
link:https://dl.acm.org/doi/10.1145/3397271.3401092
本文提出了一种新的动态图神经网络模型DGNN,它可以随着图的演化对动态信息进行建模。特别是,该框架可以通过捕获:
1、边的序列信息,
2、边之间的时间间隔,
3、信息传播耦合性
来不断更新节点信息。
在本文中,提出了一种用于动态图的新图神经网络架构DGNN。该架构有两个组件构成:更新组件和传播组件。引入新边时,更新组件可以通过捕获边的创建顺序信息和交互之间的时间间隔来保持节点信息的更新(即摘要中的1,2)。传播组件通过考虑影响强度,将新的交互信息传播到受影响节点。作何以链接预测和节点分类为例来说明如何利用DGCN来推进图挖掘任务。在三个真实的动态图上进行了实验,链路预测和节点分类方面的实验结果表明了动态信息的重要性,以及所提出的更新和传播组件在捕获动态信息方面的有效性。
接着说想要对个模型提供一些关于选择邻居作为受影响的节点集的理论分析,并研究其他方法,如图挖掘任务等

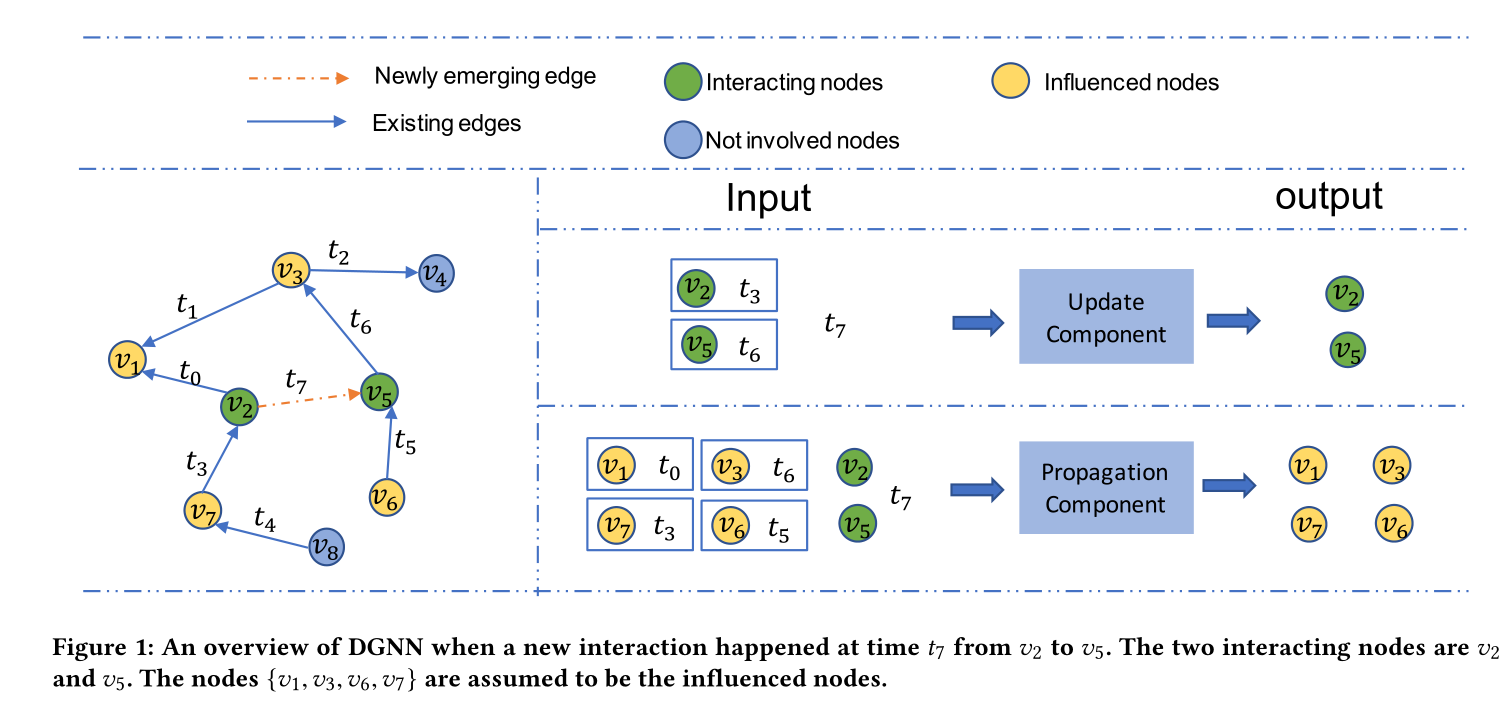
图1:DGNN的总览图。当有新边(t_7)加进来,(t_7)边的两个节点为((v2,v5)),更新组件将(v2)的最新边t3和(v5)的最新边t6做输入。受影响的点为({ v_1,v_3,v_6,v_7 }),传播组件将受影响的边(t0,t6,t3,t5)作为输入。
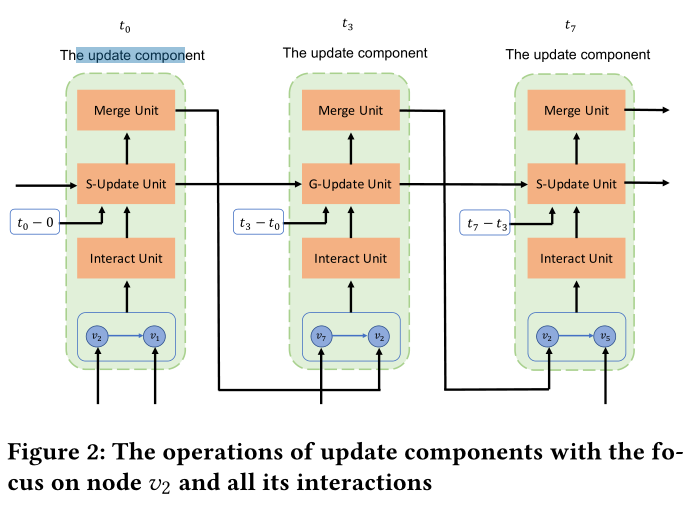
图2:更新组件的操作,以(v2)和他的所有交互为例
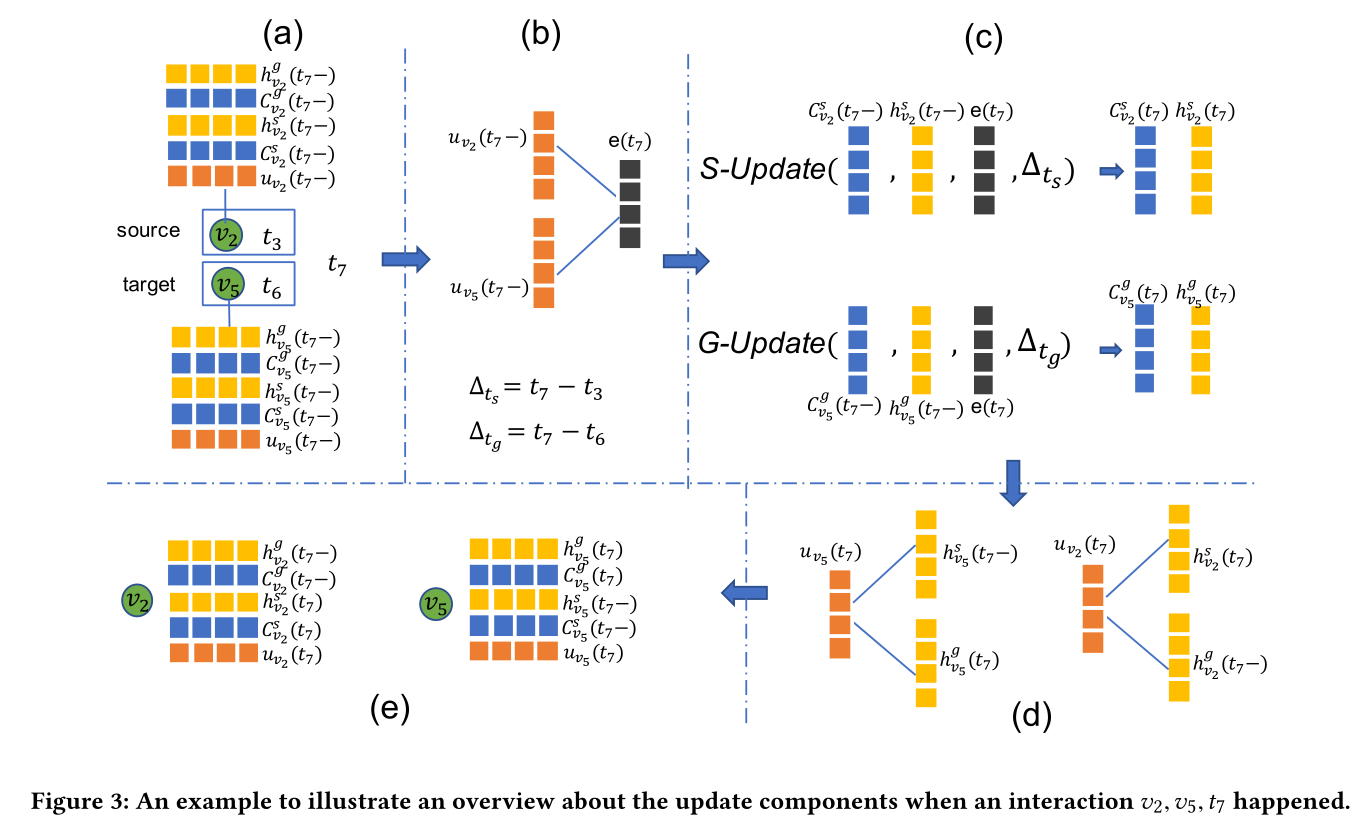
图3:举个例子来说明当({ v2, v5, t7 })交互发生时,更新组件的概述
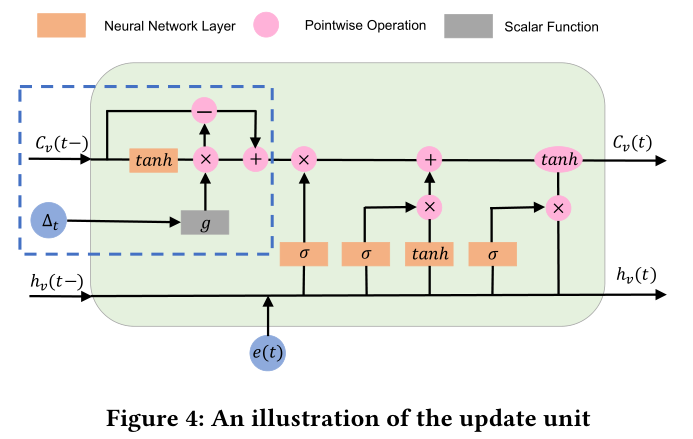
图4:更新单元(改版LSTM)
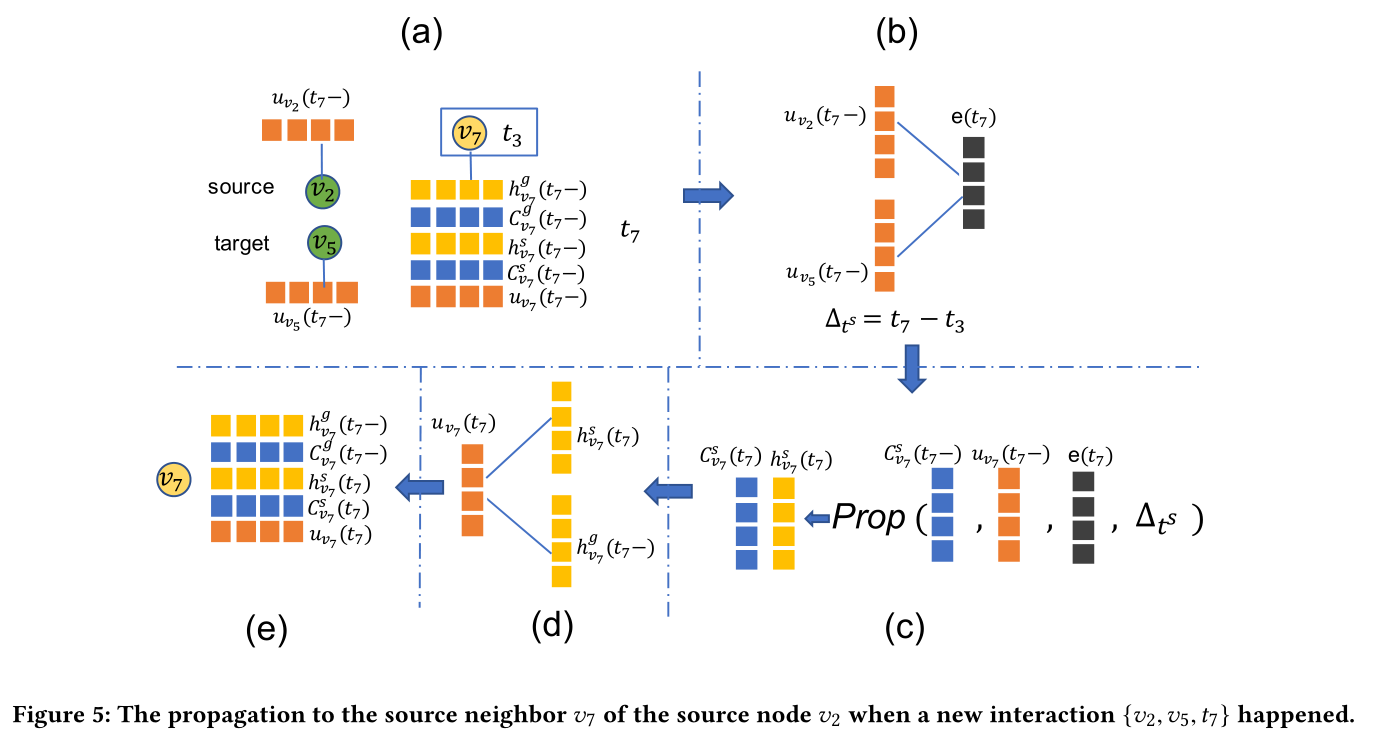
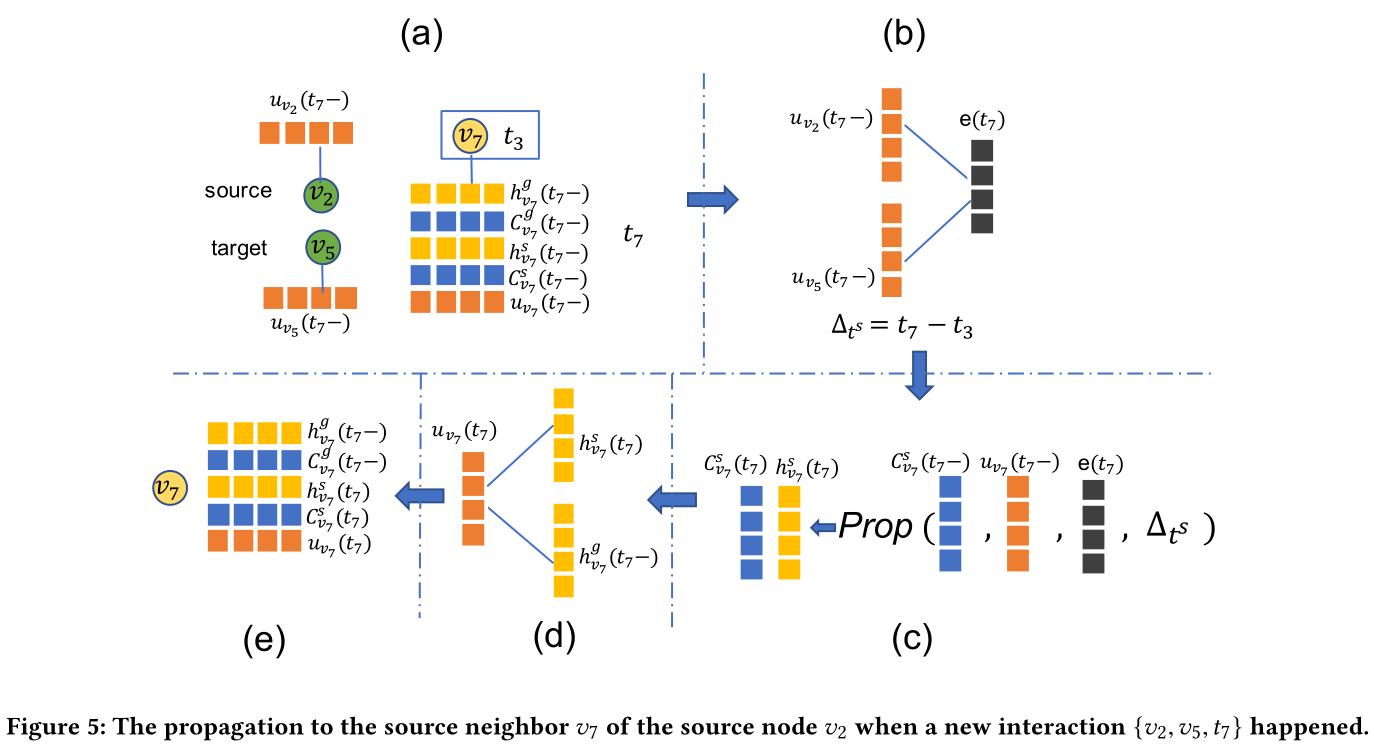
图5:当({ v2, v5, t7 })交互发生,v2向邻居v7进行传播的过程
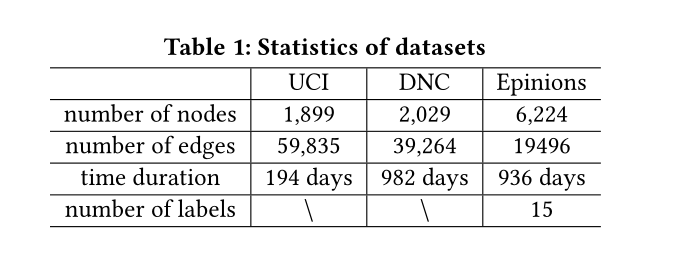
表1:数据集参数
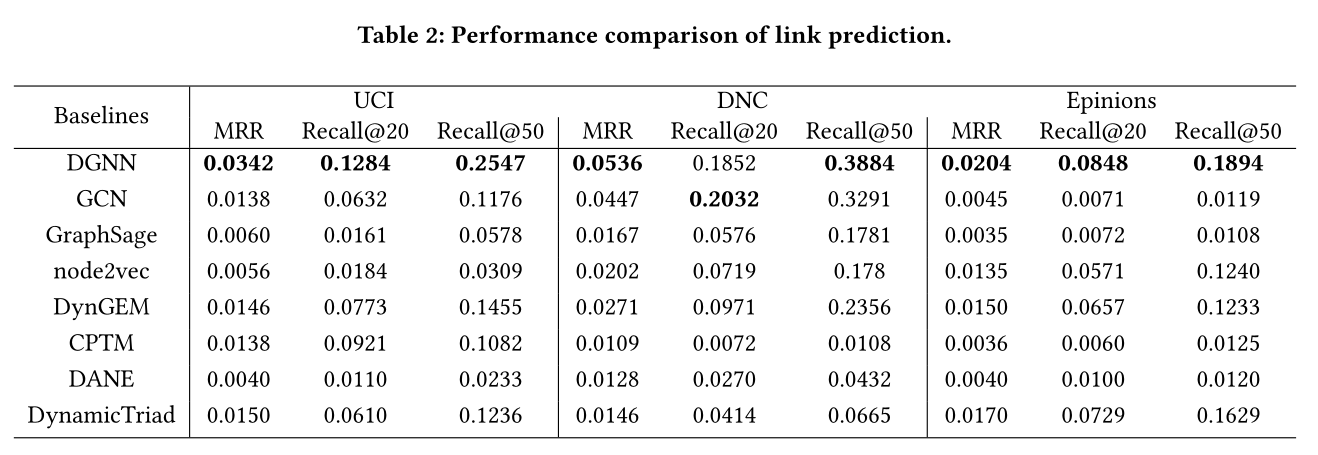
表2:sota
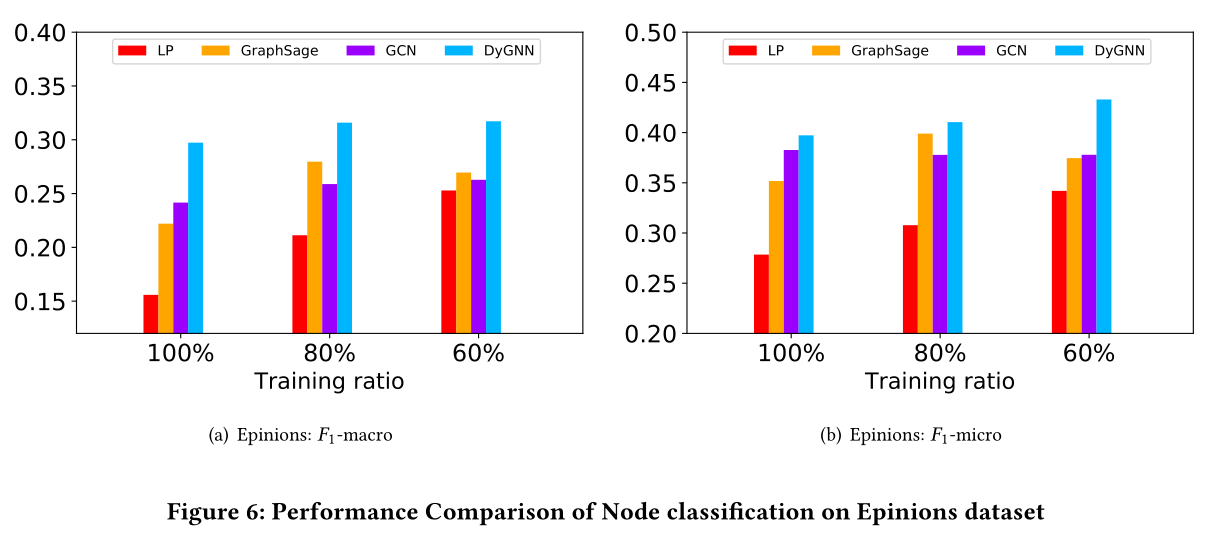
图6:在Epinions上的节点分类效果对比
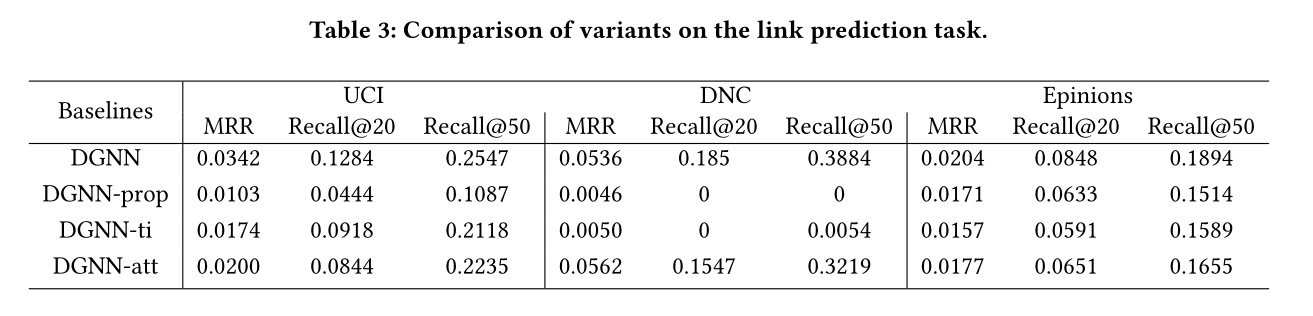
表3:DGNN的变体在链接预测上的表现
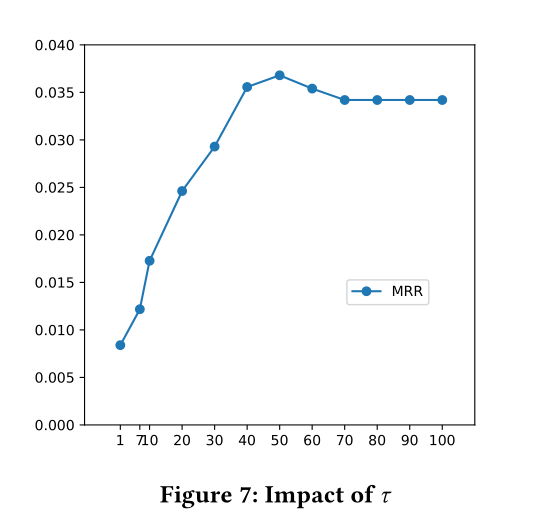
图7:(tau)对MRR的影响
照例提一下原先工作都是在静态图上的,但是这篇文章提到一个问题,节点级别和边级别的变化在时间线上通常不是均匀的,即一段时间可能会频繁修改,而其他时间交互较为稀疏。这些交互的时间间隔是很重要的,原因有二,
一、特定节点之间交互的时间间隔会影响我们更新节点信息的策略,例如,如果一个新的交互与之前的交互相距较远,我们应该更多地关注新的交互,因为节点属性可能会发生变化。
二,新的交互不仅可以影响直接参与交互的两个节点,还可以影响“接近”这两个节点的其他节点;时间间隔会影响我们将交互信息传播到受影响节点的策略。例如,如果新交互距离节点和受影响节点之间的最新交互较远,则新交互对受影响节点的影响可能很小。
接着提出本文解决的三个问题
1)如何在新的交互发生时不断更新节点信息;
2) 如何将交互信息传播到受影响的节点;
3)如何在更新和传播过程中整合交互之间的时间间隔。
本文的贡献
我们提供了一种在引入新边时节点信息更新和传播的方法;
我们提出了一种新的动态图的图神经网络(DGNN),该模型将边的顺序和时间间隔建立为一个连贯的框架
我们用几个与图形相关的任务在各种真实动态图形上证明了所提出模型的有效性
首先定义了两个组件和两种点
交互点 、受影响的点(在文中为交互点的一阶邻居)
更新组件、传播组件
解释如下
交互点 : 例如({ v_2,v_5,t_7 })的交互下,交互点为({ v_2,v_5 })。
受影响的点:例如({ v_2,v_5,t_7 })的交互下,为交互点({ v_2,v_5 })的一阶邻居,即受影响的点为({ v_1,v_3,v_6,v_7 })。
更新组件:负责更新交互点,如图一中({ v_2,v_5,t_7 })的交互,更新组件负责将交互信息更新到({ v_2,v_5 })。
传播组件:负责将信交互信息传播到受影响的点和交互点,如图一中({ v_2,v_5,t_7 })的交互,传播组件负责将交互信息更新到交互点({ v_2,v_5 })。及受影响点({ v_1,v_3,v_6,v_7 })。
在更新组件中有三种单元:交互单元(Interact Unit),更新单元(Update Unit),合并单元(Merge Unit)。
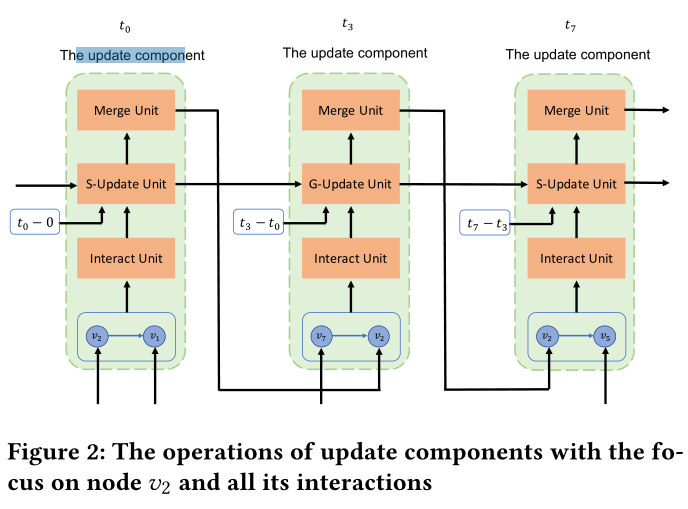
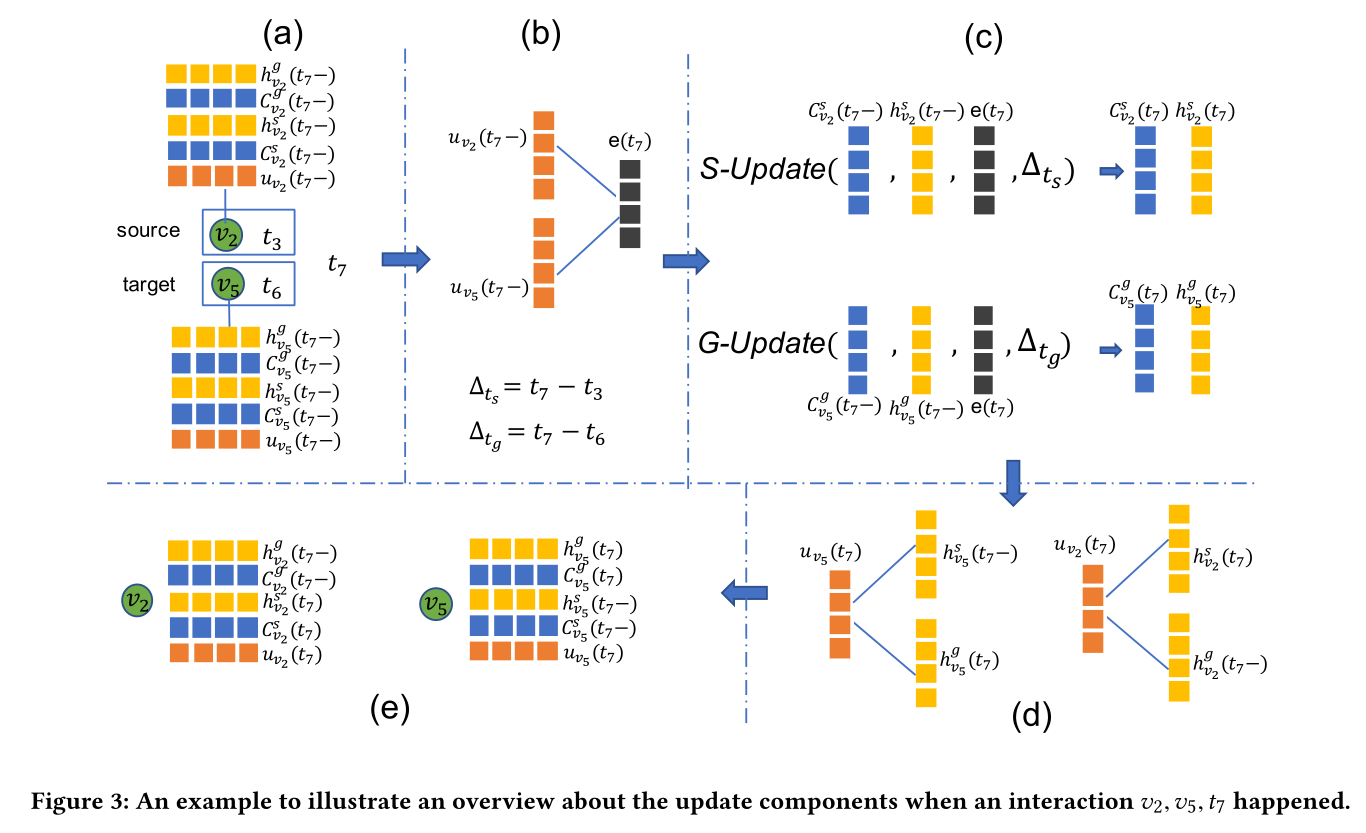
以下所有单元均用图2和图3做解释,交互为({ v_2,v_5,t_7 })。图3中的
每个节点v储存着五种信息,所有信息的符号解释如下
其中
(C)表示为单元记忆存储(cell memory)
(h)表示为隐藏层状态(hidden state)
(u)表示为该节点的一般特征(general feature)
上标(g)表示为该节点作为目标节点(target role of node)
上标(s)表示为该节点作为源节点(source role of node)
下标(v_i)表示节点编号
((t_i-))表示接近(t_i)时刻,但是没有到达
((t_i))表示在(t_i)时刻
举例(h_{v_2}^g(t_7))表示为:在(t_7)时刻时,节点(v_2)作为目标节点的隐藏层状态
举例(C_{v_5}^s(t_7-))表示为:在接近(t_7)时刻时,节点(v_5)作为源节点的单元记忆储存
举例(u_{v_2}(t_7))表示为:在(t_7)时刻时,节点(v_2)的一般特征
如图3的(b)所示,交互单元将(u_{v_2}(t_7-))和(u_{v_5}(t_7-))作为输入,输出的(e(t_7))中包含交互({ v_2,v_5,t_7 })的信息,具体计算公式如下:
(W_1,W_2,b_e)是神经网络可训练的参数,act(·)是激活函数例如sigmoid或者tanh
并在此计算两个时间差(∆_{t_s}=t_7-t_3,∆_{t_g}=t_7-t_6),在上文的introduction里有介绍,该模型考虑了如何将时间间隔信息整合到模型中,这两个时间差将会在下文的更新组件中作为输入
如图3的(c)所示,更新单元分为两种S-Update和G-Update,是为了处理当节点作为不同的角色(源节点或目标节点)时的区别
S-Update将此次交互({ v_2,v_5,t_7 })的源节点(v_2)在((t_7-))时刻相关的状态(h_{v_2}^s(t_7-),C_{v_2}^s(t_7-)),包含交互信息的(e(t_7)),还有该节点时间间隔(∆_{t_s})作为输入,输出为在((t_7))时刻的更新状态(h_{v_2}^s(t_7),C_{v_2}^s(t_7))
同理,G-Update更新目标节点(v_7)的相关状态
S-Update和G-Update的具体结构是一个LSTM的变种,这里先简单提一下LSTM模型:
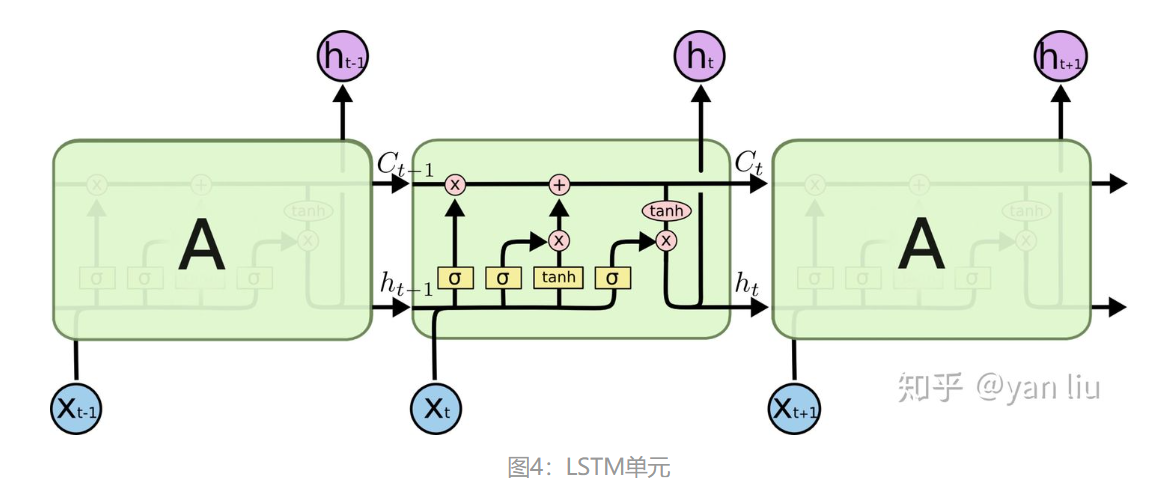
LSTM分成了三个部分
哪些细胞状态应该被遗忘(遗忘门)
哪些新的状态应该被加入(输入门/更新门)
根据当前的状态和现在的输入,输出应该是什么(输出门
具体的可以看https://zhuanlan.zhihu.com/p/421339475有介绍
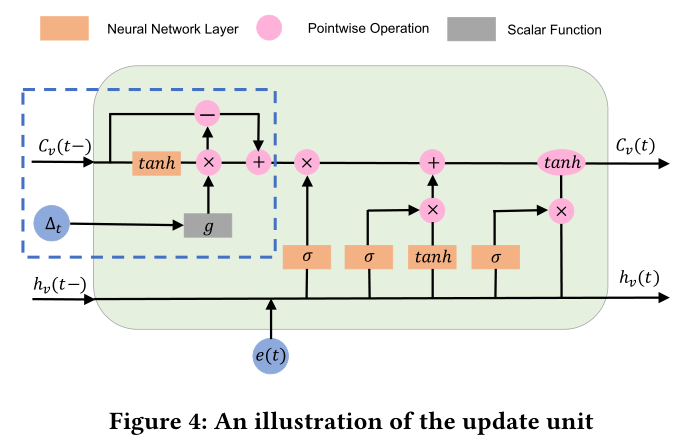
到这篇文章里,作者将LSTM改动了一下,主要是(C_{t-1})的输入加上了时间间隔信息,就是蓝色虚线框中的内容,
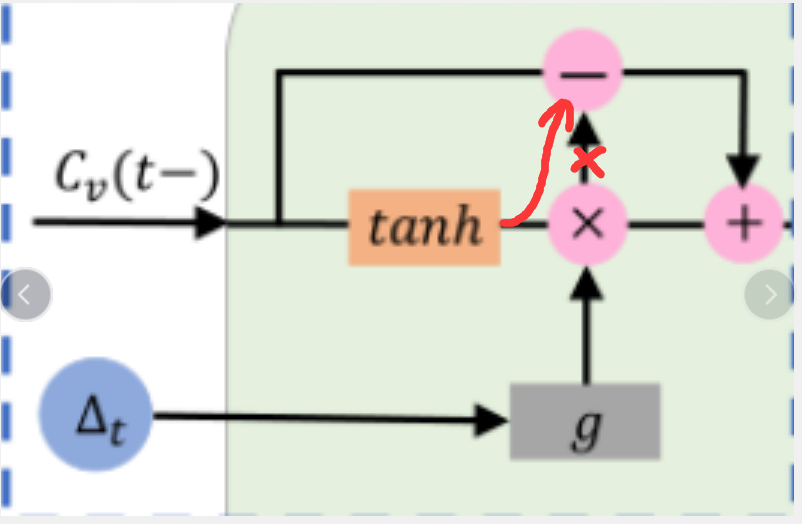
个人认为这里图有问题,有一定歧义,修正后图如下
具体公式如下
这个模块的主要作用是(C_{t-1})的输入加上了时间间隔信息。首先将模块分为两个部分,短期记忆部分(C^I_v(t− 1))和长期记忆部分(C^T_v (t− 1))。其中短期记忆部分由神经网络生成,长期记忆网络为(C^T_v (t− 1) = C_v (t− 1)− C^I_v (t − 1))
长期记忆保持不变,而短期记忆则根据两个相邻交互的时间间隔∆t被遗忘,具体遗忘函数为(g)。(g)是一个递减函数,这意味着时间间隔越大,保持的短期记忆越少。
接着结合长期记忆和短期记忆调整单元记忆(C^∗_v (t− 1) = C^T_v (t− 1) +hat{C^I_v} (t− 1)),最后以(C^∗_v (t− 1))作为单元记忆输入到LSTM中。剩下的公式和LSTM一样(手打公式吧 图片不好看)
缩写为(C_v(t), h_v (t) = Update(C_v (t− 1), h_v (t− 1),∆_t , e(t)))
注意:S-Update只处理这次交互的源节点,G-Update只处理这次交互的目标节点
如图3(d)所示,该单元将交互({ v_2,v_5,t_7 })经过更新后的信息(h_{v_2}^s(t_7),h_{v_5}^g(t_7))和先前该节点未更新且对应的信息合并为一般特征(u_{v_2}(t_7),u_{v_5}(t_7))
合并过程由神经网络完成
作者做了假设:
1:由于交互不会直接影响受影响的节点,我们假设交互不会干扰受影响节点的历史,只会带来新的信息。因此,我们不需要像在更新组件中那样衰减或减少历史信息(单元内存),而只需要增量地向其添加新信息。
2:与较早的交互应该对最近的节点信息影响较小的直觉类似,交互应该对较早的受影响节点影响较小。因此,还需要考虑传播分量中相互作用的时间间隔。此外,由于不同的连接强度,影响可能会有所不同。节点可能会影响其他具有强关系的人,而不是弱关系的人。因此,考虑异质性影响是很重要的。
传播组件中包含三个单元,交互单元、传播单元、合并单元,和上面的更新单元只有传播单元的区别,所以这里主要介绍传播单元,具体传播流程如下
符号说明(重复符号不再说明)
(N(v_s))表示源节点(v_s)所影响的邻居;例如节点(v_2)影响的邻居为(v_2)的一跳邻居({v_1,v_7})(除开交互包含点(v_7))
(N(v_g))表示源节点(v_s)所影响的邻居;例如节点(v_7)影响的邻居为(v_2)的一跳邻居({v_3,v_6})(除开交互包含点(v_2))
(∆^s_t = t−t_x)指节点(v_x)与源节点(v_s)交互时,当前时间(t)和最后交互时间(t_x)之间的间隔
(g(∆_t^s))和上面更新组件相似,是一个衰减函数
(h(∆_t^s))是为了限制交互时间间隔非常长的邻居(原文:extremely
old neighbors),自觉上来看,如果将信息传播给这些邻居,将会引入噪声。因此,引入一个函数(h(∆_t^s))过滤一些“受影响节点”,定义如下:
其中(tau)是一个预定义的阈值。
(hat{W_s^s})表示一个变换矩阵(神经网络训练参数)
(f_a (u_{v_x} (t_x−), u_{v_s} (t−)))这是一个注意力函数,用来捕获两节点之间的连接强度关系,具体函数如下(softmax):
传播单元的具体公式:
传播单元的过程在图5(c)中
这节将介绍DGNN的参数学习过程,如何使用DGNN进行链路预测以及节点分类
在DGNN中每个节点有一组一般特征,但是在链路预测中每个节点有两个不同的角色,于是引入两个投影矩阵(P^g,P^s),这两个矩阵负责将一般特征投影为对应角色的特征。对于一组交互((v_s , v_g, t)),将最近的一般特征(u_{v_s}(t-),u_{v_g}(t-))投影为(u_{v_s}^s(t-),u_{v_g}^s(t-)),具体如下
从(v_s)到(v_g)的概率被建模为(sigma(u_{v_s}^s(t-)^Tu_{v_g}^g(t-))),其中(sigma(cdot))是sigmoid,
损失函数如下:
个人认为损失函数有问题,已经发邮件给作者询问了,如果有知道的大佬可以指导一下,我的推导过程如下
在后面负采样的地方作者少了一个负号,即对比如下
在网上没看见有人说这问题,所以这里请有看过的大佬讨教一下
说回正题,每一次交互计算这样的一次损失,所有损失求和
节点分类使用了多分类的交叉熵函数,符号解释如下
(y in {0,1}^{N_c})表示为类型(y)取值为0,1
上标(N_c)表示为分类种类的数量
(u_v^c(t) in R^{N_c})是吧原来的一般特征$ u_v(t)(进行一个投影,映射得到)N_c$维度上,每个维度是一种特征。
损失如下
可以看到就是ce+softmax的结合
在训练中可以并不是所有节点都有标签 所以是一个半监督的任务。在进行传播和更新的时候,所有节点都参与。在经过所有的交互序列后,将所有和交互相关的点(V_m)取出来,(V_{train})表示为所有有节点的标签,则(V_{m-train}=V_m bigcap V_{train})
总损失如下
其中(T_m)为mini-batch中的最后一个交互
在这一节中介绍了数据集和两个基于图的任务(链接预测和节点分类)
三个数据集参数见表一
UCI:有向图,表示加利福尼亚大学欧文分校学生在线社区用户之间的消息通信。
DNC:有向图,这是2016年民主党全国委员会电子邮件泄漏事件中电子邮件通信的。
Epinions:有向图,表示产品审查平台Epinions中用户之间的信任关系。
GCN:traditional dynamic network embedding method
GraphSage: Inductive representation learning on large graphs
node2vec: Scalable feature learning for networks.
DynGEM:Deep Embedding Method for Dynamic Graphs.
CPTM:Temporal link prediction using matrix and tensor factorizations.
DANE:Dynamic Network Embedding by Modeling Triadic Closure Process.
DynamicTriad:Dynamic Network Embedding by Modeling Triadic Closure Process.
图神经网络GCN,GraphSage
节点嵌入node2vec
最近的动态图嵌入方法DynGEM, DANE, DynamicTriad
传统的方法CPTM
在链接预测中,使用一小部分交互最为历史,并预测未来会出现哪些新的边缘
训练集 验证集 测试集比例:8/1/1
对于在测试集里的每个交互边((v_s,v_g,t)),固定节点(v_s),使用图中所有节点去替换(v_g),然后用余弦相似度进行相似度排序。再反过来,固定节点(v_g),同所有节点替换(v_s)计算相似度排名
MRR(平均倒数排名)
Recall@k
见表2
作者提出了几个观察
1 DANE的表现不如预期,因为它最初是为属性网络(attributed networks)设计的。
2 DynGEM和DynamicTriad的表现都优于node2vec.这三种方法都是嵌入算法——node2vec用于静态网络,而DynGEM和DynamicTriad用于捕获动态。这些结果表明了图形中动态信息的重要性。
3 所提出的动态图神经网络模型优于现有的两个有代表性的GNN,即GCN和GraphSage。我们的模型是针对动态网络的,而GCN和GraphSage忽略了动态信息,这进一步支持了捕捉动态的重要性。
GCN,GraphSage
LP:Semi-supervised learning using gaussian fields and harmonic functions.
在节点分类任务中,随机抽取一部分节点并隐藏它们的标签。这些隐藏标签的节点将被视为验证和测试集。其余节点被视为训练集。
训练集 验证集 测试集比例:8/1/1
但是对于训练集的80%,会选择x%作为标记节点(x in { 100,80,60 })
见图5
同样作者提出了观察
1 随着标记节点数量的增加,分类性能趋于提高。
2 GraphSage、GCN和DGNN在所有设置下都优于LP,这表明GNN在半监督学习中的威力。
3 DGNN在所有三种设置下都优于GraphSage和GCN,这表明了时间信息在节点分类中的重要性。
这部分研究了关键组件对提出模型的影响,于是做了如下三个变体
DGNN-prop:在这个变体中,从模型中删除了整个传播组件。此变体仅在出现新边时执行更新过程。
DGNN-ti:在这个变体中,不在更新组件和传播组件中使用时间间隔信息。因此,将交互视为一个没有时间信息的序列。
DGNN-att:在这个变体中,我们移除了传播组件中的注意机制,并考虑了同等的影响。
效果见表3
于是作者得出三个结论
1 有必要将交互信息传播到受影响的节点;
2 重要的是要考虑时间间隔信息;
3 捕捉各种影响可以提高性能。
在传播组件中有一个过滤函数(h(∆_t^s)),这节将讨论函数的条件$∆_t^s leq tau (中的)tau$取值对模型的影响
效果见图7
于是作者得出三个结论
1 传播过程确实有助于向“受影响节点”传递必要的信息,因为当阈值增加时,性能首先得到改善
2 将交互信息传播给“非常老的邻居”可能没有帮助,甚至可能带来噪音
综上,只需要使用少量“受影响节点”来执行传播,这样不仅提高效率,而且模型性能也更好
这篇文章更有GNN的影子,以消息传递作为核心机制,提出了传播组件和更新组件,但是处理时序信息的结构是LSTM,我认为这样就会导致模型串行化,优化变得非常困难。同时作者在最后也提出关于过滤函数阈值的取值问题,作者发现将交互信息传递到距离较远的节点可能没有帮助,这类似GCN盲目堆叠层数效果并不会变好,整篇文章写作逻辑紧密,读下来更清楚了该怎么写一篇模型算法的论文
评论已关闭。




![洛谷 P11345 [KTSC 2023 R2] 基地简化 题解](http://www.itfaba.com/wp-content/themes/kemi/timthumb.php?src=http://www.itfaba.com/wp-content/themes/kemi/img/random/1.jpg&w=218&h=124&zc=1)
