令的执行队列
为什么要这样做:
- 批量提交: 将所有命令一次性提交给GPU
- 异步执行: GPU开始异步执行命令,CPU继续其他工作
步骤10: 交换链呈现
ThrowIfFailed(mSwapChain->Present(0, 0)); mCurrBackBuffer = (mCurrBackBuffer + 1) % SwapChainBufferCount; DX12机制:
- 页面翻转 (Page Flipping): 交换前后缓冲区
- 垂直同步: Present调用可能等待垂直同步
为什么要这样做:
- 双缓冲: 避免渲染过程中的屏幕撕裂
- 缓冲区循环: 在双缓冲区之间轮换
步骤11: 刷新命令队列
FlushCommandQueue(); 为什么要这样做:
- 同步保证: 确保GPU完成当前帧所有命令
- 资源安全: 防止下一帧修改正在使用的资源
- 简化实现: 虽然效率不高,但保证正确性
命令执行流水线
CPU端: [记录命令] → [关闭列表] → [提交队列] → [继续下一帧] GPU端: [获取命令] → [解析命令] → [执行渲染] → [信号围栏] 内存访问: [上传堆] ←CPU写→ [系统内存] → [命令队列] →GPU读→ [默认堆] 资源状态管理的重要性
// 错误做法:不管理状态转换 // GPU可能同时尝试读取和写入同一资源,导致未定义行为 // 正确做法:显式状态转换 D3D12_RESOURCE_STATE_PRESENT ↓ ResourceBarrier D3D12_RESOURCE_STATE_RENDER_TARGET ↓ 渲染操作 D3D12_RESOURCE_STATE_PRESENT 当前实现的局限性:
- 串行执行: CPU等待GPU完成,降低了并行性
- 单命令列表: 无法利用多线程命令记录
- 简单同步: 使用FlushCommandQueue而不是更精细的同步




![洛谷 P11345 [KTSC 2023 R2] 基地简化 题解](http://www.itfaba.com/wp-content/themes/kemi/timthumb.php?src=http://www.itfaba.com/wp-content/themes/kemi/img/random/2.jpg&w=218&h=124&zc=1)
