
前言
之前讨论了一元线性回归,主要是qps与cpu的关系,但是现实中cpu只是系统指标的一部分,还有内存、io、网络等等,本小节就来讨论一下,通过多个系统参数对于qps的影响
算法
多元线性回归,就是讨论多个自变量对结果造成的影响
开始探索
老规矩,先来看一看怎么快速使用多元线性回归
1. scikit-learn包的使用
先不管什么鸡r原理,我目前也不想懂,我就需要看到效果,怎么进行多元回归分析。好的,请出老朋友,scikit-learn包,帮助我们快速上手
安装
pip3 install -U scikit-learn 使用
from sklearn.linear_model import LinearRegression from sklearn.model_selection import train_test_split from sklearn.metrics import mean_squared_error, r2_score import pandas as pd import numpy as np data = { 'result': [0.63, 0.72, 0.72, 0.63, 0.57, 0.52, 0.48, 0.47], 'feature1': [22.48, 19.50, 18.02, 16.97, 15.78, 15.11, 14.02, 13.24], 'feature2': [42.77, 59.68, 35.09, 67.82, 43.48, 57.43, 54.85, 34.09], } df = pd.DataFrame(data) X = df[[ 'feature1', 'feature2', ]] y = df['result'] model = LinearRegression() model.fit(X, y) # 输出各自变量的系数 print("回归系数:", model.coef_) y_pred = model.predict(X) print("R²:", r2_score(y, y_pred)) print("MSE:", mean_squared_error(y, y_pred)) 三个特征,分别为feature1 feature2 feature3,它们共同作用于result
脚本!启动:
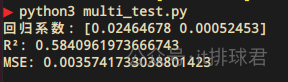
2. 报告解读
与一元线性回归类似
- MSE:均方误差,用于衡量模型预测值与真实值之间的差异,越趋于0越好
- R²:决定系数,用于评估线性回归模型拟合优度的重要指标,其取值范围为[0, 1]
- 回归系数:每个自变量的权重,表示自变量对结果的影响程度,
+表示正相关,-表示负相关
深入理解多元线性回归
多元线性回归就是探索多个自变量对于结果的影响,相比于一元线性回归,它更加复杂,变化更多,但是适用性更广
1. 数学模型
- (β_0) 叫做截距,在模型中起到了“基准值”的作用,就是当自变量为0的时候,因变量的基准值
- (β_1) (β_2) (dots) (β_n) 叫做自变量系数或者回归系数,描述了自变量对结果的影响方向和大小
- 多元回归中,依然使用最小二乘法,是
scikit-learn包的默认算法
- 多元回归中,依然使用最小二乘法,是
- ϵ是误差项,代表了模型未能解释的部分
2. 损失函数
线性回归通常使用均方误差(MSE)来作为损失函数,衡量测试值与真实值之间的差异
其中(y_i)是真实值,(hat{y}_i)是预测值
正如前文提到,MSE中真实值与预测值,有平方计算,那就会放大误差,所以MSE可以非常有效的检测误差项
3. 最小二乘法
与一元回归同理,常见的方法是最小二乘法,只不过推导方式要比一元回归更加复杂
4. 决定系数
用于评估线性回归模型拟合优度的重要指标,其取值范围为 [0, 1]
其中(y_i)是真实值,(hat{y}_i)是预测值,(bar{y})是均值
5. 调整决定系数
先来看下决定系数的公式
随着自变量 (x) 的增加,(y_i - (β_0 + β_1x_1 + β_2x_2 + dots + β_nx_n + ϵ)) 会越来越大,作为分子,导致R²也会越来越大。
在多元回归当中,只要增加自变量个数,就有可能让R²提升,所以单纯看R²是不真实的,需要额外的指标来判断
import numpy as np import pandas as pd from sklearn.linear_model import LinearRegression from sklearn.metrics import r2_score def adjusted_r2(r2, n, p): return 1 - (1 - r2) * (n - 1) / (n - p - 1) np.random.seed(0) n_samples = 1000 feature1 = np.random.rand(n_samples, 1) result = 5 * feature1[:, 0] + np.random.normal(0, 10, n_samples) data1 = { 'result': list(result), 'feature1': list(feature1), } df = pd.DataFrame(data1) X1 = df[[ 'feature1', ]] y1 = df['result'] model1 = LinearRegression().fit(X1, y1) y_pred = model1.predict(X1) r2_1 = r2_score(y1, y_pred) print("n模型1(feature1):") print(f"R² = {r2_1:.4f}") features = { 'feature1': list(feature1), 'feature2': list(np.random.rand(n_samples, 1)), 'feature3': list(np.random.rand(n_samples, 1)), 'feature4': list(np.random.rand(n_samples, 1)), 'feature5': list(np.random.rand(n_samples, 1)), 'feature6': list(np.random.rand(n_samples, 1)), 'feature7': list(np.random.rand(n_samples, 1)), 'feature8': list(np.random.rand(n_samples, 1)), 'feature9': list(np.random.rand(n_samples, 1)), } data2 = { 'result': list(result), } data2.update(features) df2 = pd.DataFrame(data2) y2 = df2['result'] X2 = df2[[ 'feature1', 'feature2', 'feature3', 'feature4', 'feature5', 'feature6', 'feature7', 'feature9', ]] model2 = LinearRegression().fit(X2, y2) y_pred = model2.predict(X2) r2_2 = r2_score(y2, y_pred) print("n模型2(feature1 ~ 9):") print(f"R² = {r2_2:.4f}") 脚本!启动:
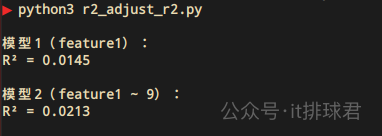
从1个特征,上升到9个特征,R²上升了一个百分点,0.0145 --> 0.0213,理论上模型的泛化能力上升了,但正如之前分析的,随着参数的增多,有概率让R²提升,但是模型没有得到优化。所以需要有额外的指标来判断
调整决定系数:
- R²:决定系数
- n:样本数
- k:自变量(特征)数量
调整决定系数的特点:
- 惩罚不必要的变量:在计算时考虑了变量的个数,避免了无意义变量的加入带来的虚假提升。
- 更公平地比较不同的模型:当模型的自变量个数不同,直接比较决定系数可能会产生误导,而调整决定系数提供了更公平的衡量标准
- 在特征选择时更有参考价值:如果加入新变量后,调整决定系数下降,则说明这个变量可能是不必要的;如果调整决定系数上升,说明新变量有助于提升模型的解释能力。
import numpy as np import pandas as pd from sklearn.linear_model import LinearRegression from sklearn.metrics import r2_score def adjusted_r2(r2, n, p): return 1 - (1 - r2) * (n - 1) / (n - p - 1) np.random.seed(0) n_samples = 1000 feature1 = np.random.rand(n_samples, 1) result = 5 * feature1[:, 0] + np.random.normal(0, 10, n_samples) data1 = { 'result': list(result), 'feature1': list(feature1), } df = pd.DataFrame(data1) X1 = df[[ 'feature1', ]] y1 = df['result'] model1 = LinearRegression().fit(X1, y1) y_pred = model1.predict(X1) r2_1 = r2_score(y1, y_pred) r2_adj_1 = adjusted_r2(r2_1, n_samples, 1) print("n模型1(feature1):") print(f"R² = {r2_1:.4f}, Adjusted R² = {r2_adj_1:.4f}") features = { 'feature1': list(feature1), 'feature2': list(np.random.rand(n_samples, 1)), 'feature3': list(np.random.rand(n_samples, 1)), 'feature4': list(np.random.rand(n_samples, 1)), 'feature5': list(np.random.rand(n_samples, 1)), 'feature6': list(np.random.rand(n_samples, 1)), 'feature7': list(np.random.rand(n_samples, 1)), 'feature8': list(np.random.rand(n_samples, 1)), 'feature9': list(np.random.rand(n_samples, 1)), } data2 = { 'result': list(result), } data2.update(features) df2 = pd.DataFrame(data2) y2 = df2['result'] X2 = df2[[ 'feature1', 'feature2', 'feature3', 'feature4', 'feature5', 'feature6', 'feature7', 'feature8', 'feature9', ]] model2 = LinearRegression().fit(X2, y2) y_pred = model2.predict(X2) r2_2 = r2_score(y2, y_pred) r2_adj_2 = adjusted_r2(r2_2, n_samples, len(features.keys())) print("n模型2(feature1 ~ 9):") print(f"R² = {r2_2:.4f}, Adjusted R² = {r2_adj_2:.4f}") 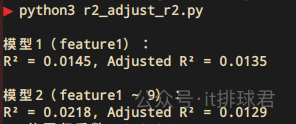
我们看到,虽然决定系数R²上升了,但是调整决定系数却下降了,这就表示虽然添加了额外的8个特征,并没有使得模型解释度上升,反而下降了
最后说下调整决定系数的取值范围
- 接近1:模型拟合非常好,自变量对因变量解释力强
- 接近0:模型几乎没有解释力,拟合效果很差
- 小于0:模型比用常数(均值)预测还差,严重不合理。可能过拟合或选错变量了
没错,调整决定系数是可以小于0的
Lasso回归
简单概括就是可以自动筛选“无用特征”,并且放弃,然后重新训练模型。而筛选特征的方式是,经过lasso模型训练之后,无用特征的系数(注意这里不是线性回归系数,是lasso训练之后的回归系数)被标记为0
1. 数学模型
2. 实践
继续上文的例子,新加了8个特征,但是造成的结果却是调整R²反而下降了,这就说明了有无用的特征加入了进来,这时我们用lasso进行特征筛选
from sklearn.preprocessing import StandardScaler scaler = StandardScaler() X_scaled = scaler.fit_transform(X2) from sklearn.linear_model import Lasso lasso = Lasso(alpha=0.1) lasso.fit(X_scaled, y2) for i, coef in enumerate(lasso.coef_, 1): print(f'x{i} 的系数:{coef:.4f}') 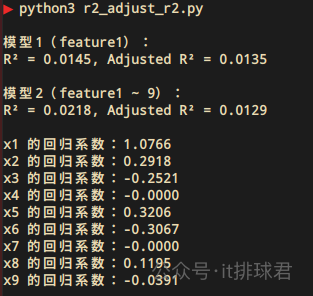
找到了2个特征的系数为0,x4与x7,将这两个特征踢掉
features = { 'feature1': list(feature1), 'feature2': list(np.random.rand(n_samples, 1)), 'feature3': list(np.random.rand(n_samples, 1)), # 'feature4': list(np.random.rand(n_samples, 1)), 'feature5': list(np.random.rand(n_samples, 1)), 'feature6': list(np.random.rand(n_samples, 1)), # 'feature7': list(np.random.rand(n_samples, 1)), 'feature8': list(np.random.rand(n_samples, 1)), 'feature9': list(np.random.rand(n_samples, 1)), } X2 = df2[[ 'feature1', 'feature2', 'feature3', # 'feature4', 'feature5', 'feature6', # 'feature7', 'feature8', 'feature9', ]] 再运行一遍
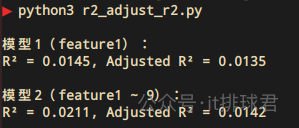
去掉了2个无用的特征,带来的就是模型R²的上升,并且调整R²也跟着上升了,说明了这些新加入的特征是真的有效果
lasso回归可以自动帮我们筛选特征,而刚才我们是先通过lasso回归将无用特征筛选出来,并且手动去掉,而这一切lasso回归可以自动帮我们完成
记住这个值,加入新的特征,模型R²0.0211,调整R²0.0142
下面通过lasso自动筛选来完成,没有去掉特征,直接将下面代码加入
from sklearn.preprocessing import StandardScaler scaler = StandardScaler() X_scaled = scaler.fit_transform(X2) from sklearn.linear_model import Lasso lasso = Lasso(alpha=0.1) lasso.fit(X_scaled, y2) y_lasso = lasso.predict(X_scaled) r2_lasso = r2_score(y2, y_lasso) r2_adj_lasso = adjusted_r2(r2_lasso, n_samples, 7) print("nlasso模型:") print(f"R² = {r2_lasso:.4f}, Adjusted R² = {r2_adj_lasso:.4f}") 脚本!启动:
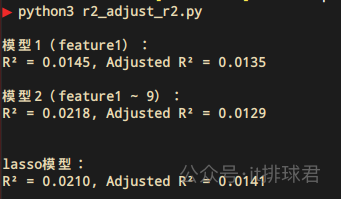
不解释了!
联系我
- 联系我,做深入的交流

至此,本文结束
在下才疏学浅,有撒汤漏水的,请各位不吝赐教...




![洛谷 P11345 [KTSC 2023 R2] 基地简化 题解](http://www.itfaba.com/wp-content/themes/kemi/timthumb.php?src=http://www.itfaba.com/wp-content/themes/kemi/img/random/1.jpg&w=218&h=124&zc=1)
