
引言:一张图也能“说话”?
你有没有想过,一张静态的照片,配上一段音频,就能变成一段“对嘴”的视频?不是简单的口型同步,而是让图片中的人物“活过来”,仿佛真的在说话、唱歌、甚至表演。
这听起来像是科幻电影里的场景,但其实,这样的技术已经在我们身边悄然实现了。
之前已经介绍过一些类似项目的搭建:
FLOAT: https://www.cnblogs.com/cj8988/p/18984186 (带表情,比较快,但是会裁剪为正方形尺寸)
DICE-Talk:https://www.cnblogs.com/cj8988/p/18957718 (带表情,比较慢)
ComfyUI_Sonic:https://www.cnblogs.com/cj8988/p/18952604 (基础版,效果好)
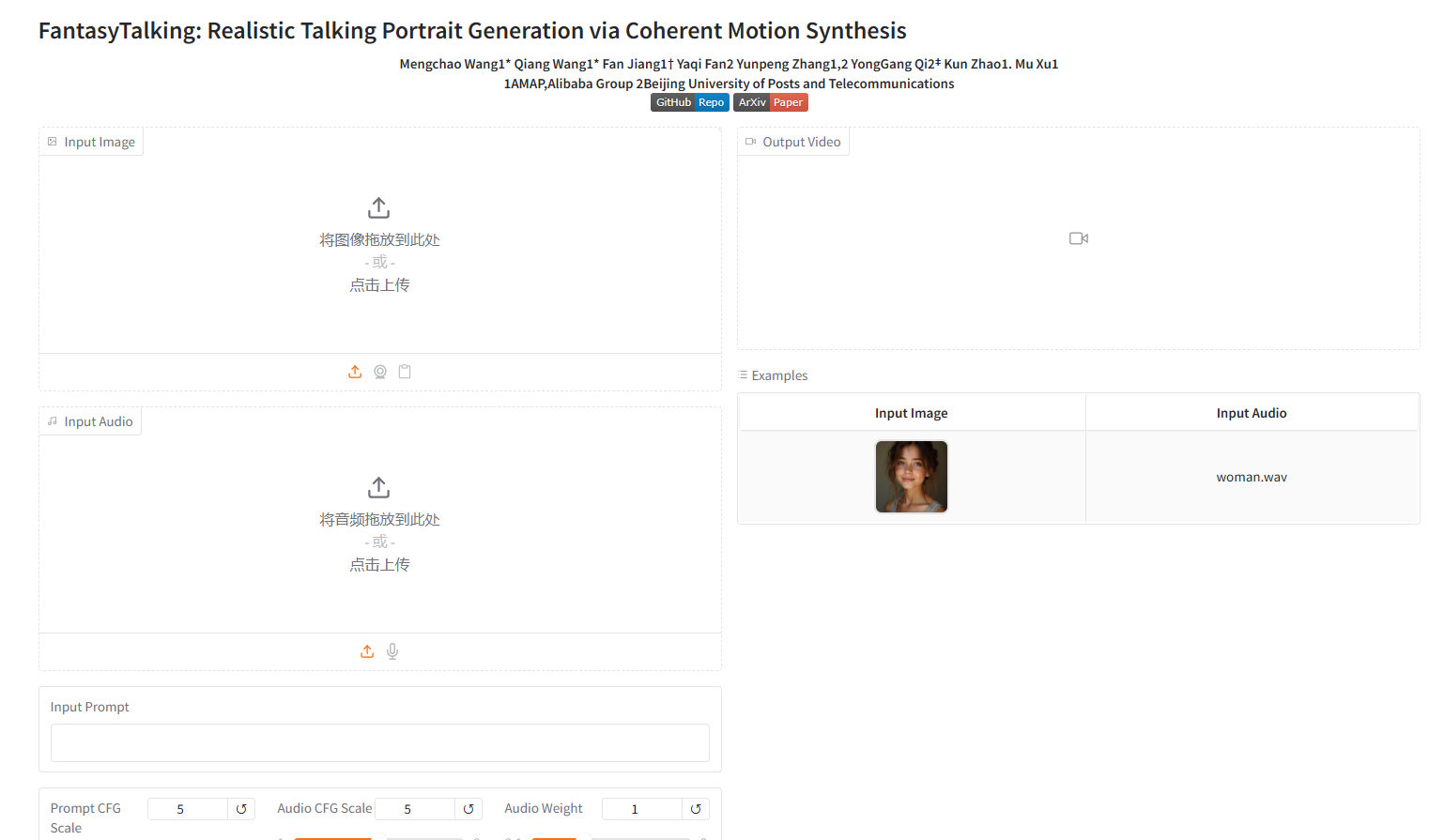
今天要介绍的这个开源项目 —— fantasy-talking,就是这样一个神奇的存在。它能让你上传一张图片和一段音频,自动生成一段“对嘴”的视频,效果之逼真,令人惊叹。
这篇文章,我们就来一起看看这个项目的魅力所在,以及它是如何做到“让图片开口说话”的。
一、项目简介:fantasy-talking 是什么?
fantasy-talking 是一个基于深度学习的开源项目,旨在实现将静态图片与语音音频结合,生成一段看起来像是人物在“说话”的视频。项目代码托管在 GitHub 上,目前已有不少开发者关注和贡献。
它的核心思想是通过语音驱动模型,生成与语音内容匹配的面部动作(尤其是嘴巴动作),再结合原始图片中的人物面部结构,生成一帧帧动态画面,最终合成一段视频。
简单来说,只要你有一张正面清晰的人脸照片,和一段你想让他“说”的语音,这个项目就能帮你生成一段“他”在说话的视频。
二、搭建过程:动手试试看
如果你对这个项目感兴趣,不妨亲自搭建一下试试看。以下是大致的搭建流程:
环境准备
- Python 3.10
- Anaconda
- PyTorch
- CUDA 环境(如果你有 GPU)
- 磁盘空间大,因为要下载大量的模型文件
步骤概览
-
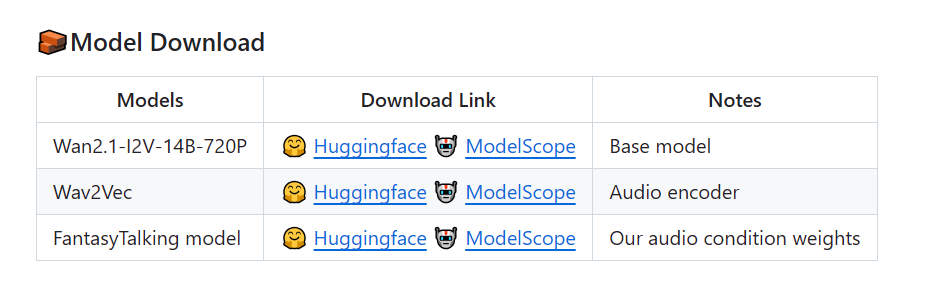
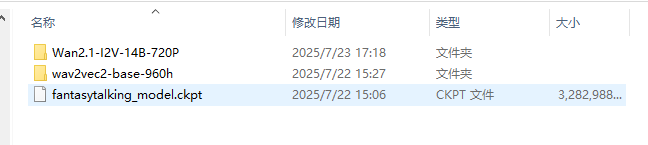
克隆仓库









![洛谷 P11345 [KTSC 2023 R2] 基地简化 题解](http://www.itfaba.com/wp-content/themes/kemi/timthumb.php?src=http://www.itfaba.com/wp-content/themes/kemi/img/random/2.jpg&w=218&h=124&zc=1)
