
ETEGRec:端到端可学习的物品分词与生成式推荐
摘要
现有生成式推荐多采用"两阶段"范式:先离线构造语义标识(Semantic ID),再以固定标识训练生成器,导致分词器与生成器目标失配、分布不一致。ETEGRec 将 RQ-VAE 物品分词器与 T5 式生成器统一到一个端到端框架中,并引入两类推荐导向对齐(SIA、PSA),通过交替优化稳定地联动两模块学习。在 Amazon-2023 三个子集上,ETEGRec 相比传统序列模型与主流生成式基线均取得稳定提升,消融实验验证了对齐与交替优化的有效性。
1. 背景与问题定义
1.1 两阶段生成式推荐的局限
- 解耦训练:分词器(构造语义 ID)与生成器(自回归预测)相互独立,优化目标不一致,难以互相适配。
- 分布失配与模式单一:固定的 token 序列使生成器面对单一的模式,易过拟合;语义空间与偏好空间缺乏耦合。
- 长度偏置:不等长标识会引入预测偏好偏差,需固定长度缓解。
1.2 任务设定与符号
给定用户历史交互序列 (S=[i_1,dots,i_t]),目标是预测下一物品 (i_{t+1})。每个物品以固定长度 (L) 的层级 token 表示:
生成式推荐将任务转化为自回归地生成下一物品的语义 ID:
2. 方法总览
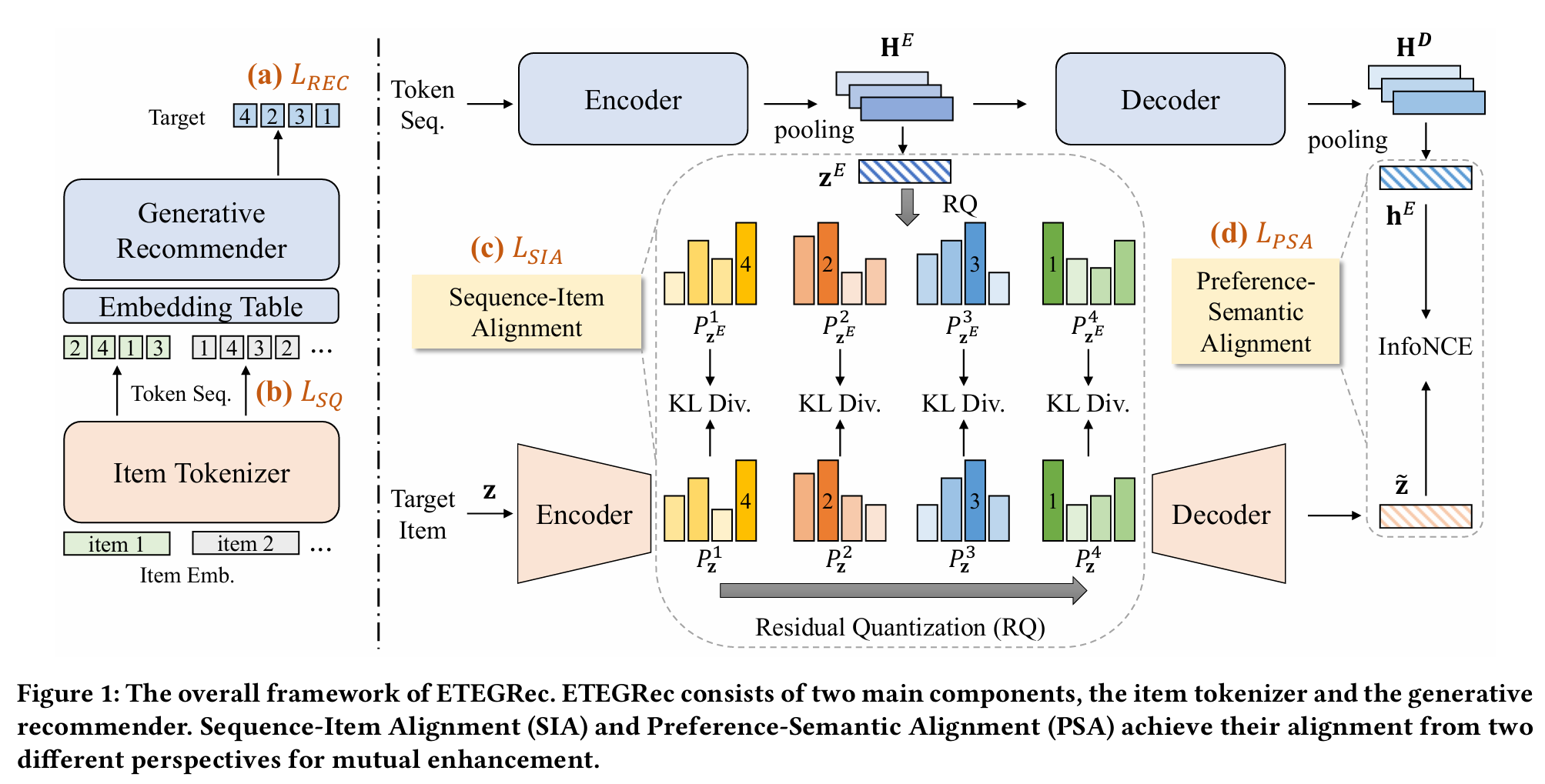
- 双 Encoder–Decoder 架构:
分词器 (T) 采用 RQ-VAE,将连续语义嵌入量化为 (L) 层 token;生成器 (R) 采用 T5 式 Seq2Seq,对历史 token 进行编码并自回归生成目标 token。 - 两类推荐导向对齐:
SIA(Sequence-Item Alignment)对齐编码器的"下一物品语义预测"与真实物品在码本空间上的分布;
PSA(Preference-Semantic Alignment)对齐解码器的"用户总体偏好表示"与物品重构语义。 - 交替优化:周期性冻结/更新 (T) 与 (R) 的参数,稳定推进端到端联合学习。
3. 方法细节(输入→运算→输出)
3.1 物品协同嵌入来源
以已训练的 SASRec 的物品嵌入作为协同语义输入 (mathbf{z} in mathbb{R}^{d_s})。该 (mathbf{z}) 兼具协同信号与部分语义信息,是分词器 (T) 的输入。
3.2 物品分词器 (T):RQ-VAE
输入:(mathbf{z})
编码:(mathbf{r} = mathrm{Enc}_T(mathbf{z}))
多层残差量化(码本层数 (L),每层大小 (K)):
设第 (l) 层码本 (mathcal{C}_l = {mathbf{e}^l_k}_{k=1}^K),令 (mathbf{v}_1 = mathbf{r})。逐层选择:
残差更新:
量化表示:
解码与重构:(tilde{mathbf{z}} = mathrm{Dec}_T(tilde{mathbf{r}}))
损失:
其中 (mathrm{sg}[cdot]) 为停止梯度,(beta) 为平衡系数。
输出:层级语义 ID ([c^{(1)},dots,c^{(L)}])、量化向量 (tilde{mathbf{r}})、重构语义 (tilde{mathbf{z}})
直观:第 1 层捕获粗粒度语义,后续层在残差上逐层细化;固定长度 (L) 减少长度偏置。
3.3 生成式推荐器 (R):T5 式 Seq2Seq
输入:将历史序列中的每个物品经 (T) token 化,得到
查表嵌入并加位置编码,得 (mathbf{E}_X in mathbb{R}^{|mathbf{X}| times d_h})
编码器:多层自注意力与前馈后输出
解码器:以 [BOS] 起始,掩蔽自注意力保证自回归;跨注意力以 (mathbf{H}_E) 为键值(K、V)。输出隐藏态
(mathbf{h}_D) 聚合了对 (mathbf{H}_E) 的全局关注,可视为"用户总体偏好摘要"。
逐层预测:第 (j) 个解码位置对应第 (j) 层码本分类
训练目标(Teacher Forcing):
推理:固定步长 (L) 的 beam search,自回归生成 ([c_{t+1}^{(1)},dots,c_{t+1}^{(L)}]),经唯一映射反查物品。
3.4 推荐导向对齐(核心创新)
SIA:序列-物品分布对齐
从 (mathbf{H}_E) 汇聚得到
将 (mathbf{z}) 与 (mathbf{z}_E) 分别送入同一分词器,得到各层分布 ({P^l_{mathbf{z}}})、({P^l_{mathbf{z}_E}}),用对称 KL 对齐:
作用:迫使编码器在"码本空间"直接预测与目标物品一致的分布,避免解码器绕过编码器。
PSA:偏好-语义向量对齐
以 (mathbf{h}_D) 与 (tilde{mathbf{z}}) 为正样本对,采用双向 InfoNCE(批内负样本):
其中 (s) 为余弦相似度,(tau) 为温度,(mathcal{B}) 为 mini-batch。
作用:将"用户总体偏好"锚定到"物品语义空间",保持两空间同构。
3.5 交替优化与"损失—参数—梯度"映射
阶段 A(优化分词器,冻结生成器):
更新 (theta_T = {theta_{mathrm{Enc}_T}, theta_{mathrm{Dec}_T}, {mathcal{C}_l}_{l=1}^L}) 及 SIA 的 MLP。
- (L_{mathrm{SQ}}) 仅影响分词器;
- (L_{mathrm{SIA}}) 通过 (mathbf{z}_E) 的分布与 (mathbf{z}) 的分布对齐,反向至码本与分词器;
- (L_{mathrm{PSA}}) 将 (tilde{mathbf{z}}) 拉向 (mathbf{h}_D) 的方向,更新分词器(使重构语义更贴合偏好)。
阶段 B(优化生成器,冻结分词器):
更新 (theta_R = {theta_{mathrm{Enc}_R}, theta_{mathrm{Dec}_R}, {mathbf{E}^{(j)}}_{j=1}^L}) 及 SIA 的 MLP。
- (L_{mathrm{REC}}) 反向经解码器→编码器;
- (L_{mathrm{SIA}}) 更新编码器与 MLP(使 (mathbf{z}_E) 的分布靠近 (mathbf{z}) 的分布);
- (L_{mathrm{PSA}}) 将 (mathbf{h}_D) 拉向 (tilde{mathbf{z}}),主要更新解码器。
收敛策略:循环数个周期,直至分词器收敛后固定,再充分训练生成器。
4. 复杂度与推理
- 分词器:单物品 token 化复杂度约为 (mathcal{O}(d^2 + LKd))。
- 生成器:序列建模主耗时为自注意力 (mathcal{O}(N^2 d)) 与前馈 (mathcal{O}(N d^2));逐层分类与 SIA 为 (mathcal{O}(LKd));PSA 为 (mathcal{O}(Md))((M) 为批内负样本数)。
- 总体量级:与 TIGER、LETTER 相当。推理阶段可预缓存语义 ID,生成步长固定为 (L)。
5. 实验与结果要点
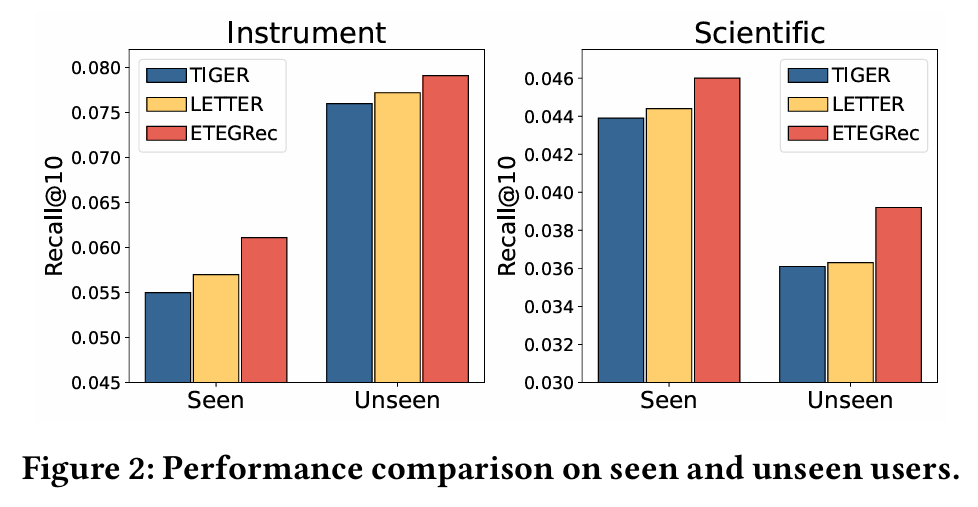
5.1 整体表现(Overall Performance)
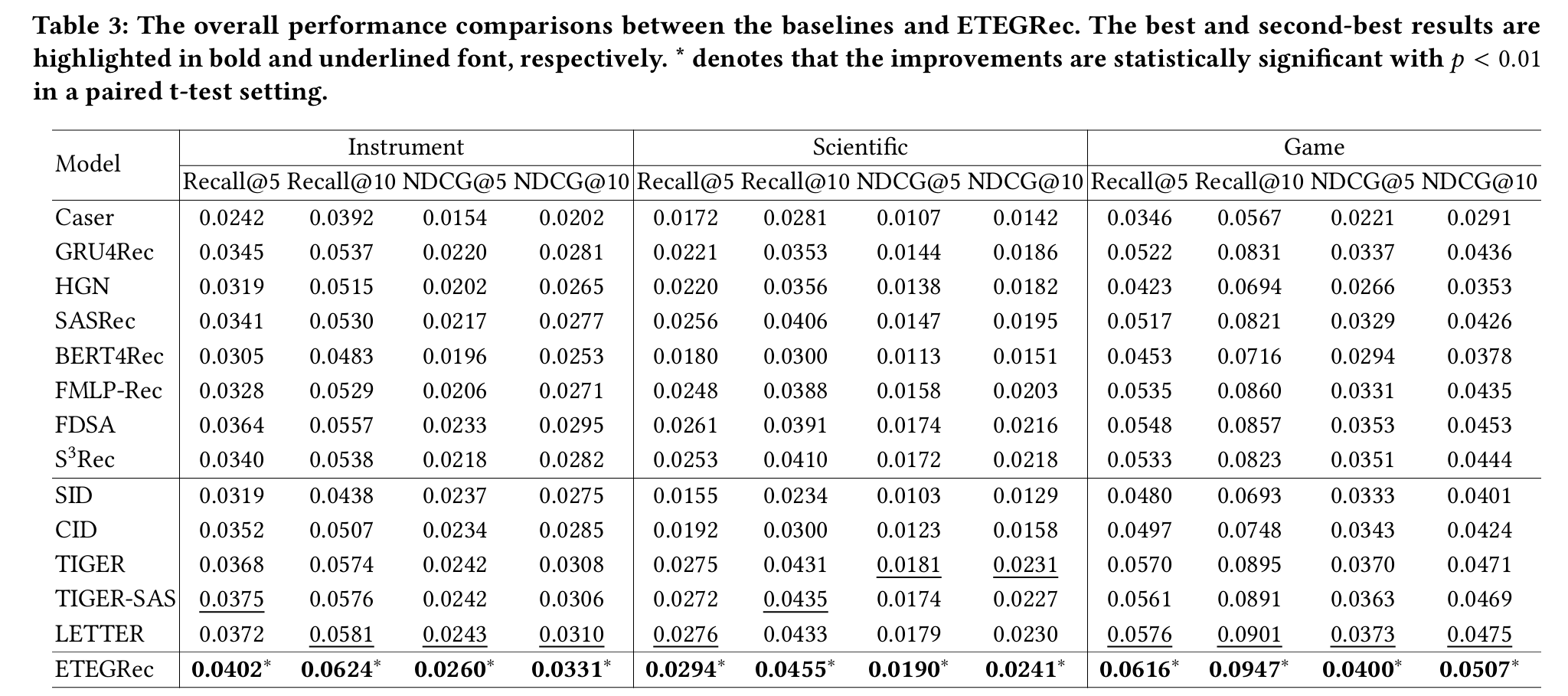
我们在三个公共推荐基准上评估了 ETEGRec。表 3 给出了总体结果,主要观察如下:
- 传统序列推荐模型。 FDSA 在三个数据集上整体表现更优,主要得益于其引入了额外的文本特征嵌入。FMLP-Rec 与 SASRec、BERT4Rec 的表现大致相当,说明全 MLP 架构同样能够有效建模行为序列。
- 生成式推荐模型。 TIGER 与 TIGER-SAS 在三个数据集上稳定优于 CID 和 SID,即便后者采用了参数规模更大的预训练 T5。其性能差异主要来自物品分词策略的不同:SID 使用数值型 token 索引物品,缺乏语义信息;CID 基于物品共现图的启发式分词难以有效捕获物品相似性。相比之下,TIGER 与 TIGER-SAS 通过 RQ-VAE 从粗到细地学习层级文本或协同语义,更有利于推荐任务。值得注意的是,TIGER-SAS 与 TIGER 表现接近,表明协同与文本语义均对效果有重要贡献。LETTER 在多数场景下最佳,因为其有效融合了协同与文本语义信息。
- 我们的方法。 与所有基线相比,ETEGRec 在全部数据集上持续取得最优结果,验证了方法的有效性。我们将性能提升归因于通过面向推荐的对齐实现的物品分词器与生成式推荐器的相互增强。
-
- SIA 使编码器在码本空间的预测与目标一致;
- PSA 将解码器的偏好表示锚定到物品语义;
- 交替优化缓解两模块的相互干扰并稳定收敛。
5.2 消融实验(Ablation Study)
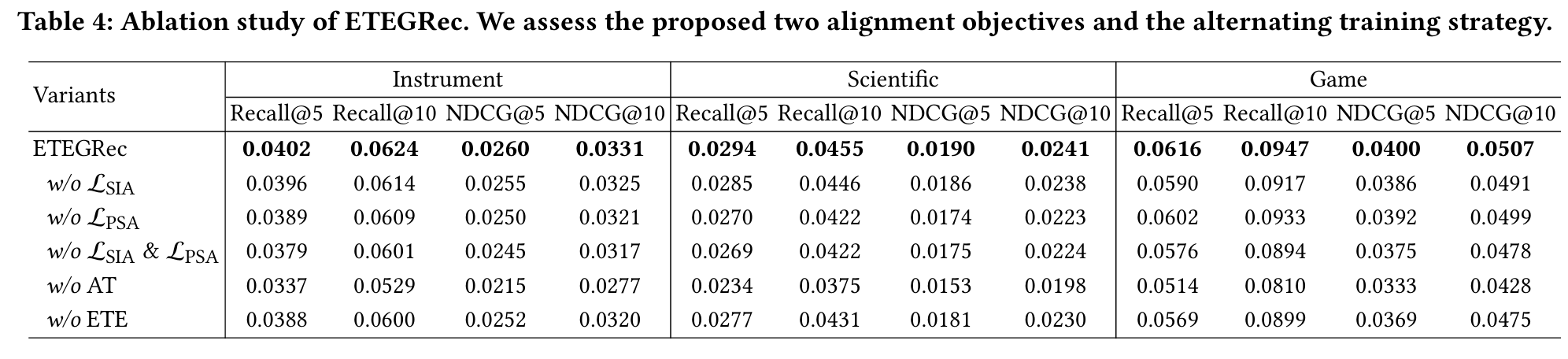
为评估 ETEGRec 中各个技术组件的影响,我们在三个数据集上进行了消融研究,四个变体的结果见表:
- w/o LSIA: 去除序列—物品对齐(SIA,式(15))。该变体在各数据集上均劣于完整 ETEGRec,表明在码本空间中对齐序列表示与物品表示有助于生成式推荐。
- w/o LPSA: 去除偏好—语义对齐(PSA,式(16)),同样导致性能下降,说明 PSA 损失能够增强用户偏好建模。
- w/o LSIA & LPSA: 同时去除两种对齐,效果劣于只去除其中一种,进一步表明 SIA 与 PSA 均有正向贡献,且二者叠加可带来更好的性能。
- w/o AT: 直接联合优化框架内所有目标,不采用交替训练策略。结果显示性能显著下降,说明在训练过程中对分词器的频繁更新会干扰推荐器的学习;采用交替训练可在保持组件协同对齐的同时实现稳定且有效的训练。
- w/o ETE: 不进行端到端联合优化,而是使用 ETEGRec 最终得到的物品 token 重新训练一个生成式推荐器。结果表明,ETEGRec 的改进不仅来源于更优的物品标识符,还得益于将分词器中编码的先验知识与生成式推荐器进行一体化融合。
6. 小结
ETEGRec 以 RQ-VAE 分词器和 T5 式生成器为基础,通过 SIA 与 PSA 在码本分布与语义向量两层面对齐"历史序列语义—用户偏好—物品语义",并以交替优化稳定推进端到端联合学习。相较两阶段范式,ETEGRec 不仅获得更高的离线指标,也在新用户与长尾场景展现更稳健的泛化能力,具备在推荐系统中落地的可行性。




![洛谷 P11345 [KTSC 2023 R2] 基地简化 题解](http://www.itfaba.com/wp-content/themes/kemi/timthumb.php?src=http://www.itfaba.com/wp-content/themes/kemi/img/random/1.jpg&w=218&h=124&zc=1)
