
有了《系统架构的11条原则》,真正到设计阶段还有另外11个考虑。
系统正确性
考虑一:负负得正
假如我们看到某个代码,明显有逻辑错误,想随手改改。你就要考虑一件事情:这段明显有问题的代码为什么在线上运行着没有人来报bug?有一种正常运行叫做【负负得正】。如果把错误的逻辑改对了反而可能引起问题。
这种问题要避免最好的时机是初版设计和开发阶段就避免。除了设计阶段逻辑要清晰,代码要做好审查、加上单体测试等测试手段外,可以将中间结果用debug日志打印。建议自测阶段多用debug级别日志跑几遍,进行观察。
考虑二:终态设计
在分布式系统中,由于系统是分布在不同机器上的。还可能有一种状态叫:超时。成功、失败和超时是分布式系统调用的三态。

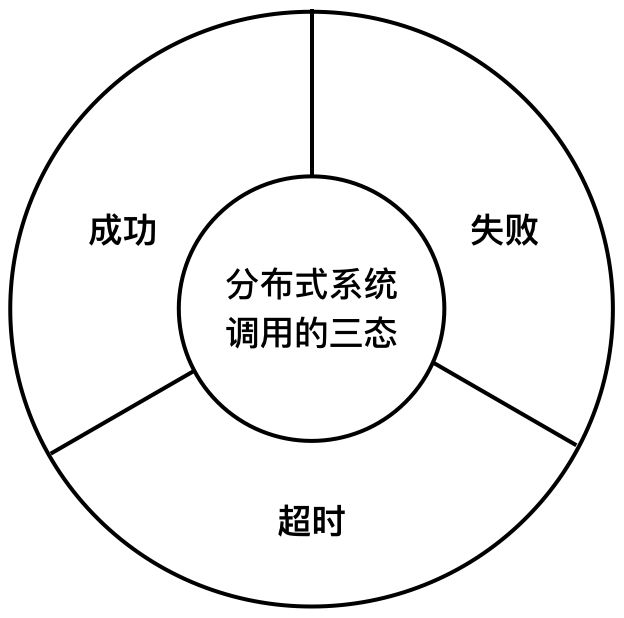
超时不是终态,而是一种中间状态:最终有可能下游是成功了,也有可能是失败了。这时候我们需要在超时之后推定一种状态,推定成功或者失败。究竟是成功还是失败因功能而异。
比如付款操作,需要推定失败。如果不知道是否成功就推定是成功的,那用户可能没有付款就拿到了商品或者享受了服务,商家就会资金损失。推定失败让用户再次支付,最终通过查询或者对账发现用户实际是支付成功的,可以再把钱给用户退回去,保证交易的公平性。
退款恰恰相反,需要推定成功。告诉用户,钱退给你了。最终通过查询或者对账发现实际是退款失败了,可以系统重新发起退款,直到真正退成功为止。
后台管理系统也很需要这种终态设计。比如发布系统,发布了一个功能,发布系统如果出现了问题,这次发布没有结束。用户可能没有办法进行下一次发布。这时候可以设置超时自动结束,防止未结束的流程始终在那里。
考虑三:长尾效应
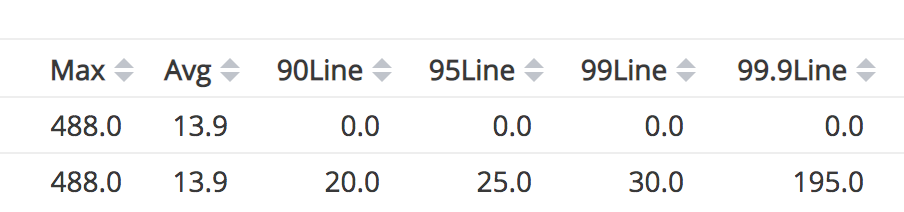
如上图,随便找了一个调用的耗时。从上面可以看到平均耗时13.9ms,百分之99的耗时在30ms内,最大耗时有488ms。那对于超过100ms的请求来说,是不是在30ms内还不返回就直接丢弃这个请求重新发起一个,新请求有99%的概率在30ms内返回结果,从时间上更划算?
而之所以对同一个请求性能差距很大,原因很多,常见的有服务过载和队列过长。如果长尾处理不好,有可能上游判定超时,导致请求失败,影响正确性。需要系统处理好超时和重试。
系统容量
考虑四:存储周期
数据库、应用系统的磁盘都是宝贵的资源。数据不能无限期存储不做清理。清理的周期是一个重要的考虑方面。因为这涉及对用户的承诺。
对数据库来说,比如交易库数据半年清理一次。那就要跟用户说清楚半年以上的交易不允许退款。因为原交易已经不在数据库,而是归档到大数据了。
对磁盘来说,如果应用日志是30天清理一次。那就要跟用户达成一致,非重大问题30天以上的不予追溯。为什么这里说重大问题呢,其实很多公司磁盘清理了,数据在hbase等大数据设备里还是有留存的。只是查询没有磁盘日志便利。
考虑五:AKF扩展
AKF扩展立方体(Scalability Cube),是《架构即未来》一书中提出的可扩展模型,这个立方体有三个轴线,每个轴线描述扩展性的一个维度:
X轴 —— 代表无差别的克隆服务和数据,工作可以很均匀的分散在不同的服务实例上;
Y轴 —— 关注应用中职责的划分,比如数据类型,交易执行类型的划分;
Z轴 —— 关注服务和数据的优先级划分,如分地域划分。
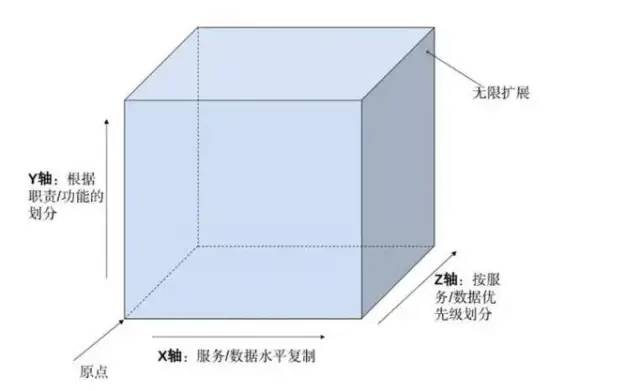
白话来说:X轴拆分就是通过加机器水平拆分,就是横向扩展;Y轴拆分就是按业务逻辑垂直拆分;Z轴拆分就是按照算法进行分片,这个算法比如按地域,不同地域访问不同的分片或者服务。
举个例子,比如一般公司的redis集群会有一个团队来进行统一维护。redis集群有主有从,数据都是一样的,多副本容灾,这是X轴水平的拆分。一个公司很多业务,redis团队会对不同的业务提供不同的集群,这是Y轴垂直拆分;集群内部数据会通过sharding做分片,这是Z轴算法拆分。
系统运维
考虑六:服务自治
当一个服务的逻辑单元由自身的领域边界内所控制,不受其他外界条件的影响(外界条件带有不可预测性),且运行环境是自身可控,完全自给自足,我们认为这个服务是自治的。
在系统设计时,要考虑服务上线后,对于问题要自感知、自修复、自优化、自运维及自安全。
考虑七:应急预案
SOP(Standard Operating Procedure三个单词中首字母的大写 )即标准作业程序,就是将某一事件的标准操作步骤和要求以统一的格式描述出来,用来指导和规范日常的工作。
EOP(Emergency Operating Procedure三个单词中首字母的大写 )即应急操作流程,用于规范应急操作过程中的流程及操作步骤。确保人员可以迅速启动,确保有序、有效地组织实施各项应对措施。
这两种操作流程需要平时就整理好,避免紧急情况下思虑不周导致操作时的二次故障。
考虑八:故障隔离
隔离是行之有效的故障规避措施。有以下隔离手段。
领域拆分隔离方面
提炼核心、支撑和通用域
服务部署隔离方面
环境拆分
机房隔离
通道隔离
单元化
泳道
热点隔离
读写隔离
容器隔离
拆库拆表
动静隔离
非核心流量隔离
服务间交互隔离方面
考虑九:风险巡检
核心系统稳定之后,更多的从边缘进行优化,避免影响核心系统的稳定。风险巡检是优化的重要方面。常见的有以下内容。
请求系统错误统计
请求业务错误统计
请求内部错误统计
慢查询统计巡检
数据一致性巡检
流程执行情况巡检
审计和安全
考虑十:合法合规
合法合规是企业生死存亡的大事。近年来,由于政策影响,很多教育机构面临了巨大的危机甚至倒闭。
对于金融类企业,太多合规操作。比如:行业要求金融交易类系统不能与其他系统混合部署;平台没有清结算资质可能面临二清问题。提到资质,不得不说说金融牌照。在我国,需要审批的金融牌照主要包括银行、信托、保险、券商、期货、基金、基金子公司、基金销售、金融租赁、小额贷款、第三方支付牌照、典当12种。业务的牌照要对口。
考虑十一:严格准入
做需求有个常识,对于用户输入的每个字段都需要和产品经理讨论一下:什么类型、长度多少、允许的字符集范围、格式是否合法。这么做一方面是设计问题,包括产品设计、数据库设计,还有一部分是安全问题:一个数值型的字段肯定比一个粗放的文本型字段被攻击的可能性小,起码不会传到后端之后被当成脚本被执行。
操作合理性准入也是考虑的重要方面。比如一个普通用户不能编辑另一个用户的个人信息。比如i申请公司服务器,一次申请1万台机器。比如流量准入,一台机器以超快的速度频繁访问一个网站的资讯信息,就可能不是真实用户操作而是爬虫。以上都会对系统安全性产生极大的影响。
总结
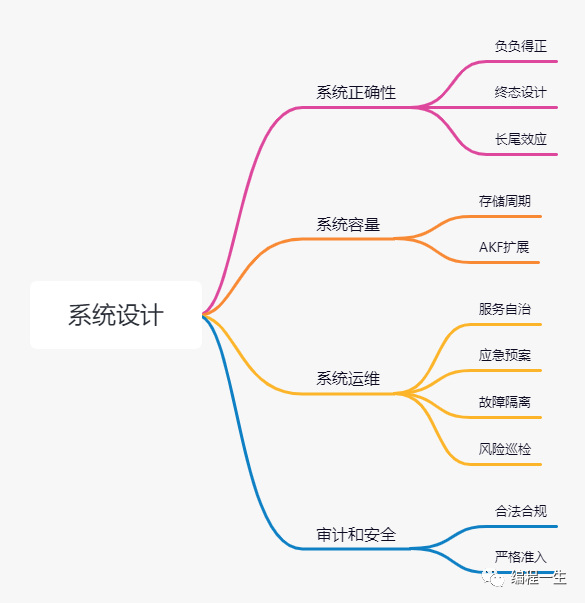
一张图总结今天的内容:
评论已关闭。




